serverless rag ynetnews bedrock demo
1.0.0
问答 (QA) 是一项重要任务,涉及提取以自然语言提出的事实查询的答案。通常,QA 系统会处理针对包含结构化或非结构化数据的知识库的查询,并生成包含准确信息的响应。确保高精度是开发有用、可靠且值得信赖的问答系统的关键,特别是对于企业用例。
Amazon Titan、Anthropic Claude 和 AI21 Jurassic 2 等生成式 AI 模型使用概率分布来生成对问题的回答。这些模型经过大量文本数据的训练,这使它们能够预测序列中接下来会发生什么,或者特定单词后面可能会出现什么单词。然而,这些模型无法为每个问题提供准确或确定性的答案,因为数据中总是存在一定程度的不确定性。
企业需要查询特定领域和专有数据,并使用这些信息来回答问题,更普遍的是,还需要查询尚未训练模型的数据。
在此存储库中,我们将探索以下 QA 模式:
我们使用检索增强生成,它改进了第一个,我们将问题与尽可能多的相关上下文连接起来,这可能包含我们正在寻找的答案或信息。这里的挑战是,可以使用多少上下文信息是有限制的,这是由模型的令牌限制决定的。 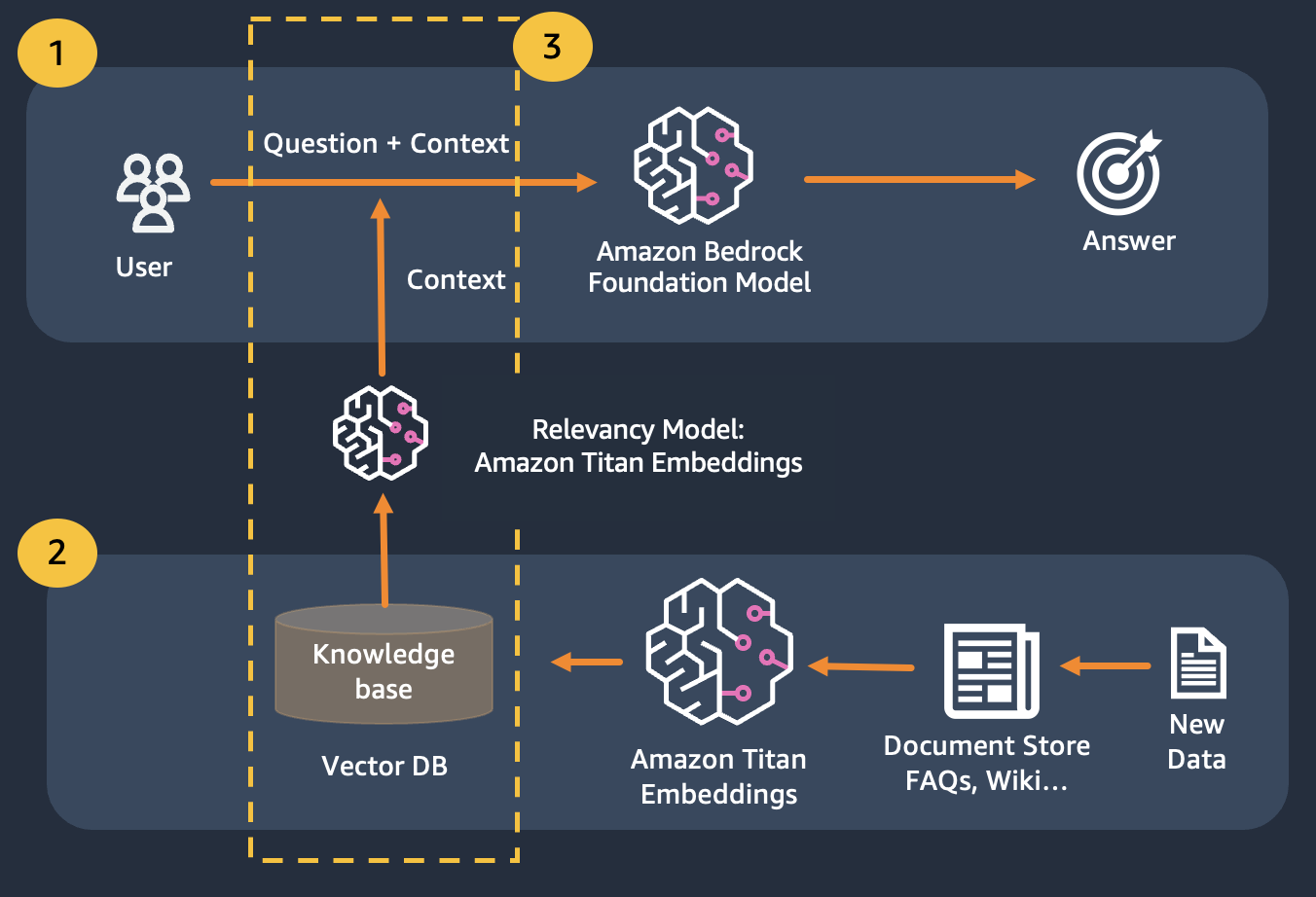
这可以通过使用检索增强生成 (RAG) 来克服
RAG 结合使用嵌入来索引文档语料库以构建知识库,并使用 LLM 从知识库中的文档子集提取信息。
作为 RAG 的准备步骤,构建知识库的文档被分割成固定大小的块(与所选嵌入模型的最大输入大小匹配),然后传递给模型以获得嵌入向量。嵌入与文档的原始块和附加元数据一起存储在矢量数据库中。矢量数据库经过优化,可以有效地执行矢量之间的相似性搜索。
拥有可能是私有的或经常变化的数据存储的客户。 RAG 方法解决了 2 个问题,面临以下挑战的客户可以从该实验室中受益。
学完本模块后,您应该对以下内容有一个很好的理解:
在本模块中,我们将引导您了解如何使用 Bedrock 实施 QA 模式。此外,我们还为您准备了要加载到矢量数据库中的嵌入。
请注意,您可以使用 Titan Embeddings 获取用户问题的嵌入,然后使用这些嵌入从向量数据库中检索最相关的文档,构建一个连接前 3 个文档的提示,并通过 Bedrock 调用 LLM 模型。


