BeatLearning
1.0.0
您是否曾经想演奏一首您最喜欢的节奏游戏中没有的歌曲?你有没有想过演奏那首歌的无限变体?
这个开源研究项目旨在使自动节奏图创建过程民主化,为游戏开发者、玩家和爱好者等提供易于使用的工具和基础模型,为节奏游戏创造力和创新的新时代铺平道路。
示例(更多示例即将推出):
您首先需要安装 Python 3.12,进入存储库目录并通过以下方式创建虚拟环境:
python3 -m venv venv
然后调用source venv/bin/activate或venvScriptsactivate如果您使用的是 Windows 计算机)。激活虚拟环境后,您可以通过以下方式安装所需的库:
pip3 install -r requirements.txt
您可以使用 Jupyter 访问示例notebooks/ :
jupyter notebook
您也可以尝试 Google Collab 版本,只要您有可用的 GPU 实例(默认的 CPU 实例需要很长时间才能转换歌曲)。
该管道目前仅支持 OSU 节奏图。
该存储库仍在进行中。目标是开发能够自动为各种节奏游戏生成节拍图的生成模型,无论歌曲是什么。这项研究仍在进行中,但目标是尽快获得 MVP。
所有贡献都受到重视,尤其是用于训练基础模型的计算捐赠形式。所以,如果你有兴趣,就赶快来参与吧!
与我们一起探索人工智能驱动的节奏图生成的无限可能性,塑造节奏游戏的未来!
模型可在 HuggingFace 上找到。
节奏游戏节拍图最初被转换为中间文件格式,然后被标记为 100 毫秒的块。每个令牌能够在该时间段内编码最多两个不同的事件(保持和/或点击),量化至 10 毫秒的精度。分词器的词汇是预先计算的,而不是从数据中学习来满足此标准。由于该领域缺乏高质量的训练示例,上下文长度和词汇量有意保持较小。
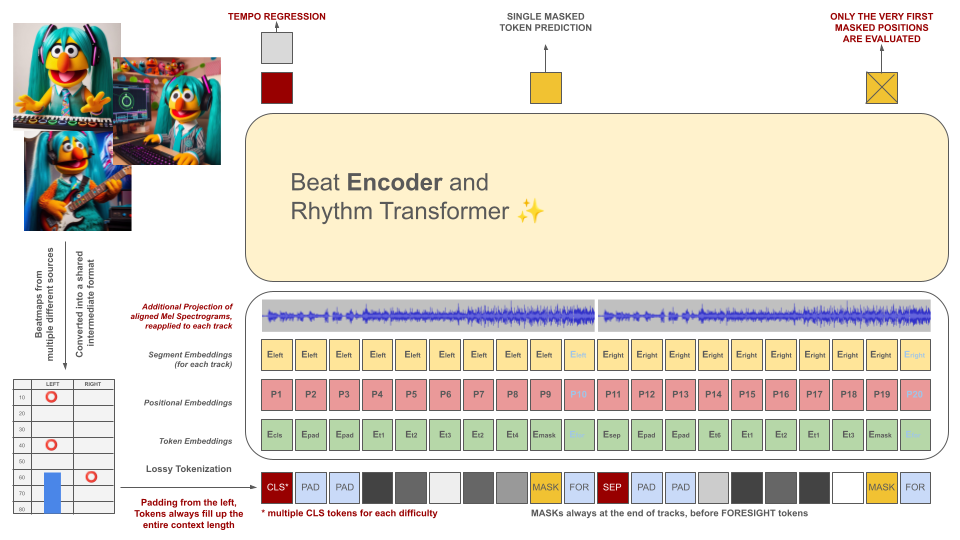 这些标记以及音频数据片段(其投影的梅尔声谱图与标记对齐)用作屏蔽编码器模型的输入。与 BeRT 类似,编码器模型在训练期间有两个目标:通过回归任务估计节奏,并通过听力损失函数预测屏蔽(下一个)标记。支持具有 1、2 和 4 个轨道的节拍图。每个令牌都是从左到右预测的,反映了解码器架构的生成过程。然而,被屏蔽的令牌还可以访问来自未来的附加音频信息,从右侧表示为前瞻令牌。
这些标记以及音频数据片段(其投影的梅尔声谱图与标记对齐)用作屏蔽编码器模型的输入。与 BeRT 类似,编码器模型在训练期间有两个目标:通过回归任务估计节奏,并通过听力损失函数预测屏蔽(下一个)标记。支持具有 1、2 和 4 个轨道的节拍图。每个令牌都是从左到右预测的,反映了解码器架构的生成过程。然而,被屏蔽的令牌还可以访问来自未来的附加音频信息,从右侧表示为前瞻令牌。
AI 模型的目的不是贬低单独制作的节拍图,而是:
所有生成的内容必须符合欧盟法规并适当标记,包括表明人工智能模型参与的元数据。
严格禁止为受版权保护的材料生成节奏图!仅使用您拥有权利的歌曲!
OSU 文件示例中的音频来自 OSU 网站上“特色艺术家”部分列出的艺术家,并获得专门在 osu! 相关内容中使用的许可。
为了防止您的节拍图将来被用作训练数据,请在您的节拍图文件中包含以下元数据:
robots: disallow
该项目的灵感来自于之前的 AIOSU 尝试。
除了依赖 OSU 的 wiki 之外,osu-parser 在澄清 Beatmap 声明(尤其是滑块)方面也发挥了重要作用。 Transformer 模型受到 NanoGPT 和 BeRT 的 pytorch 实现的影响。


