stellar metrics
1.0.0
我们论文的代码:Stellar:以人为中心的个性化文本到图像方法的系统评估
作者:帕诺斯·阿赫利奥塔斯、亚历山德罗斯·贝内塔托斯、约丹尼斯·福斯蒂罗普洛斯、迪米特里斯·斯科尔蒂斯
该代码库由 Iordanis Fostiropoulos 维护。如有任何疑问,请联系我们。
在下载或使用此存储库中的代码的任何部分之前,请查看并确认此存储库中包含的“许可条款”和“第三方许可条款”中规定的条款和条件。继续下载和使用此存储库中的代码的任何部分即表示您同意这些条款和条件。
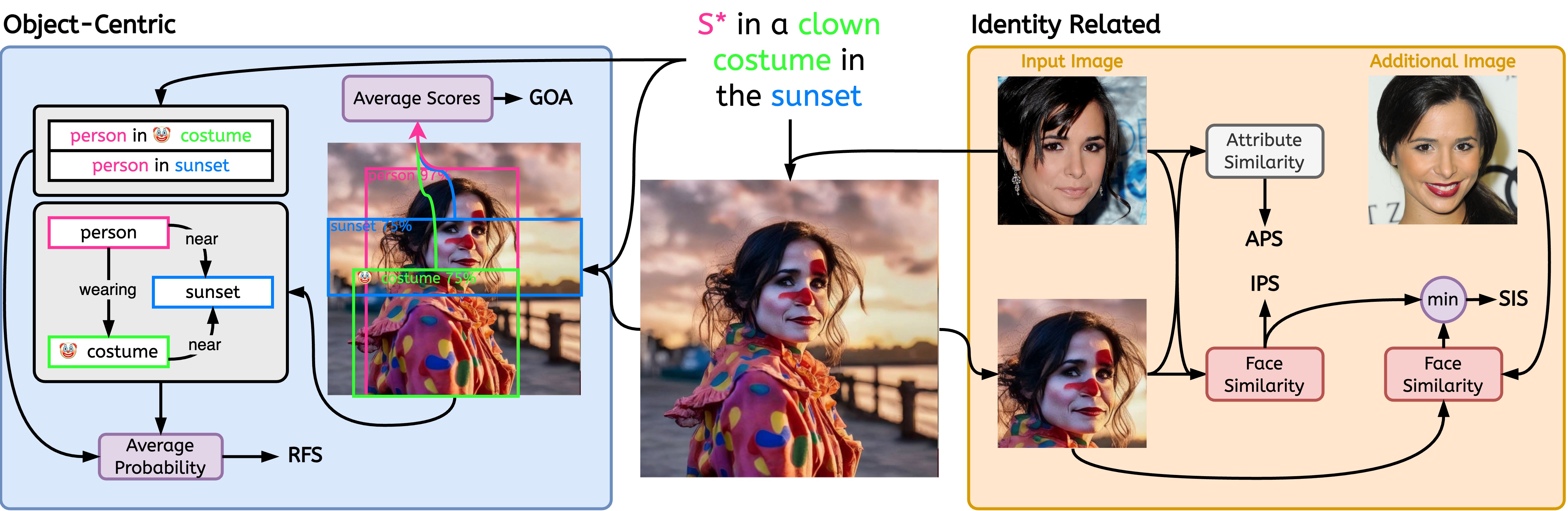 注意:显示的“输入图像”和“附加图像”可在 CELEBMaksHQ 数据集中找到。
注意:显示的“输入图像”和“附加图像”可在 CELEBMaksHQ 数据集中找到。
这项工作基于我们的技术手稿《Stellar:以人为中心的个性化文本到图像方法的系统评估》。我们提出了 5 个指标来评估以人为中心的个性化 Text-2-Image 模型。该存储库为 Text-2-Image 和 Image-2-Image 方法提供了 8 个附加基线指标的实现。
文献中提供了几个指标。我们用我们的工作中引入的那些来表示。
我们提供自己对现有指标的实现,并让用户参考他们的论文以了解其工作的技术细节。
| 姓名 | 评价类型 | 代码名称 | 参考 |
|---|---|---|---|
| 审美。 | 图像到图像 | aesth | 关联 |
| 图像到图像 | clip | 关联 | |
| 梦幻模拟 | 图像到图像 | dreamsim | 关联 |
| 文字转图像 | clip | 关联 | |
| HPSv1 | 文字转图像 | hps | 关联 |
| HPSv2 | 文字转图像 | hps | 关联 |
| 图像奖励 | 文字转图像 | im_reward | 关联 |
| 挑选分数 | 文字转图像 | pick | 关联 |
| APS | 个性化图文转换 | aps | 关联 |
| 阿富汗政府 | 以对象为中心 | goa | 关联 |
| IPS | 个性化图文转换 | ips | 关联 |
| 以关系为中心 | rfs | 关联 | |
| 安全信息系统 | 个性化图文转换 | sis | 关联 |
pip install git+https://github.com/stellar-gen-ai/stellar-metrics.git我们想要计算每个单独图像的度量。因此,它可以帮助诊断方法的失败案例。
$ python -m stellar_metrics --metric code_name --stellar-path ./stellar-dataset --syn-path ./model-output --save-dir ./save-dir您可以选择为主干指定--device 、 --batch-size和--clip-version
注意模型输出和恒星数据集之间必须存在一对一的对应关系。 stellar-dataset用于计算一些指标,例如需要原始图像的身份保留。 syn-path和stellar-path之间的错误配置可能会导致错误的结果。
计算IPS
$ python -m stellar_metrics --metric ips --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir计算剪辑
$ python -m stellar_metrics --metric clip --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir$ python -m stellar_metrics.analysis --save-dir ./save-dir以相当粗略但专门的方式评估输入身份和生成的图像之间的面部相似性。我们的指标使用面部检测器来隔离输入图像和生成图像中的身份面部。然后,它采用专门的面部检测模型从检测到的区域中提取面部表征嵌入。
评估生成的图像如何很好地保持相关身份的特定细粒度属性,例如年龄、性别和其他不变的面部特征(例如,高颧骨)。利用恒星图像中的注释,我们可以评估这些二元面部特征。
作为确定模型对同一个人的不同图像的敏感程度的衡量标准;进一步推广模型,无论输入的图像不相关的变化(例如,照明条件、主体的姿势)如何,主体的身份都能被一致地捕捉到。
为了实现这一目标, SIS需要访问人类受试者的多张图像(Stellar 数据集的设计满足了这一条件);也是我们唯一一个要求如此苛刻的评价指标。
我们引入专门的、可解释的指标来评估图像和提示之间对齐的两个关键方面;对象表示的忠实性和所描绘的关系的保真度。
评估在生成的图像上表示所需的提示对象交互是否成功。考虑到即使是专门的场景图生成(SGG)模型也难以理解视觉关系,该指标引入了对个性化模型忠实描述提示关系的能力的有价值的局部洞察。


