BinaryVectorDB
1.0.0
该存储库包含一个二进制向量数据库,用于对大型数据集进行有效搜索,旨在用于教育目的。
大多数嵌入模型将其向量表示为 float32:它们会消耗大量内存,并且搜索速度非常慢。在 Cohere,我们引入了第一个具有本机 int8 和二进制支持的嵌入模型,它可以为您提供出色的搜索质量,而成本只需一小部分:
| 模型 | 搜索质量奇迹 | 搜索 100 万文档的时间 | 需要 250M 内存 维基百科嵌入 | AWS 上的价格(x2GB 实例) |
|---|---|---|---|---|
| OpenAI 文本嵌入-3-小 | 44.9 | 680毫秒 | 1431GB | $65,231 / 年 |
| OpenAI 文本嵌入-3-large | 54.9 | 1240 毫秒 | 2861GB | $130,463 / 年 |
| Cohere Embed v3(多语言) | ||||
| 嵌入 v3 - float32 | 66.3 | 460毫秒 | 954GB | $43,488 / 年 |
| 嵌入 v3 - 二进制 | 62.8 | 24 毫秒 | 30GB | $1,359 / 年 |
| 嵌入 v3 - 二进制 + int8 重新评分 | 66.3 | 28 毫秒 | 30GB内存+240GB磁盘 | $1,589 / 年 |
我们创建了一个演示,允许您在 100M 维基百科嵌入中搜索 VM,每月仅需 15 美元:演示 - 搜索 100M 维基百科嵌入,每月仅需 15 美元
您可以轻松地对自己的数据使用 BinaryVectorDB。
设置很简单:
pip install BinaryVectorDB
要使用下面的一些示例,您需要来自 cohere.com 的Cohere API 密钥(免费或付费)。您必须将此 API 密钥设置为环境变量: export COHERE_API_KEY=your_api_key
稍后我们将展示如何根据您自己的数据构建矢量数据库。首先,让我们使用预先构建的二进制向量数据库。我们在 https://huggingface.co/datasets/Cohere/BinaryVectorDB 上托管各种预构建数据库。您可以下载这些并在本地使用它们。
让我们从维基百科的简单英文版本开始:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
然后解压这个文件:
unzip wikipedia-2023-11-simple.zip
您可以通过将数据库指向上一步中解压的文件夹来轻松加载数据库:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )该数据库有 646,424 个嵌入,总大小为 962 MB。然而,内存中仅加载了 80 MB 的二进制嵌入。文档及其 int8 嵌入保存在磁盘上,仅在需要时加载。
内存中的二进制嵌入和磁盘上的 int8 嵌入和文档的这种分割使我们能够扩展到非常大的数据集,而不需要大量的内存。
构建您自己的二进制向量数据库非常容易。
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ])该文档可以是任何 Python 可序列化对象。您需要为docs2text提供一个函数,将文档映射到字符串。在上面的示例中,我们连接标题和文本字段。该字符串被发送到嵌入模型以生成所需的文本嵌入。
添加/删除/更新文档很容易。有关如何在数据库中添加/更新/删除文档的示例脚本,请参阅examples/add_update_delete.py。
我们发布了 Cohere int8 和二进制 Embeddings 嵌入,可将所需内存减少 4 倍和 32 倍。此外,它还能将矢量搜索速度提高 40 倍。
这两种技术都结合在 BinaryVectorDB 中。举个例子,我们假设英文维基百科有 42M 嵌入。正常的 float32 嵌入需要42*10^6*1024*4 = 160 GB内存来托管嵌入。由于 float32 上的搜索相当慢(在 42M 嵌入上大约需要 45 秒),我们需要添加像 HNSW 这样的索引,这会额外增加 20GB 内存,因此总共需要 180GB。
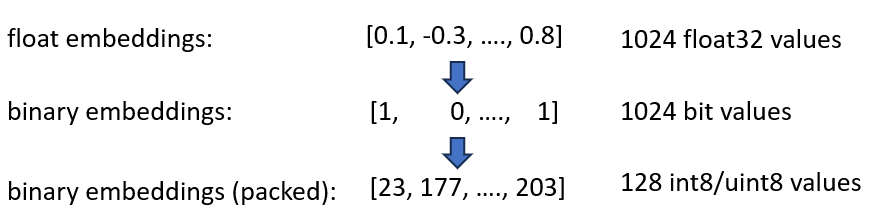
二进制嵌入将每个维度表示为 1 位。这将内存需求减少到160 GB / 32 = 5GB 。此外,由于二进制空间中的搜索速度提高了 40 倍,因此在许多情况下您不再需要 HNSW 索引。您将内存需求从 180 GB 减少到 5 GB,节省了 36 倍。
当我们查询该索引时,我们也以二进制形式对查询进行编码并使用汉明距离。汉明距离测量 2 个向量之间的 1 位差异。这是一个非常快的操作:要比较两个二进制向量,您只需要 2 个 CPU 周期: popcount(xor(vector1, vector2)) 。 XOR 是 CPU 上最基本的运算,因此运行速度非常快。 popcount统计寄存器中1的个数,同样只需要1个CPU周期。
总的来说,这为我们提供了一个保持大约 90% 搜索质量的解决方案。
我们可以通过<float, binary>重新评分将上一步的搜索质量从 90% 提高到 95%。
例如,我们获取步骤 1 中的前 100 个结果,并计算dot_product(query_float_embedding, 2*binary_doc_embedding-1) 。
假设我们的查询嵌入是[0.1, -0.3, 0.4] ,二进制文档嵌入是[1, 0, 1] 。该步骤然后计算:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

我们使用这些分数并对我们的结果重新评分。这将搜索质量从 90% 提高到 95%。这个操作可以非常快地完成:我们从嵌入模型中获取查询浮点嵌入,二进制嵌入在内存中,所以我们只需要进行 100 次求和运算。
为了进一步提高搜索质量,从 95% 提高到 99.99%,我们使用 int8 从磁盘重新评分。
我们将所有 int8 文档嵌入保存在磁盘上。然后,我们从上面的步骤中取出前 30 个,从磁盘加载 int8 嵌入,并计算cossim(query_float_embedding, int8_doc_embedding_from_disk)
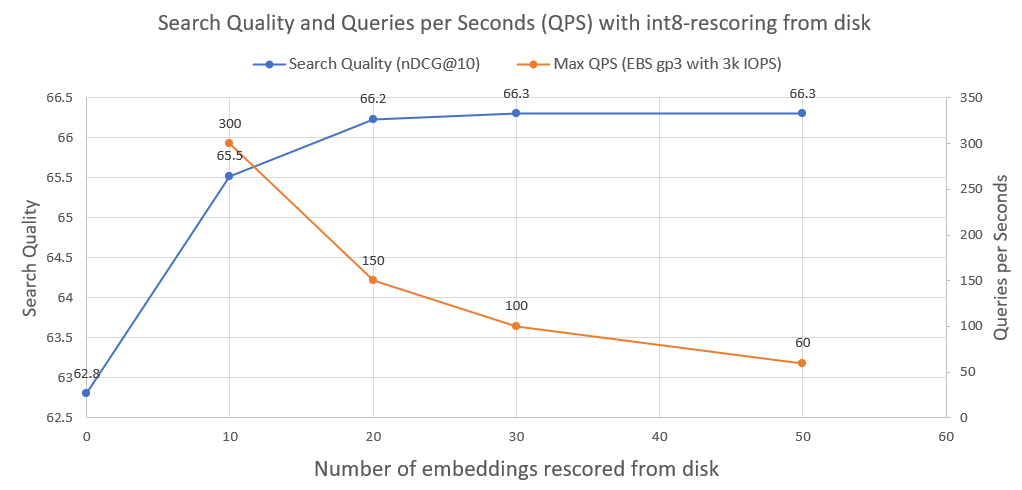
在下图中,您可以看到 int8-rescoring 的程度并提高了搜索性能:
我们还绘制了此类系统在普通 AWS EBS 网络驱动器上以 3000 IOPS 运行时可以实现的每秒查询数。正如我们所看到的,我们需要从磁盘加载的 int8 嵌入越多,QPS 就越少。
为了执行二分搜索,我们使用 faiss 的 IndexBinaryFlat 索引。它只存储二进制嵌入,允许超快速索引和超快速搜索。
为了存储文档和 int8 嵌入,我们使用 RocksDict,这是一种基于 RocksDB 的 Python 磁盘键值存储。
有关该类的完整实现,请参阅 BinaryVectorDB。
并不真地。该存储库主要用于教育目的,以展示如何扩展到大型数据集的技术。重点更多地放在易用性上,而在实现中缺少一些关键方面,例如多进程安全性、回滚等。
如果您确实想投入生产,请使用 Vespa.ai 等适当的矢量数据库,它可以让您获得类似的结果。
在 Cohere,我们帮助客户以极低的成本对数百亿个嵌入运行语义搜索。如果您需要可扩展的解决方案,请随时联系 Nils Reimers。


