VideoX
1.0.0
这是我们的视频理解作品合集
SeqTrack (
@CVPR'23): SeqTrack:视觉对象跟踪的序列到序列学习
X-CLIP (
@ECCV'22 Oral):扩展用于通用视频识别的语言图像预训练模型
MS-2D-TAN (
@TPAMI'21):使用自然语言进行矩定位的多尺度 2D 时间相邻网络
2D-TAN (
@AAAI'20):学习 2D 时态相邻网络,使用自然语言进行时刻定位
招聘具有较强编码能力的研究实习生:[email protected] | [email protected]
2023 年 4 月: SeqTrack代码现已发布。
2023 年 2 月: SeqTrack被 CVPR'23 接受
2022 年 9 月: X-CLIP现已集成到
2022 年 8 月: X-CLIP代码现已发布。
2022 年 7 月: X-CLIP作为 Oral 被 ECCV'22 接受
2021 年 10 月: MS-2D-TAN代码现已发布。
2021 年 9 月: MS-2D-TAN被 TPAMI'21 接受
2019 年 12 月: 2D-TAN代码现已发布。
2019年11月: 2D-TAN被AAAI'20接受
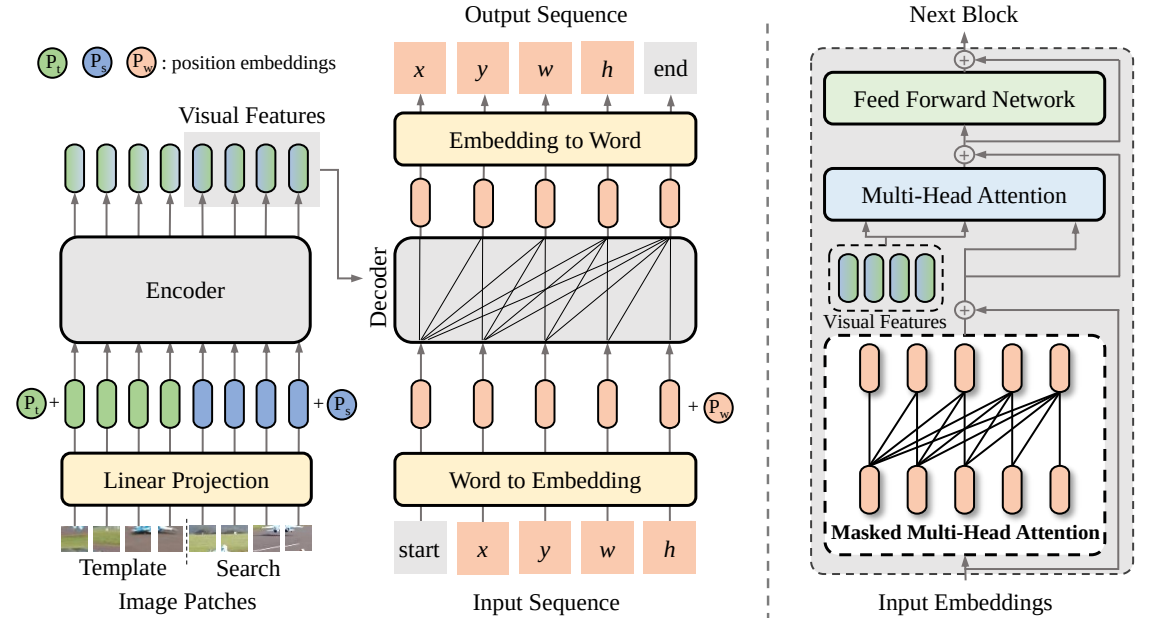
在本文中,我们提出了一种新的视觉跟踪序列到序列学习框架,称为 SeqTrack。它将视觉跟踪视为序列生成问题,以自回归方式预测对象边界框。 SeqTrack仅采用简单的编码器-解码器变压器架构。编码器使用双向变换器提取视觉特征,而解码器使用因果解码器自回归生成一系列边界框值。损失函数是一个简单的交叉熵。这种序列学习范式不仅简化了跟踪框架,而且在许多基准测试上实现了有竞争力的性能。
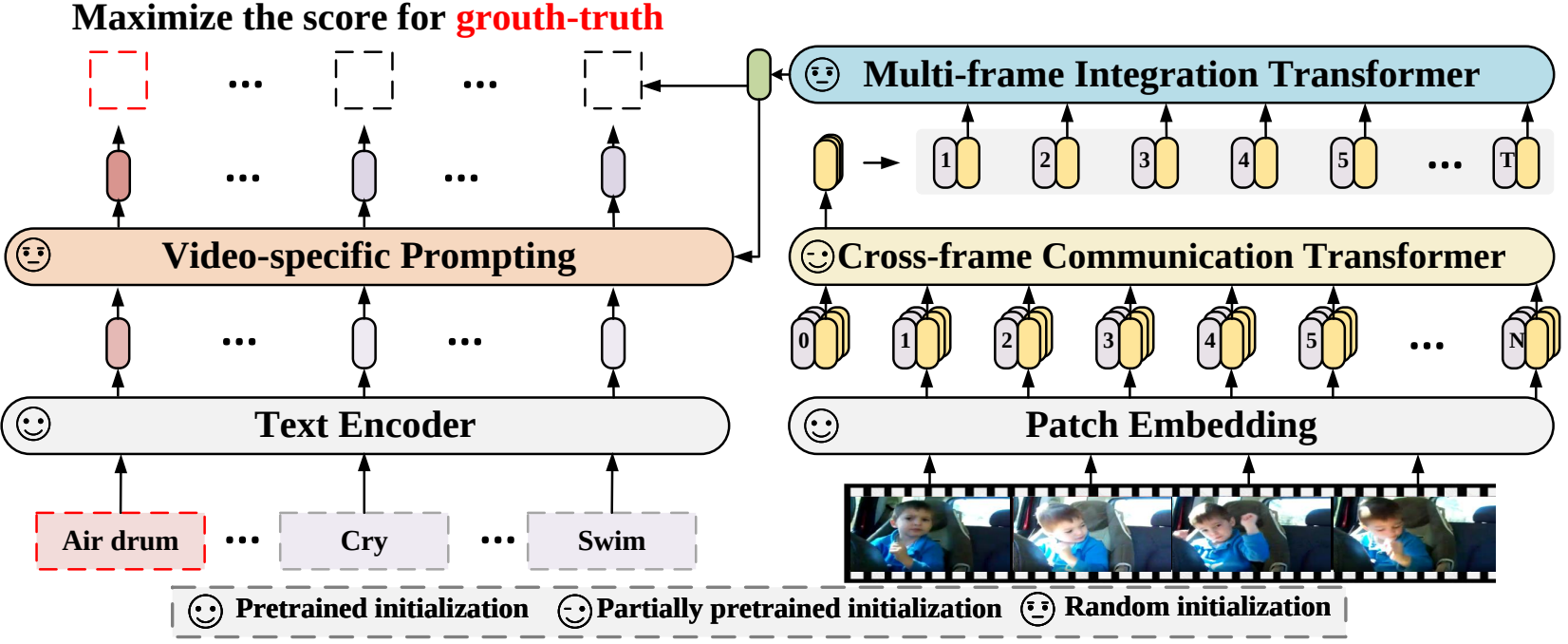
在本文中,我们提出了一种新的视频识别框架,该框架将预训练的语言图像模型应用于视频识别。具体来说,为了捕获时间信息,我们提出了一种跨帧注意机制,可以显式地跨帧交换信息。为了利用视频类别中的文本信息,我们设计了一种特定于视频的提示技术,该技术可以产生实例级判别性文本表示。大量的实验证明我们的方法是有效的,并且可以推广到不同的视频识别场景,包括完全监督、少样本和零样本。
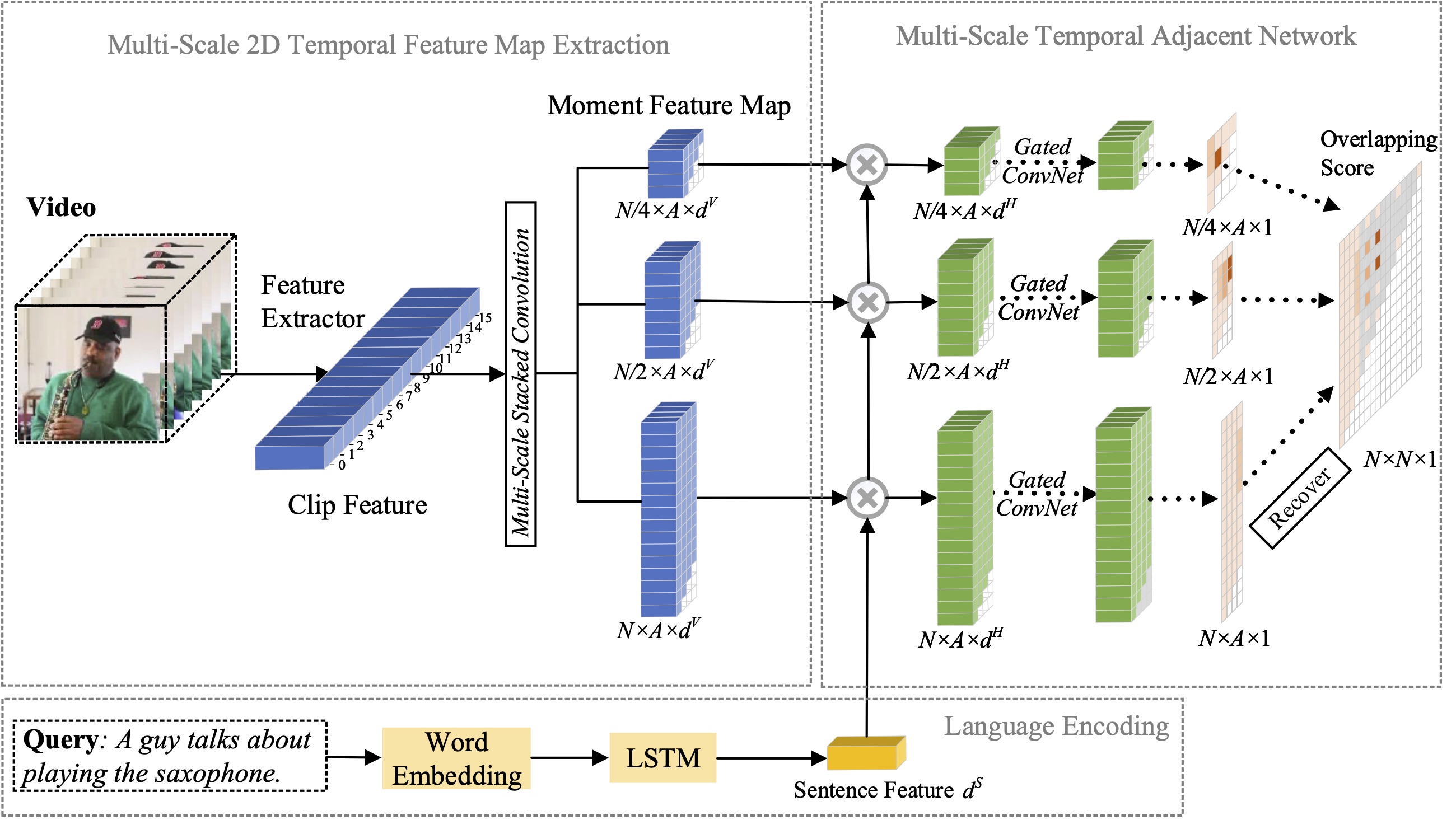
在本文中,我们研究了自然语言的矩定位问题,并提出将我们之前提出的 2D-TAN 方法扩展到多尺度版本。核心思想是从不同时间尺度的二维时间图中检索时刻,将相邻候选时刻视为时间上下文。扩展版本能够对不同尺度的相邻时间关系进行编码,同时学习用于将视频时刻与引用表达相匹配的判别特征。我们的模型设计简单,与三个基准数据集上最先进的方法相比,实现了具有竞争力的性能。
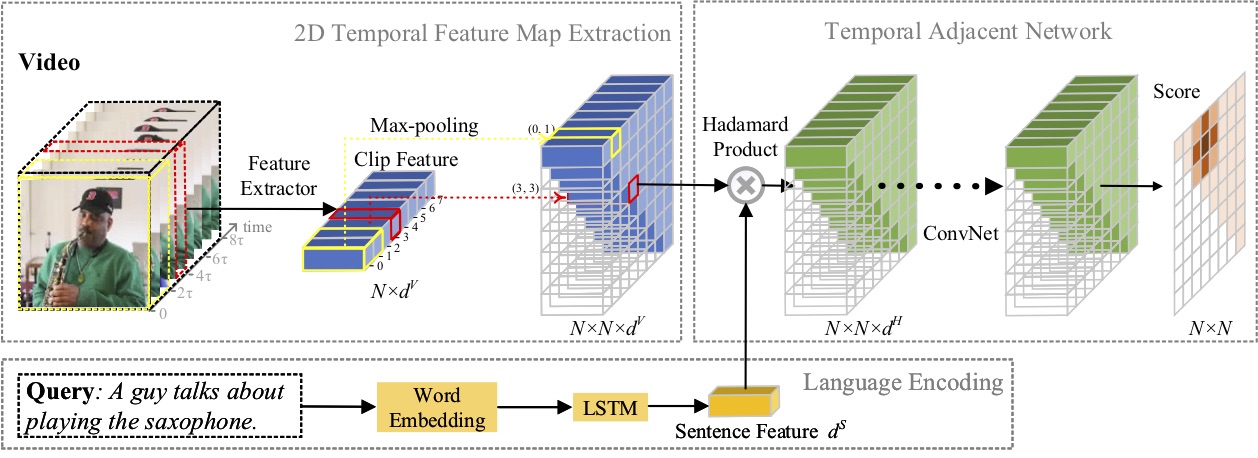
在本文中,我们研究了自然语言的矩定位问题,并提出了一种新颖的2D Temporal Adjacent Networks(2D-TAN)方法。核心思想是检索二维时间图上的时刻,它将相邻候选时刻视为时间上下文。 2D-TAN 能够对相邻时间关系进行编码,同时学习用于将视频时刻与参考表达进行匹配的判别特征。我们的模型设计简单,与三个基准数据集上最先进的方法相比,实现了具有竞争力的性能。
@InProceedings{SeqTrack,title={SeqTrack:视觉对象跟踪的序列到序列学习},作者={Chen,Xin and Peng,Houwen and Wang,Dong and Lu,Huchuan and Hu,Han},booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={扩展用于通用视频识别的语言-图像预训练模型},作者={倪,博林和彭,侯文和陈,明浩和张,松阳和孟,高峰和付,建龙和项,石明和凌,海滨},书名={欧洲计算机视觉会议(ECCV)},年份={2022}}@InProceedings{Zhang2021MS2DTAN,
作者 = {张松阳、彭、侯文、付、建龙、陆、宜娟、罗杰波},
title = {用于自然语言矩定位的多尺度2D时间相邻网络},
书名 = {TPAMI},
年 = {2021}}@InProceedings{2DTAN_2020_AAAI,
作者 = {张松阳、彭、侯文、付、建龙、罗、杰波},
title = {学习 2D 时态相邻网络以使用自然语言进行时刻本地化},
书名 = {AAAI},
年 = {2020}}根据 MIT 许可证进行许可。


