horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod 是一个适用于 TensorFlow、Keras、PyTorch 和 Apache MXNet 的分布式深度学习训练框架。 Horovod 的目标是让分布式深度学习变得快速且易于使用。
Horovod 由 LF AI & Data Foundation(LF AI & Data)主办。如果您是一家致力于在人工智能、机器和深度学习领域使用开源技术的公司,并且希望支持这些领域的开源项目社区,请考虑加入 LF AI & Data Foundation。有关谁参与以及 Horovod 如何发挥作用的详细信息,请阅读 Linux 基金会公告。
内容
该项目的主要动机是让单个 GPU 训练脚本变得更容易,并成功地将其扩展为跨多个 GPU 并行训练。这有两个方面:
在 Uber 内部,我们发现 MPI 模型比以前的解决方案(例如带有参数服务器的分布式 TensorFlow)要简单得多,并且需要的代码更改要少得多。一旦使用 Horovod 编写了可扩展的训练脚本,它就可以在单 GPU、多 GPU 甚至多主机上运行,而无需任何进一步的代码更改。有关更多详细信息,请参阅“用法”部分。
除了易于使用之外,Horovod 的速度也很快。下面的图表代表了在 128 台服务器上完成的基准测试,这些服务器配备 4 个 Pascal GPU,每个服务器都通过支持 RoCE 的 25 Gbit/s 网络连接:
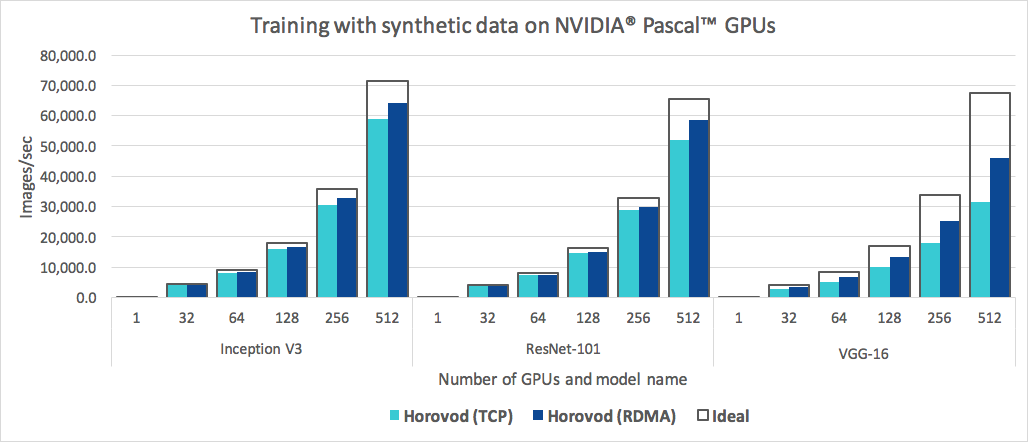
Horovod 对 Inception V3 和 ResNet-101 实现了 90% 的缩放效率,对 VGG-16 实现了 68% 的缩放效率。请参阅基准以了解如何重现这些数字。
虽然安装 MPI 和 NCCL 本身可能看起来很麻烦,但处理基础设施的团队只需要完成一次,而公司中构建模型的其他人都可以享受大规模训练模型的简单性。
要在 Linux 或 macOS 上安装 Horovod:
如果您从 PyPI 安装了 TensorFlow,请确保安装了g++-5或更高版本。从 TensorFlow 2.10 开始,需要使用符合 C++17 的编译器,例如g++8或更高版本。
如果您从 PyPI 安装了 PyTorch,请确保安装了g++-5或更高版本。
如果您已从 Conda 安装了任一软件包,请确保安装了gxx_linux-64 Conda 软件包。
安装horovod pip 软件包。
要在 CPU 上运行:
$ pip install horovod要使用 NCCL 在 GPU 上运行:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovod有关安装具有 GPU 支持的 Horovod 的更多详细信息,请阅读 GPU 上的 Horovod。
有关 Horovod 安装选项的完整列表,请阅读安装指南。
如果您想使用 MPI,请阅读 Horovod with MPI。
如果您想使用 Conda,请阅读为 Horovod 构建具有 GPU 支持的 Conda 环境。
如果您想使用 Docker,请阅读 Docker 中的 Horovod。
要从源代码编译 Horovod,请按照贡献者指南中的说明进行操作。
Horovod 核心原则基于 MPI 概念,例如大小、等级、本地等级、 allreduce 、 allgather 、 broadcast和alltoall 。请参阅此页面了解更多详细信息。
请参阅以下页面了解 Horovod 示例和最佳实践:
要使用 Horovod,请在您的程序中添加以下内容:
hvd.init()来初始化 Horovod。将每个 GPU 固定到单个进程以避免资源争用。
对于每个进程一个 GPU 的典型设置,将其设置为localrank 。服务器上的第一个进程将分配第一个 GPU,第二个进程将分配第二个 GPU,依此类推。
根据工作人员数量调整学习率。
同步分布式训练中的有效批量大小根据工作人员数量进行缩放。学习率的增加可以补偿批量大小的增加。
将优化器包装在hvd.DistributedOptimizer中。
分布式优化器将梯度计算委托给原始优化器,使用allreduce或allgather平均梯度,然后应用这些平均梯度。
将初始变量状态从 0 级广播到所有其他进程。
当使用随机权重开始训练或从检查点恢复训练时,这是确保所有工作人员的一致初始化所必需的。
使用 TensorFlow v1 的示例(请参阅示例目录以获取完整的训练示例):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )下面的示例命令展示了如何运行分布式训练。请参阅运行 Horovod 了解更多详细信息,包括 RoCE/InfiniBand 调整和处理挂起的技巧。
要在具有 4 个 GPU 的计算机上运行:
$ horovodrun -np 4 -H localhost:4 python train.py要在 4 台机器上运行,每台机器有 4 个 GPU:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py要在不使用horovodrun包装器的情况下使用 Open MPI 运行,请参阅使用 Open MPI 运行 Horovod。
要在 Docker 中运行,请参阅 Docker 中的 Horovod。
要在 Kubernetes 上运行,请参阅 Helm Chart、Kubeflow MPI Operator、FfDL 和 Polyaxon。
要在 Spark 上运行,请参阅 Spark 上的 Horovod。
要在 Ray 上运行,请参阅 Horovod on Ray。
要在 Singularity 中运行,请参阅 Singularity。
要在 LSF HPC 集群(例如 Summit)中运行,请参阅 LSF。
要在 Hadoop Yarn 上运行,请参阅 TonY。
Gloo 是 Facebook 开发的开源集体通信库。
Gloo 包含在 Horovod 中,允许用户无需安装 MPI 即可运行 Horovod。
对于同时支持 MPI 和 Gloo 的环境,您可以通过将--gloo参数传递给horovodrun来选择在运行时使用 Gloo :
$ horovodrun --gloo -np 2 python train.pyHorovod 支持 Horovod 集体与其他 MPI 库(例如 mpi4py)混合和匹配,前提是 MPI 是使用多线程支持构建的。
您可以通过查询hvd.mpi_threads_supported()函数来检查 MPI 多线程支持。
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()您还可以使用 mpi4py 子通信器初始化 Horovod,在这种情况下,每个子通信器将运行独立的 Horovod 训练。
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))了解如何优化推理模型并从此处的图表中删除 Horovod 操作。
Horovod 的独特之处之一是它能够交错通信和计算,再加上批处理小型allreduce操作的能力,从而提高性能。我们将这种批处理功能称为“张量融合”。
请参阅此处了解完整详细信息和调整说明。
Horovod有能力记录其活动的时间线,称为Horovod时间线。
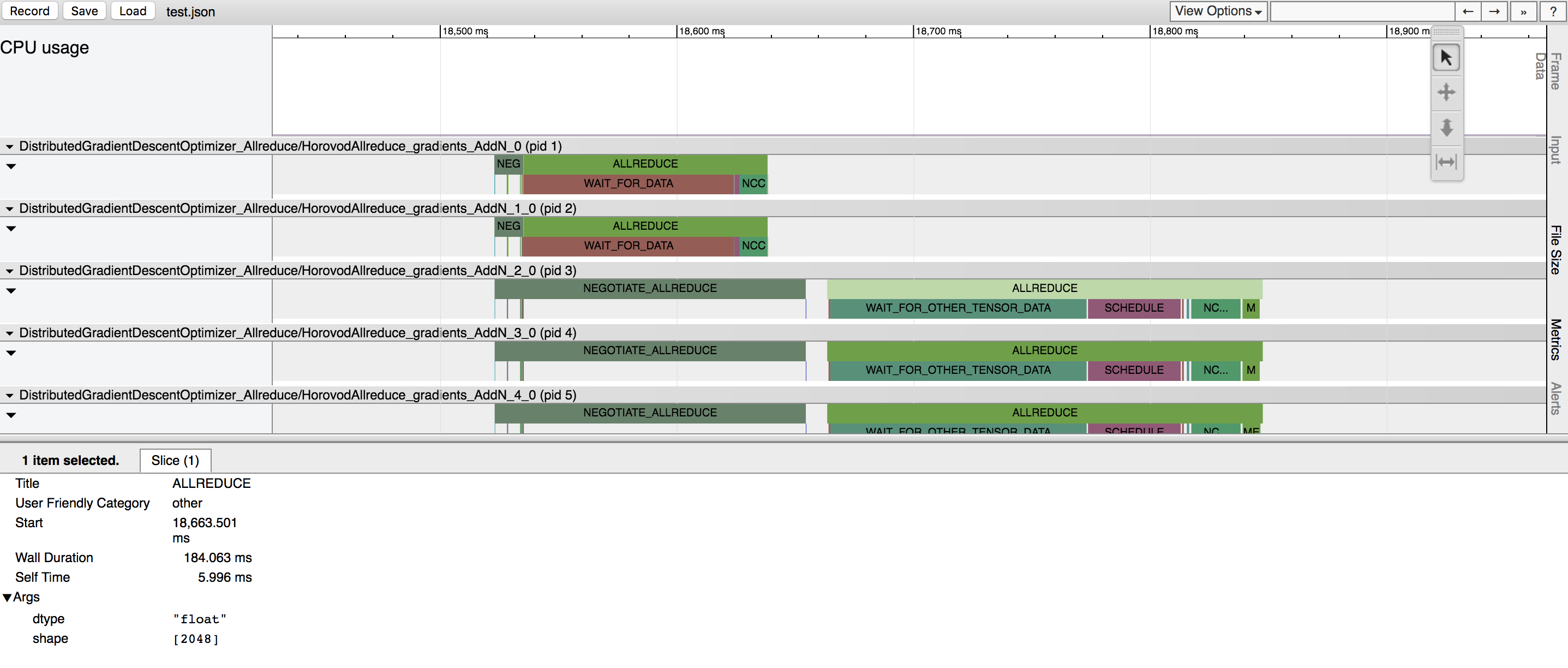
使用 Horovod 时间线来分析 Horovod 性能。请参阅此处了解完整详细信息和使用说明。
选择正确的值来有效利用 Tensor Fusion 和其他高级 Horovod 功能可能需要大量的试验和错误。我们提供了一个称为autotuning的系统来自动执行此性能优化过程,您可以使用horovodrun的单个命令行参数来启用该系统。
请参阅此处了解完整详细信息和使用说明。
Horovod 允许您在参与一次分布式训练的不同进程组中同时运行不同的集体操作。设置hvd.process_set对象以利用此功能。
有关详细说明,请参阅流程集。
向我们发送您想要在此网站上发布的任何用户指南的链接
如果找不到答案,请参阅疑难解答并提交票证。
如果 Horovod 对您的研究有帮助,请在您的出版物中引用它:
@文章{sergeev2018horovod,
作者 = {亚历山大·谢尔盖耶夫和迈克·德尔·巴尔索},
期刊 = {arXiv 预印本 arXiv:1802.05799},
Title = {Horovod:{TensorFlow}中快速简单的分布式深度学习},
年份 = {2018}
}
1. Sergeev, A.,Del Balso, M. (2017)认识 Horovod:Uber 的 TensorFlow 开源分布式深度学习框架。检索自 https://eng.uber.com/horovod/
2.Sergeev, A. (2017) Horovod - 分布式 TensorFlow 变得简单。检索自 https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A.,Del Balso, M. (2018) Horovod:TensorFlow 中快速且简单的分布式深度学习。检索自 arXiv:1802.05799
Horovod 源代码基于 Andrew Gibiansky 和 Joel Hestness 编写的百度 tensorflow-allreduce 存储库。他们的原创工作在《将 HPC 技术引入深度学习》一文中进行了描述。


