Index 1.9B
1.0.0
切换到中文 |在线:聊天和角色扮演 | QQ:QQ群
Index-1.9B系列是Index系列型号的轻量化版本,包括以下型号:
| 模型 | 平均分 | 英语平均分 | MMLU | 西瓦尔 | CMLU | 海拉斯瓦格 | 弧形C | 弧形E |
|---|---|---|---|---|---|---|---|---|
| 谷歌杰玛 2B | 41.58 | 46.77 | 41.81 | 31.36 | 31.02 | 66.82 | 36.39 | 42.07 |
| Φ2 (2.7B) | 58.89 | 72.54 | 57.61 | 31.12 | 32.05 | 70.94 | 74.51 | 87.1 |
| Qwen1.5-1.8B | 58.96 | 59.28 | 47.05 | 59.48 | 57.12 | 58.33 | 56.82 | 74.93 |
| Qwen2-1.5B(报告) | 65.17 | 62.52 | 56.5 | 70.6 | 70.3 | 66.6 | 43.9 | 83.09 |
| 迷你CPM-2.4B-SFT | 62.53 | 68.75 | 53.8 | 49.19 | 50.97 | 67.29 | 69.44 | 84.48 |
| Index-1.9B-纯 | 50.61 | 52.99 | 46.24 | 46.53 | 45.19 | 62.63 | 41.97 | 61.1 |
| 索引-1.9B | 64.92 | 69.93 | 52.53 | 57.01 | 52.79 | 80.69 | 65.15 | 81.35 |
| 骆驼2-7B | 50.79 | 60.31 | 44.32 | 32.42 | 31.11 | 76 | 46.3 | 74.6 |
| Mistral-7B(报告) | / | 69.23 | 60.1 | / | / | 81.3 | 55.5 | 80 |
| 百川2-7B | 54.53 | 53.51 | 54.64 | 56.19 | 56.95 | 25.04 | 57.25 | 77.12 |
| 骆驼2-13B | 57.51 | 66.61 | 55.78 | 39.93 | 38.7 | 76.22 | 58.88 | 75.56 |
| 百川2-13B | 68.90 | 71.69 | 59.63 | 59.21 | 61.27 | 72.61 | 70.04 | 84.48 |
| MPT-30B(报告) | / | 63.48 | 46.9 | / | / | 79.9 | 50.6 | 76.5 |
| Falcon-40B(报告) | / | 68.18 | 55.4 | / | / | 83.6 | 54.5 | 79.2 |
评估代码基于 OpenCompass,并进行了兼容性修改。有关详细信息,请参阅评估文件夹。
| 抱脸 | 模型范围 |
|---|---|
| ? Index-1.9B-聊天 | Index-1.9B-聊天 |
| ? Index-1.9B-角色(角色扮演) | Index-1.9B-角色(角色扮演) |
| ?索引-1.9B-基础 | 索引-1.9B-基础 |
| ? Index-1.9B-碱基纯 | Index-1.9B-碱基纯 |
| ? Index-1.9B-32K(32K 长上下文) | Index-1.9B-32K(32K 长上下文) |
Index-1.9B-32K只能使用这个工具启动: demo/cli_long_text_demo.py !!!git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9Bpip install -r requirements.txt您可以使用以下代码加载 Index-1.9B-Chat 模型进行对话:
import argparse
from transformers import AutoTokenizer , pipeline
# Attention! The directory must not contain "." and can be replaced with "_".
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "./IndexTeam/Index-1.9B-Chat/" , type = str , help = "" )
parser . add_argument ( '--device' , default = "cpu" , type = str , help = "" ) # also could be "cuda" or "mps" for Apple silicon
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
generator = pipeline ( "text-generation" ,
model = args . model_path ,
tokenizer = tokenizer , trust_remote_code = True ,
device = args . device )
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input . append ({ "role" : "system" , "content" : system_message })
model_input . append ({ "role" : "user" , "content" : query })
model_output = generator ( model_input , max_new_tokens = 300 , top_k = 5 , top_p = 0.8 , temperature = 0.3 , repetition_penalty = 1.1 , do_sample = True )
print ( 'User:' , query )
print ( 'Model:' , model_output )取决于 Gradio,安装:
pip install gradio==4.29.0使用以下代码启动 Web 服务器。在浏览器中输入访问地址后,就可以使用Index-1.9B-Chat模型进行对话:
python demo/web_demo.py --port= ' port ' --model_path= ' /path/to/model/ '注意: Index-1.9B-32K只能使用这个工具启动: demo/cli_long_text_demo.py !!!
使用以下代码启动终端演示,以使用 Index-1.9B-Chat 模型进行对话:
python demo/cli_demo.py --model_path= ' /path/to/model/ '取决于 Flask,安装:
pip install flask==2.2.5使用以下代码启动 Flask API:
python demo/openai_demo.py --model_path= ' /path/to/model/ '您可以通过命令行进行对话:
curl http://127.0.0.1:8010/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红?"}
]
} 'Index-1.9B-32K 是一种只有 19 亿个参数的语言模型,但它支持 32K 的上下文长度(这意味着这个极小的模型可以一次性读取超过 35,000 个单词的文档)。该模型基于精心策划的长文本训练数据和自建的长文本指令集,专门针对超过 32K token 的文本进行了持续预训练和监督微调 (SFT)。该模型现已在 Hugging Face 和 ModelScope 上开源。
尽管尺寸较小(约为 GPT-4 等模型的 2%),Index-1.9B-32K 却表现出了出色的长文本处理能力。如下图所示,我们的1.9B尺寸型号的得分甚至超过了7B尺寸型号。下面是与 GPT-4 和 Qwen2 等模型的比较:
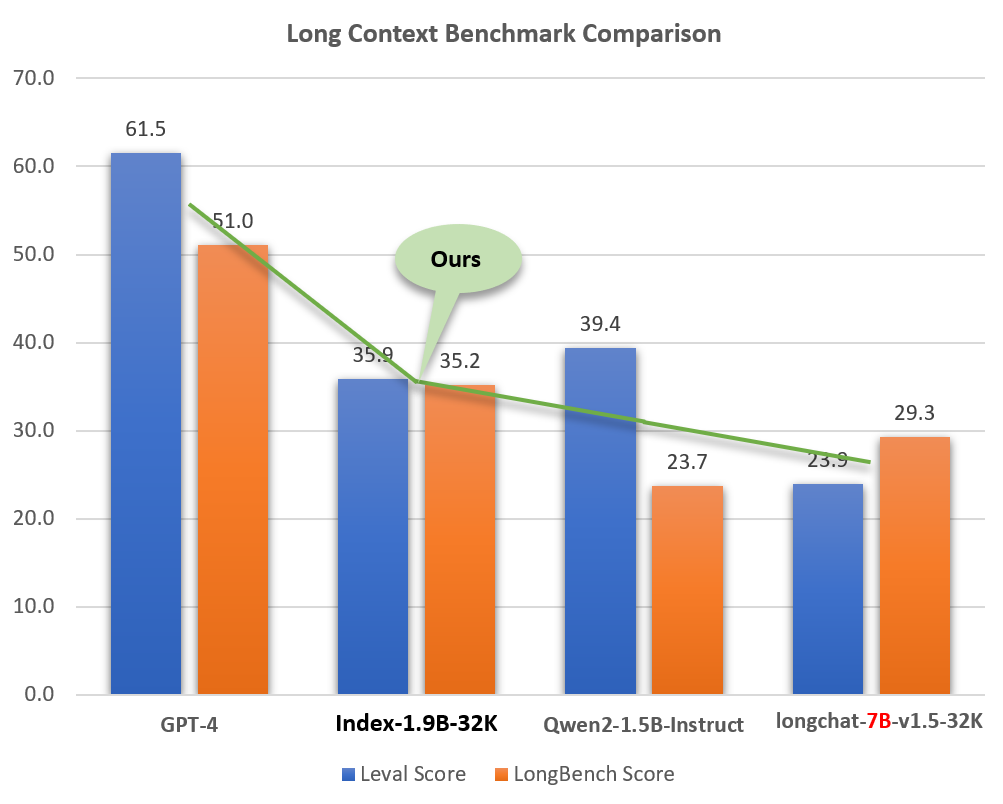
Index-1.9B-32K 与 GPT-4、Qwen2 等模型的长上下文能力比较
在32K长度大海捞针测试中,Index-1.9B-32K取得了优异的成绩,如下图所示。唯一的例外是(32K 长度,10% 深度)区域中的一个小黄点(91.08 分),所有其他区域在大部分绿色区域中都表现出色。
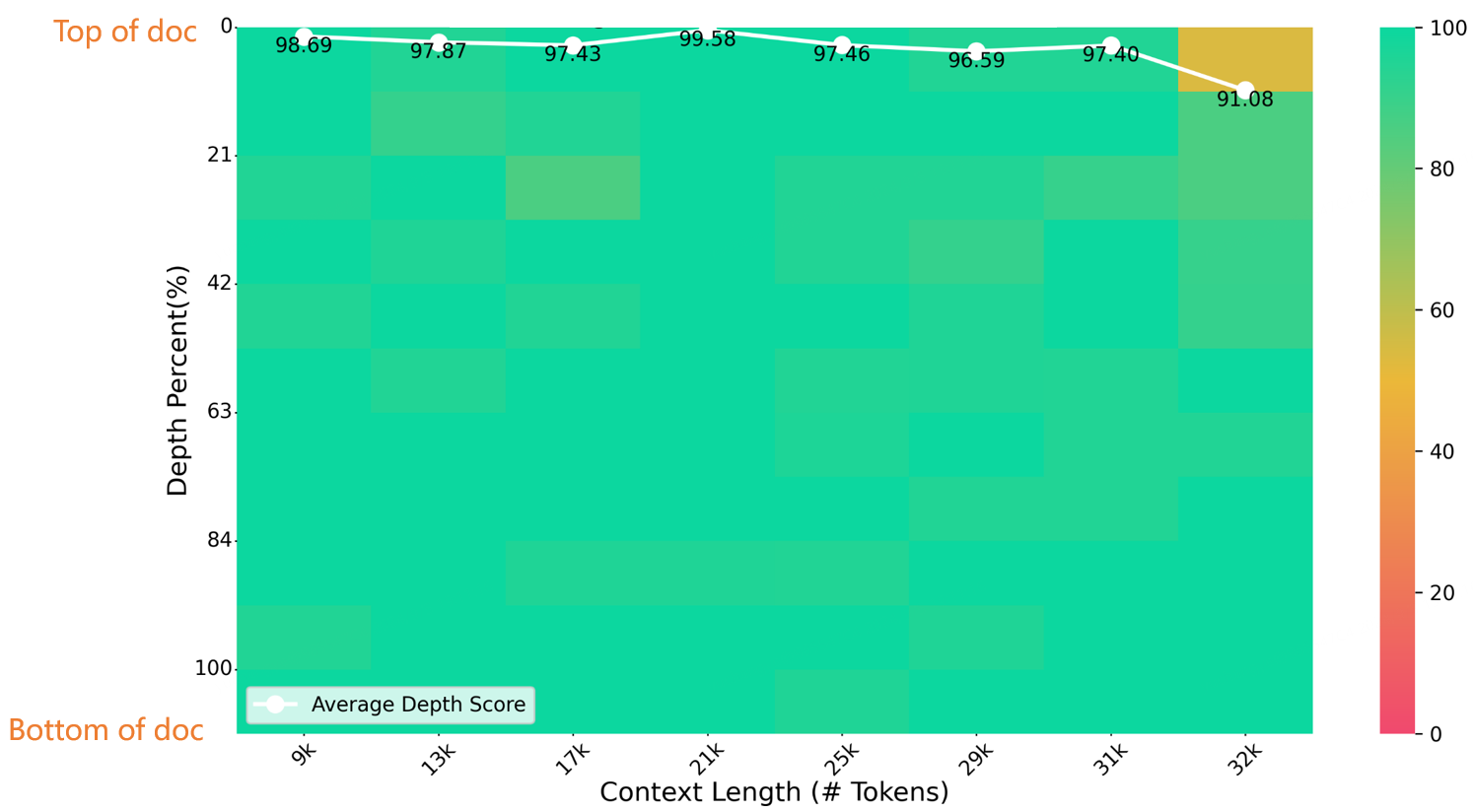
针台评估
Index-1.9B-32K的下载、使用和技术报告详情请参见:
Index-1.9B-32K 长上下文技术报告web_demo.py获取 Index-1.9B-Chat 输出的一些示例。 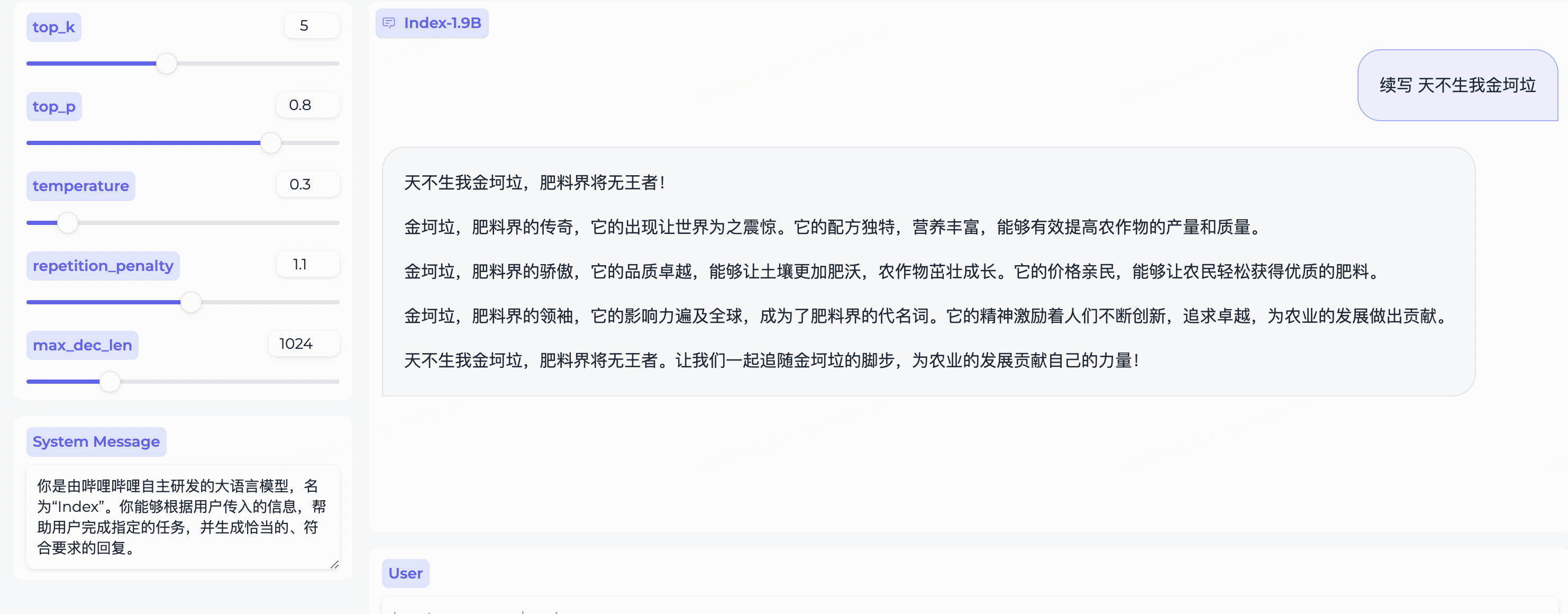
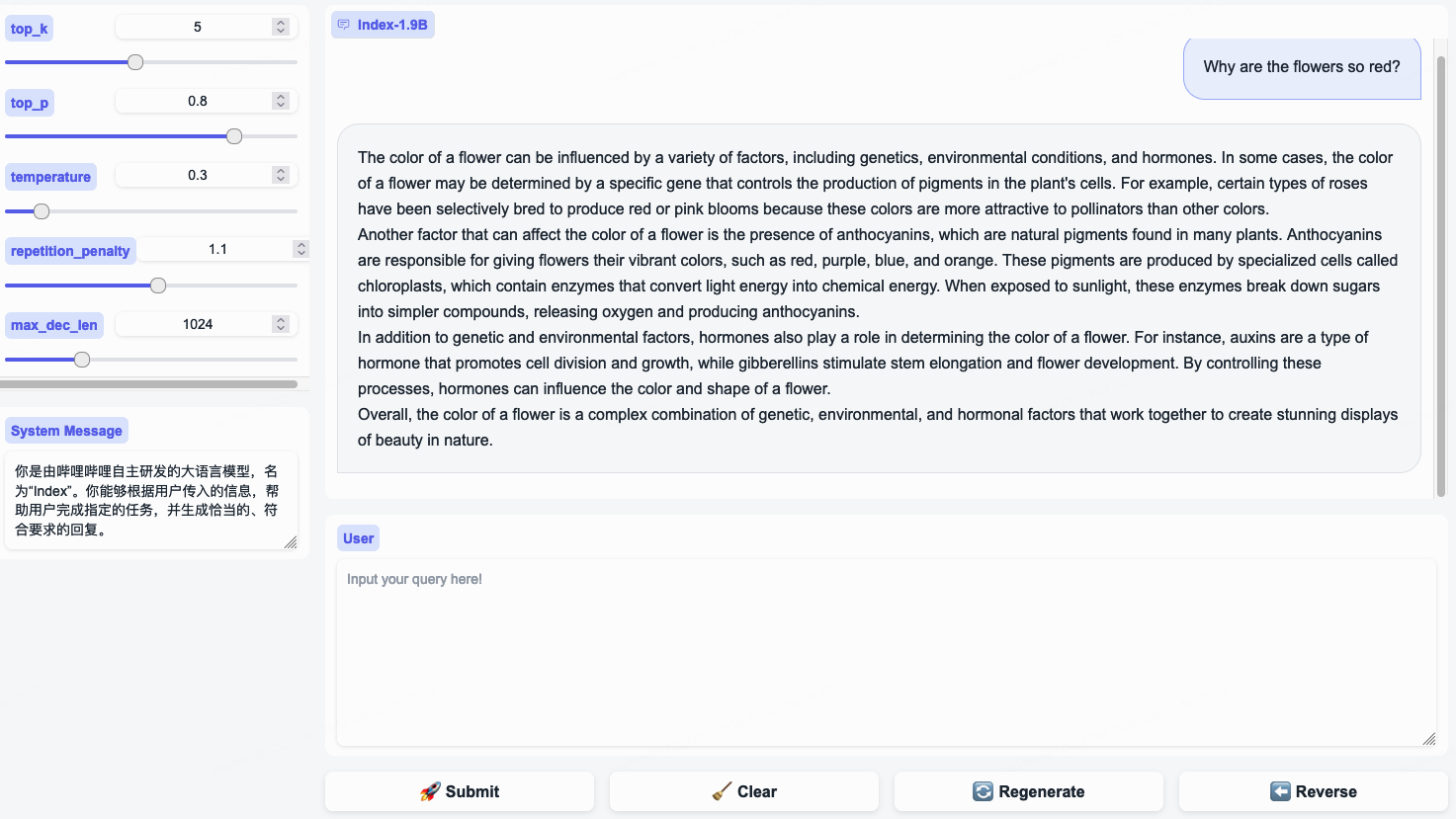
System Message ,扮演bilibili用户的刻板印象! 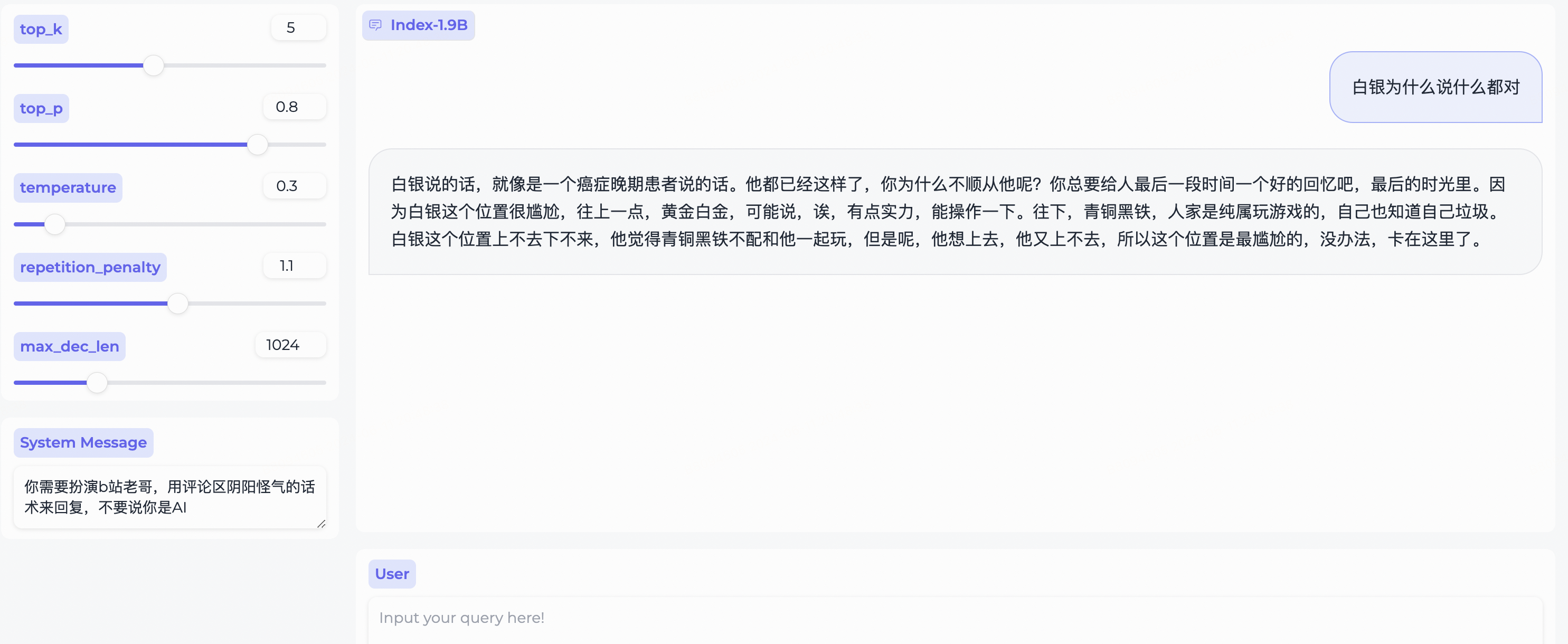
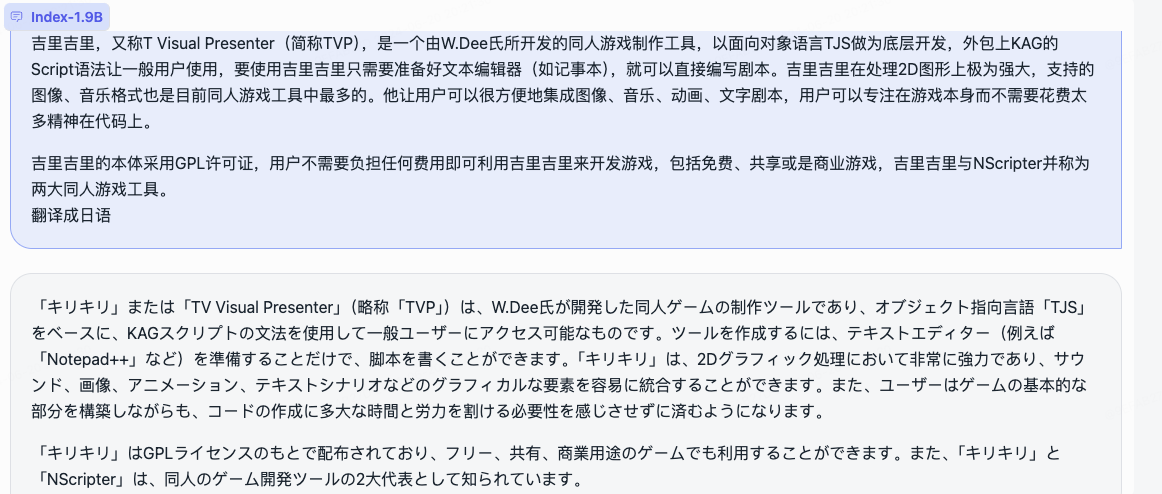
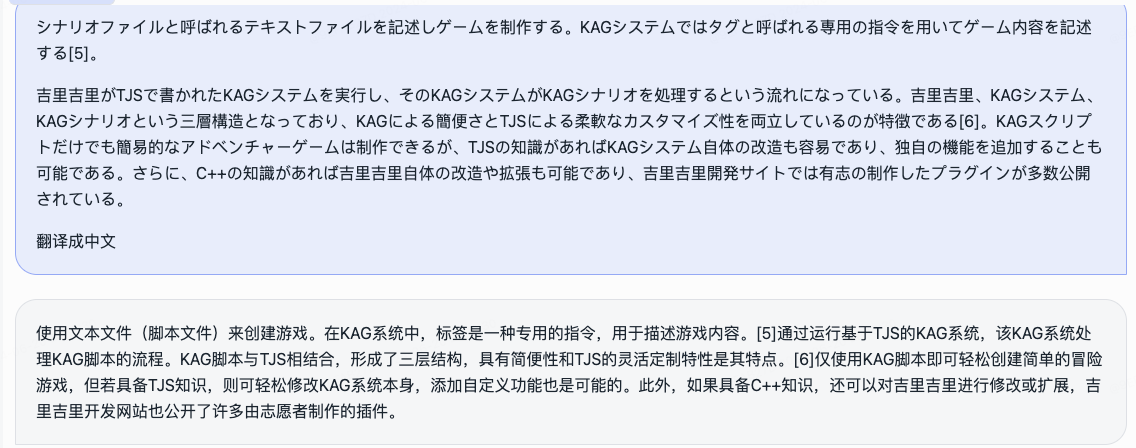
我们同时开源了角色扮演模型和配套框架。 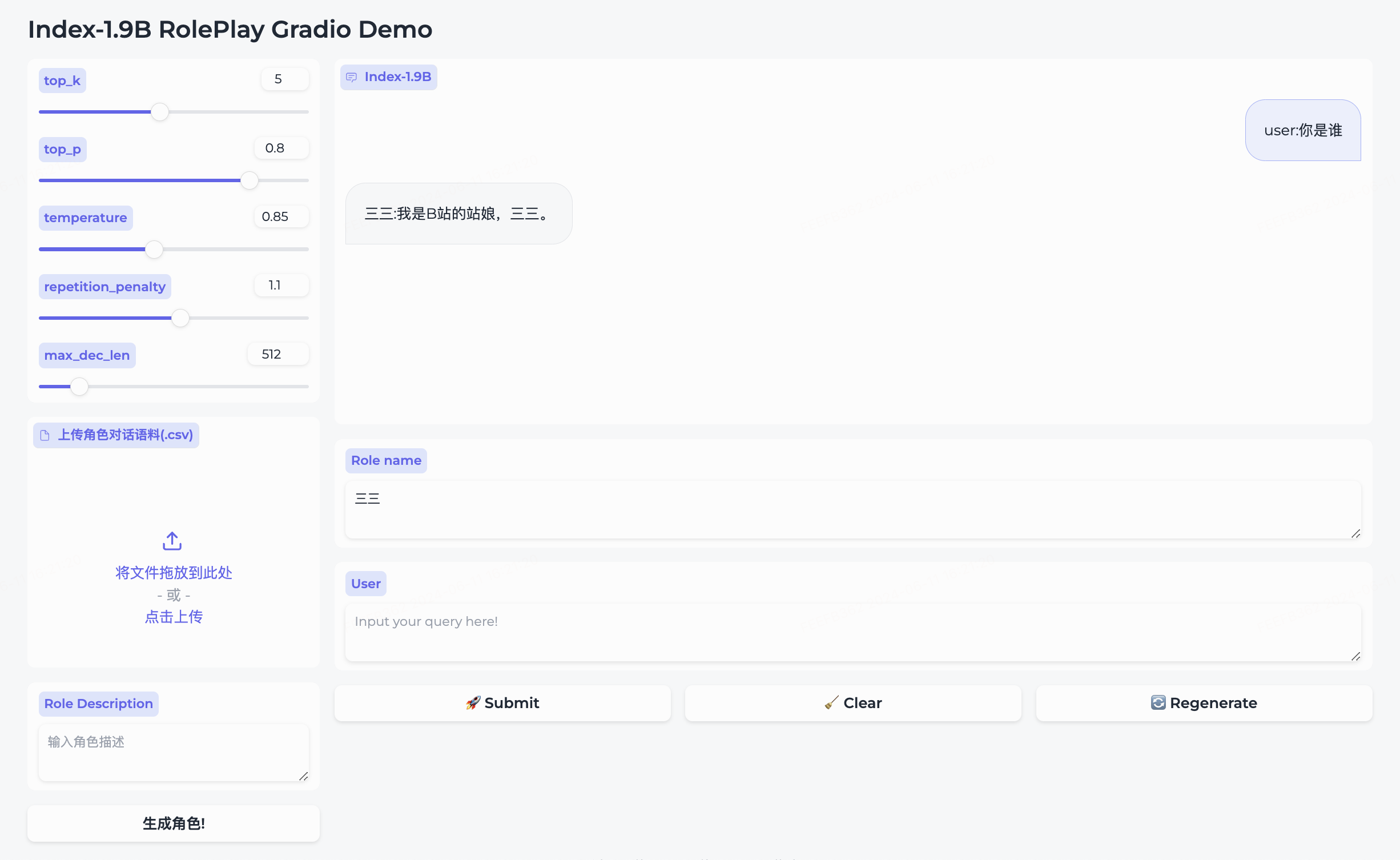
三三。生成角色即可创建成功。Role name字段中输入您想要对话的角色,输入您的query ,然后点击submit开始对话。详细使用方法请参考roleplay文件夹。
cd demo/
CUDA_VISIBLE_DEVICES=0 python cli_long_text_demo.py --model_path ' /path/to/model/ ' --input_file_path data/user_long_text.txt
翻译及摘要(B站财务报告于2024年8月22日发布)
取决于bitsandbytes,安装命令:
pip install bitsandbytes==0.43.0可以使用如下脚本进行int4量化,性能损失较小,进一步节省显存占用。
import torch
import argparse
from transformers import (
AutoModelForCausalLM ,
AutoTokenizer ,
TextIteratorStreamer ,
GenerationConfig ,
BitsAndBytesConfig
)
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "" , type = str , help = "" )
parser . add_argument ( '--save_model_path' , default = "" , type = str , help = "" )
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
quantization_config = BitsAndBytesConfig (
load_in_4bit = True ,
bnb_4bit_compute_dtype = torch . float16 ,
bnb_4bit_use_double_quant = True ,
bnb_4bit_quant_type = "nf4" ,
llm_int8_threshold = 6.0 ,
llm_int8_has_fp16_weight = False ,
)
model = AutoModelForCausalLM . from_pretrained ( args . model_path ,
device_map = "auto" ,
torch_dtype = torch . float16 ,
quantization_config = quantization_config ,
trust_remote_code = True )
model . save_pretrained ( args . save_model_path )
tokenizer . save_pretrained ( args . save_model_path )按照微调教程中的步骤快速微调 Index-1.9B-Chat 模型。尝试一下,定制您的专属 Index 模型!
在某些情况下,Index-1.9B 可能会生成不准确、有偏见或其他令人反感的内容。模型无法理解、表达个人观点、或做出价值判断。其输出并不代表模型开发人员的观点和立场。因此,请谨慎使用生成的内容。用户应对模型生成的内容进行独立评估和验证,不得传播有害内容。开发者在部署相关应用之前,应根据具体应用进行安全测试和微调。
我们强烈建议不要使用这些模型来创建或传播有害信息或从事可能损害公共、国家或社会安全或违反法规的活动。未经适当的安全审查和备案,请勿将模型用于互联网服务。我们已尽一切努力确保训练数据的合规性,但由于模型和数据的复杂性,不可预见的问题仍然可能存在。对于因使用这些模型而产生的任何问题,无论是涉及数据安全、舆论风险,还是因误解、误用、传播或不合规使用模型而导致的任何风险和问题,我们均不承担责任。
使用此存储库中的源代码需要符合 Apache-2.0。使用 Index-1.9B 模型权重需要遵守 INDEX_MODEL_LICENSE。
Index-1.9B模型权重完全开放用于学术研究并支持免费商业使用。
如果您认为我们的工作对您有帮助,请随时转发!
@article{Index,
title={Index1.9B Technical Report},
year={2024}
}
libllm:https://github.com/ling0322/libllm/blob/main/examples/python/run_bilibili_index.py
chatllm.cpp:https://github.com/foldl/chatllm.cpp/blob/master/docs/rag.md#role-play-with-rag
ollama:https://ollama.com/milkey/bilibili-index
自我llm:https://github.com/datawhalechina/self-llm/blob/master/bilibili_Index-1.9B/04-Index-1.9B-Chat%20Lora%20修饰.md


