gptty
0.2.7
TTY 中的 ChatGPT 包装器
笔记
该版本支持gpt4和gpt4-turbo!
gptty 是一个 ChatGPT shell 接口,它允许您 (1) 以类似于 Web 应用程序的方式与 ChatGPT 交互,但不需要依赖于 Web 应用程序的稳定性; (2) 在聊天会话中保留上下文并按照您想要的方式构建对话; (3) 保存对话的本地副本以方便参考。
也许您是一名系统管理员,正在为您的雇主配置 Web 服务器。您从物理界面访问系统,具有互联网连接,但没有桌面环境或图形用户界面。在配置 Web 服务器时,您会收到一个莫名其妙的错误,您将其重定向到一个文件,但又不想费力地使用浏览器将其复制到另一个系统,以便查找该错误。相反,您安装 gptty 并使用gptty query --tag error --question "$(cat app.error | tr 'n' ' ')"等命令将错误重定向到聊天客户端(这将消除换行符)为你)或cat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (假定您的错误仅跨越一行)。
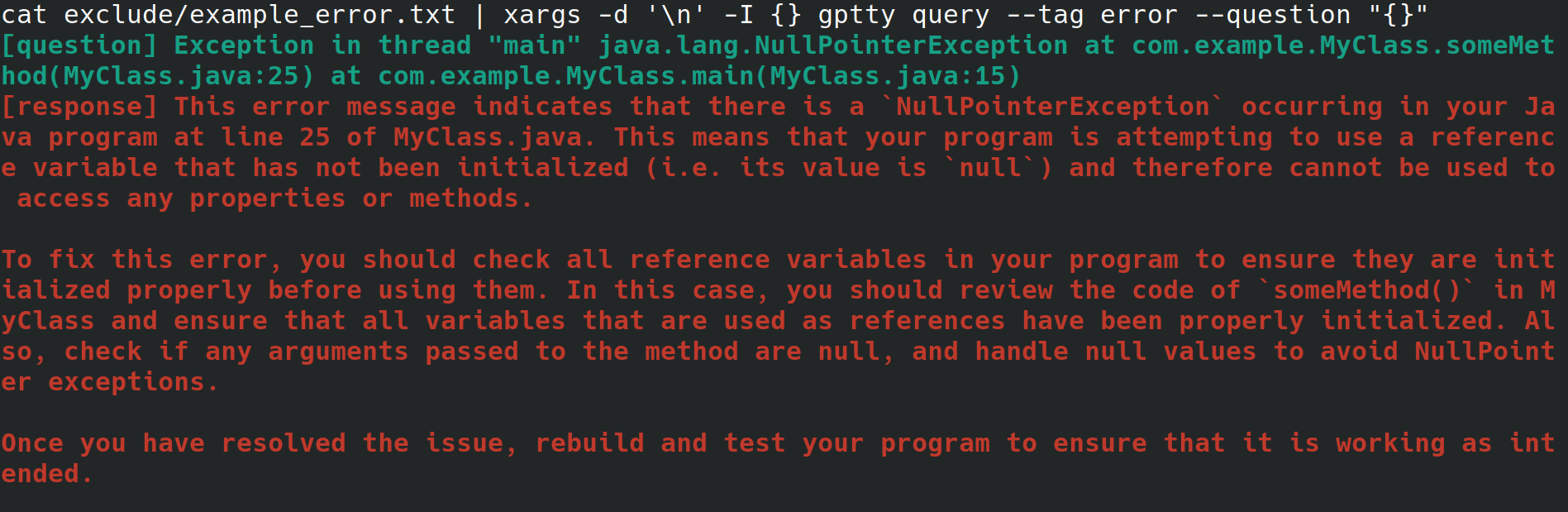
或者,您是一名软件开发人员或数据科学家,希望通过 ChatGPT 传输数据,但希望使用高度抽象的 API 来发出这些请求,而不是熟悉 OpenAI API 及其各种特定于语言的包装器。当您想要更新代码库以使用不同的模型时,您希望能够仅修改单个配置文件,并期望查询响应格式在各种模型之间保持一致。
或者,您可能是一位爱好者,想要保留对话的本地副本,或者想要对这些对话所采用的分类方法进行更直接的控制。
OpenAI 通过其 API 提供了许多模型。 [1] 目前,gptty 支持Completions (davinci、curie)和ChatCompletions (gpt-3.5-turbo、gpt-4)。您需要做的就是在配置中指定模型名称(默认为 text-davinci-003),应用程序将处理其余的事情。
您可以在 pip 上安装gptty :
pip install gptty
您还可以从 git 安装:
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
现在,您可以通过运行gptty --help来验证它是否正常工作。如果您遇到错误,请尝试配置应用程序。
gptty从名为gptty.ini的文件中读取配置设置,除非您传递自定义config_file ,否则应用程序预计该文件位于您运行gptty同一目录中。该文件使用 INI 文件格式,该格式由多个部分组成,每个部分都有自己的键值对。
| 钥匙 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| api_key | 细绳 | ”” | 您的 OpenAI GPT 服务的 API 密钥 |
| 组织ID | 细绳 | ”” | 您的 OpenAI GPT 服务的组织 ID |
| 你的名字 | 细绳 | “问题” | 输入提示的名称 |
| gpt_名称 | 细绳 | “回复” | 生成的响应的名称 |
| 输出文件 | 细绳 | “输出.txt” | 将保存输出的文件的名称 |
| 模型 | 细绳 | “文本-达芬奇-003” | 要使用的 GPT 模型的名称 |
| 温度 | 漂浮 | 0.0 | 采样温度 |
| 最大令牌数 | 整数 | 250 | 为响应生成的最大令牌数 |
| 最大上下文长度 | 整数 | 150 | 输入上下文的最大长度 |
| 仅上下文关键字 | 布尔 | 真的 | 对关键字进行标记以减少 API 使用 |
| 保留新行 | 布尔 | 错误的 | 保留回复的原始格式 |
| 验证互联网端点 | 细绳 | “google.com” | 用于验证互联网连接的地址 |
您可以修改配置文件中的设置以满足您的需要。如果配置文件中不存在某个键,则将使用默认值。 [main] 部分用于指定程序的设置。
[main]
api_key =my_api_key此存储库提供了一个示例配置文件assets/gptty.ini.example ,您可以将其用作起点。
聊天功能提供了一个交互式聊天界面来与ChatGPT进行通信。您可以提出问题并实时接收回复。
要启动聊天界面,请运行gptty chat 。您还可以通过运行指定自定义配置文件路径:
gptty chat --config_path /path/to/your/gptty.ini
在聊天界面中,您可以直接输入问题或命令。要查看可用命令的列表,请键入:help ,这将显示以下选项。
| 元命令 | 描述 |
|---|---|
| :帮助 | 显示可用命令及其描述的列表。 |
| :辞职 | 退出 ChatGPT。 |
| :日志 | 显示当前配置设置。 |
| :上下文[a:b] | 显示上下文历史记录,可以选择指定范围 a 和 b。开发中 |
要使用命令,只需在命令提示符中键入该命令并按 Enter 键即可。例如,使用以下命令显示终端中的当前配置设置:
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
您可以随时在提示中输入问题,它会为您生成答复。如果您想跨查询共享上下文,请参阅下面的上下文部分。
查询功能允许您向 ChatGPT 提交单个或多个问题并直接在命令行中接收答案。
要使用查询功能,请运行以下命令:
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
您还可以提供可选标签来对查询进行分类:
gptty query --question "What is the capital of France?" --tag "geography"
如果需要,您可以指定自定义配置文件路径:
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
请记住,gptty 使用配置文件(默认为 gptty.ini)来存储 API 密钥、模型配置和输出文件路径等设置。在运行 gptty 命令之前,请确保您具有有效的配置文件。
通过在聊天和查询命令末尾添加--verbose标签,应用程序将提供额外的调试数据,包括每个请求的令牌计数。当您需要跟踪 API 使用率时,这会很有用。

通过将--additional_context [some_string_here]选项添加到查询命令中,应用程序将添加您传递的任何字符串作为问题的进一步外部上下文。
通过在查询命令末尾添加--json标签,应用程序将跳过将人类可读的文本写入标准输出,而是将问题和响应写入 json 对象,例如[{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] .

通过在查询命令末尾添加--quiet标记,应用程序将跳过向 stdout 写入任何内容,但仍会将响应写入应用程序配置文件中指定的output_file 。
在此应用程序中使用chat和query子命令时标记上下文文本有助于提高生成响应的准确性。以下是应用程序如何使用chat命令处理上下文:
bananas或shakespeare 。[tag]前缀来将标签包含在输入消息中。例如,如果您的问题的上下文是“烹饪”,您可以将其标记为[cooking] 。确保对所有相关查询一致使用相同的标签。以下是使用标记为[shakespeare]问题的示例。请注意,在第二个问题中,根本没有提到“威廉·莎士比亚”这个名字。
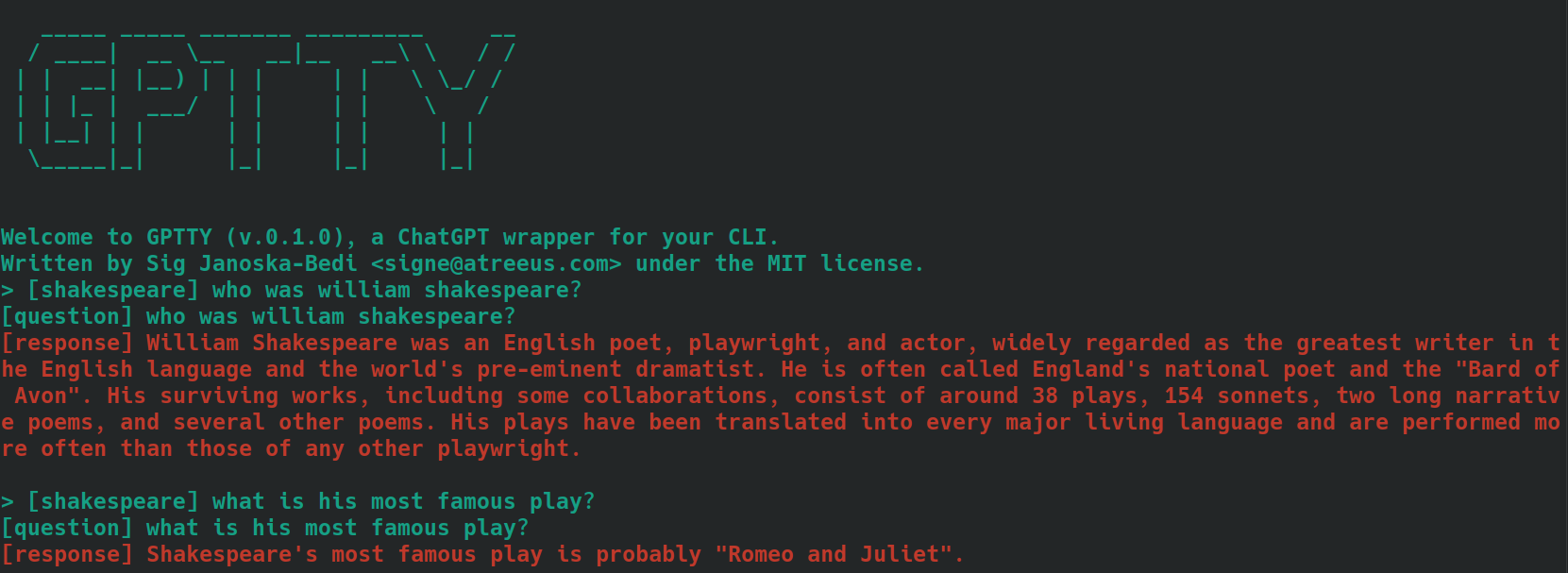
使用query命令时,请按照上述相同步骤操作,但不要在问题文本前面添加所需的标签,而是使用--tag选项在提交查询时包含该标签。例如,如果您的问题的上下文是“烹饪”,您可以使用:
gptty --question "some question" --tag cooking
该应用程序会将您标记的问题和响应保存在配置文件中指定的输出文件中。
您可以使用 bash 脚本自动执行将多个问题发送到gptty query命令的过程。如果您在文件中存储了问题列表,并且您想要一次处理所有问题,这会特别有用。例如,假设您有一个文件questions.txt每个问题都占一个新行,如下所示。
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
您可以使用以下 bash 单行代码将questions.txt文件中的每个问题发送到gptty query命令:
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt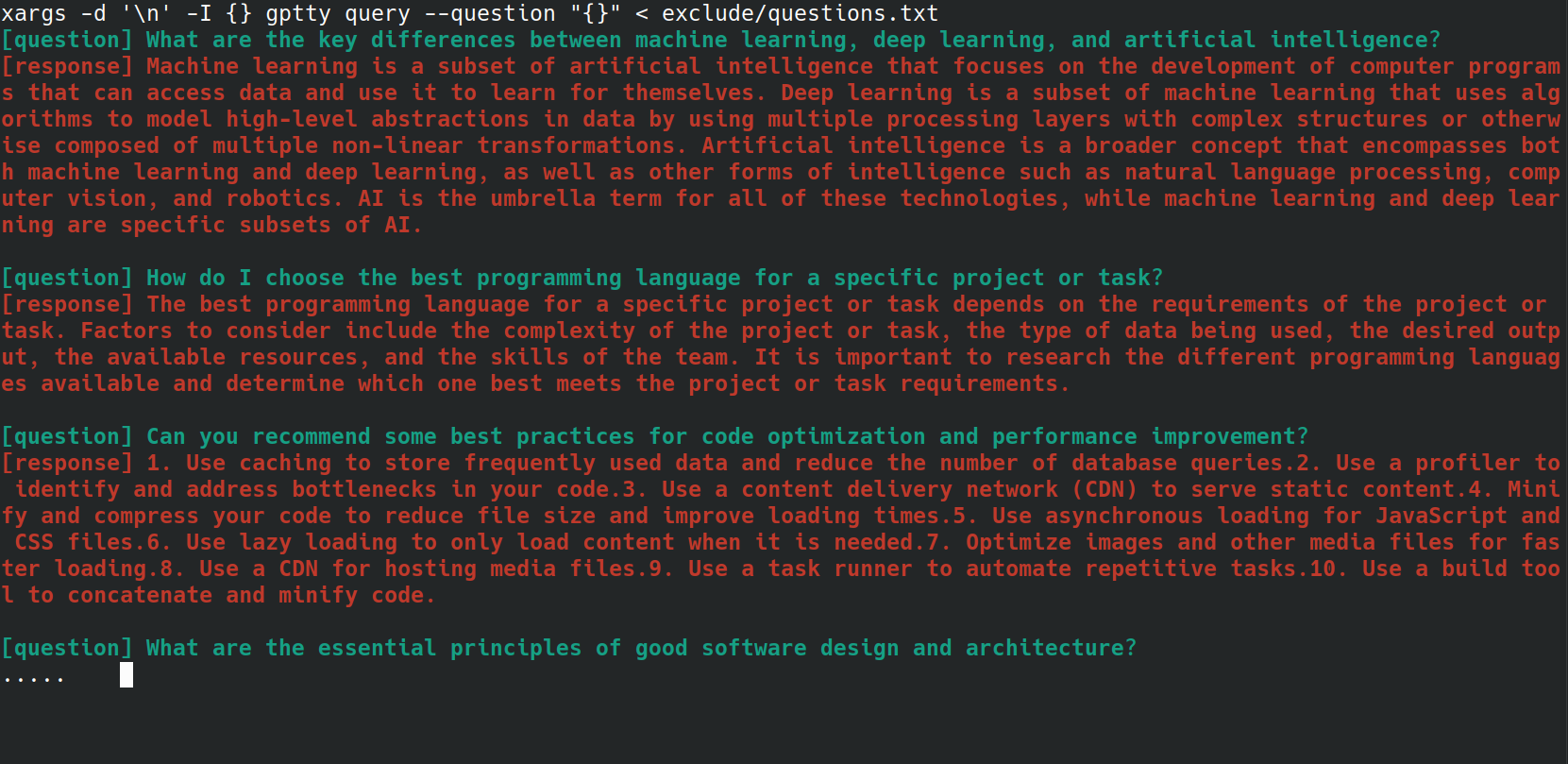
UniversalCompletion 类提供了一个统一的接口,用于与 OpenAI 的语言模型交互,(主要)抽象出应用程序是使用 Completion 还是 ChatCompletion 模式的细节。主要思想是促进语言模型的创建、配置和管理。这是一些示例用法。
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

