StableDiffusionEndToEndGuide
1.0.0
我开始对使用 SD 生成军事应用图像感兴趣。大部分资源取自 4chan 的 NSFW 版块,因为 anons 使用 SD 制作无尽。有趣的是,规范的 SD WebUI 具有动漫/无尽图像板的内置功能...DALL-E 之后 SD 的第一个用例就是生成动漫女孩,因此跳转到无尽并不奇怪。
无论如何,这些怪人的技术适用于各种应用,尤其是 LoRA,它就像模型微调器。这个想法是与特定的 LoRA(例如,军用车辆、飞机、武器等)合作,生成用于训练视觉模型的合成图像数据。训练新的、有用的 LoRA 也很有趣。稍后的内容可能包括针对扰动进行修复。
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
您实际上可以用 SD 做什么? Huggingface 和其他一些公司在浏览器中为您提供了一些应用程序。和他们一起玩,看看它们的威力!在本指南中我们要做的是获得完整的、可扩展的 WebUI,以便我们可以做任何我们想做的事情。
进入这个领域有点令人畏惧……但 4channers 做得很好,让这个变得平易近人。以下是我采取的最简单的步骤。您的目的是让 Stable Diffusion WebUI(使用 Gradio 构建)在本地运行,以便您可以开始提示和制作图像。
稍后我们将进行 Google Colab Pro 设置,这样我们就可以在任何我们想要的任何设备上运行 SD;但首先,让我们在 PC 上设置 WebUI。您需要 16GB RAM、具有 2GB VRAM 的 GPU、Windows 7+ 和 20+GB 磁盘空间。
127.0.0.1:7860 (不要使用 Ctrl + C,因为此命令可以关闭 CLI)stable-diffusion-webuioutputstxt2img-images<date>git pull 
如果您使用的是 Windows,请完全忽略这一点。我也设法让它在 Linux 上运行,尽管它有点复杂。我开始遵循这个指南,但它写得相当糟糕,所以下面是我让它在 Linux 中运行的步骤。我使用的是 Linux Mint 20,它是 Ubuntu 20 发行版。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webui/models/Stable-diffusionsudo apt install python3 python3-pip python3-virtualenv wget git wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda create --name sdwebui python=3.10.6conda activate sdwebui./webui.sh sudo apt update
sudo apt purge *nvidia*
sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get update更新sudo apt-get install nvidia-driver-530将其安装在终端中nvidia-smi ;如果成功,它应该打印一个表格;如果没有,它会说“无法连接到 GPU;请确保安装了最新的驱动程序” sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
python3 -c 'import venv'
python3 -m venv venv/
然后转到/stable-diffusion-webui文件夹并运行:
rm -rf venv/
python3 -m venv venv/
在那之后,它对我有用。
提示中的单词顺序会产生影响:较早的单词优先。一个好的提示的一般结构,来自这里:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
另一个很好的指南说提示应该遵循以下结构:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
关于提示工程 txt2img 模型的开创性论文,请参见此处。有关 LLM 提示的权威资源,请点击此处。
无论您提示什么,请尝试遵循某种结构,以便您的流程是可复制的。以下是必要的提示语法元素:
1girl standing on grass in front of castle AND castle in background 默认模型非常简洁,但正如历史上通常的情况一样,性驱动了大多数事情。 NovelAI(NAI)是一家专注于动漫的 SD 内容生成服务,其主要模型被泄露。您看到的大多数 SD 生成的动漫男女图像(无论是否是 NSFW)都来自这个泄露的模型。
无论如何,它确实非常擅长生成人物,并且您将玩合并的大多数模型或 LoRA 都与它兼容,因为它们是在动漫图像上进行训练的。此外,人类还提供了一个非常好的起始用例,可以精确调整您想要用于专业目的的 LoRA。您将需要解决很多问题,并且大多数指南都是针对女性图像的。稍后我们将介绍变量自动编码器(VAE),它为模型带来了真正的真实感。
stable-diffusion-webuimodelsStable-diffusion并选择其中的模型后,您应该等待几分钟,CLI 会加载 VAE 权重低秩适应 (LoRA) 允许对给定模型进行微调。有关 LoRA 的更多信息请参见此处。在WebUI中,您可以将LoRA添加到模型中,就像锦上添花一样。训练新的 LoRA 也非常容易。还有其他“祖先”的微调方法(例如文本反转和超网络),但 LoRA 是最先进的。
我将在整个指南中使用 LoRA 坦克。请注意,这不是一个很好的 LoRA,因为它适用于动漫风格的图像,但玩起来还是不错的。
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora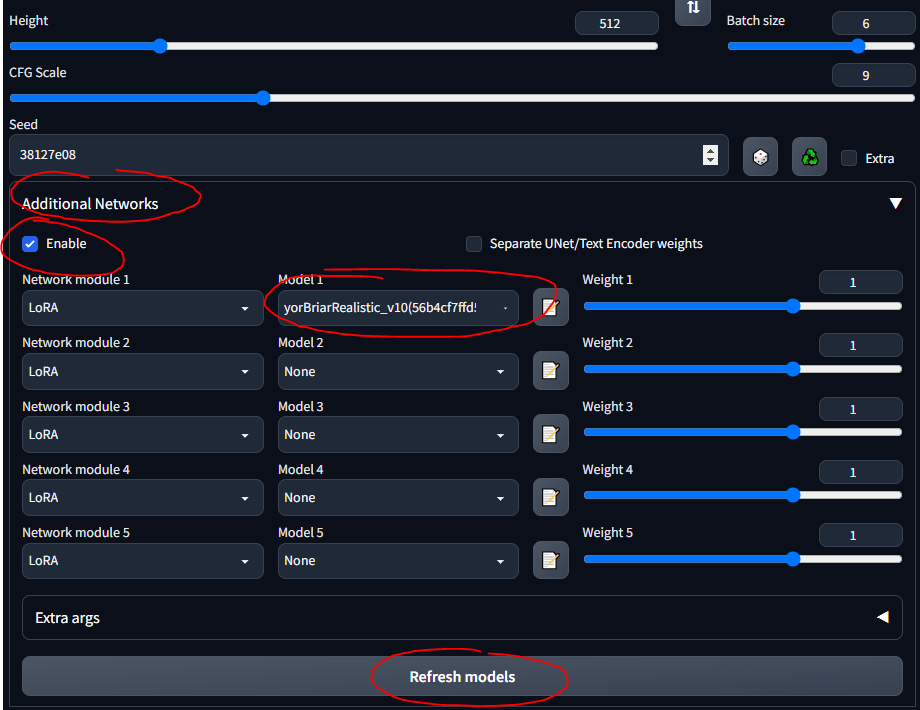
基于上一节...不同的模型有不同的训练数据和训练关键字...因此在某些模型上使用 booru 标签效果不太好。以下是我玩过的一些模型以及它们的“说明”。
SDG Model Motherload,用于获取大部分型号,我只是在这里总结一下说明,以供快速参考;大多数模型都是针对真实色情的,我专注于现实的模型。点击链接查看示例提示、图像以及使用它们的详细说明。
CivitAI 用于获取所有其他内容。您需要注册一个帐户,否则您将无法看到 NSFW 的物品,包括武器和军事装备。在 CivitAI 上,一些模型(检查点)包含 VAE;如果有说明,请也下载它并将其放在模型旁边。
可变自动编码器使图像看起来更好、更清晰、更少过曝。有些还修复手和脸。但这主要是饱和度和阴影的问题。在这里和这里(NSFW)进行了解释。常用的是NovelAI / Anything VAE。它基本上是模型的附加组件,就像 LoRA 一样。
在 VAE 列表中查找 VAE:
stable-diffusion-webuimodelsVAE中以下是我一路上学到的一些一般性注释和有用的东西,不一定符合本指南的时间顺序。
一个好的学习方法是在 CivitAI、AIbooru 或其他 SD 网站(4chan、Reddit 等)上浏览很酷的图像,打开你喜欢的并将生成参数复制到 WebUI 中。全面披露:准确地重新创建图像并不总是可能的,如此处所述。但通常你可以非常接近。要真正发挥作用,请将 CFG 调低,这样模型就可以变得更有创意。尝试分批次,然后离开电脑,回到批次进行挑选。
WebUI工作流程的一般流程是:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
有时您想返回提示而不粘贴图像或从头开始编写它们。您可以保存提示以便在 WebUI 中重复使用它们。
本节或多或少是本指南信息的摘要。
使用已存在的 SD 生成的图像进行工作;也许有人将其发送给您,或者您想重新创建一个您制作的:
stable-diffusion-webuioutputstxt2img-images<date>中请注意,某些网站在上传图像时会删除 PNG 元数据(例如 4chan),因此请查找完整图像的 URL 或使用保留 SD 元数据的网站,例如 CivitAI 或 AIbooru。
我时不时地犯一些错误。大多数内存不足 (VRAM) 错误可通过降低某些参数的值来修复。有时会恢复面孔和员工。修复设置可能会导致此问题。在文件stable-diffusion-webuiwebui-user.bat中,在set COMMANDLINE_ARGS=行上,您可以放置一些修复常见错误的标志。
--disable-nan-check--no-half--medvram或对于土豆计算机,添加--lowvram一个非常常见的问题源于 Python 版本或 Torch 版本不正确。您将收到诸如“无法安装 Torch”或“Torch 找不到 GPU”之类的错误。最简单的修复是:
Python文件夹和Python/Scripts文件夹)stable-diffusion-webui文件夹中的venv文件夹stable-diffusion-webuiwebui-user.bat并让它正确重新构建 venv所有命令行参数都可以在这里找到。
一些扩展可以让 WebUI 更好地使用。获取 Github 链接,转到“扩展”选项卡,从 URL 安装;或者,在“扩展”选项卡中,单击“可用”,然后单击“加载自”,您可以在本地浏览扩展,这反映了扩展 Github wiki。
现在您已经有了一些模型、LoRA 和提示...您如何进行测试以了解哪种效果最好?在“其他网络”窗格下方,有一个“脚本”下拉列表。在这里,单击 X/Y/Z 图。在X类型中,选择Checkpoint name;在 X 值中,单击右侧的按钮以粘贴所有模型。在 Y 类型中,尝试 VAE,或者种子,或者 CFG 规模。无论您选择什么属性,粘贴(或输入)您想要绘制图表的值。例如,如果您有 5 个模型和 5 个 VAE,您将创建一个包含 25 个图像的网格,比较每个模型与每个 VAE 的输出方式。这是非常通用的,可以帮助您决定使用什么。请注意,如果您的 X 或 Y 轴是 VAE 模型,则必须为每个组合加载模型或 VAE 权重,因此可能需要一段时间。
可以在这里找到关于 SD 比较的非常好的资源 (NSFW)。有很多链接可供关注。您可以开始了解各种模型、VAE、LoRA、参数值等如何影响图像生成。
我采用了这里的测试提示,并使用 LoRA 坦克制作了这个 X/Y 网格。您可以看到各种模型和采样器如何相互配合。从这个测试中,我们可以评估:

下面给出了每一张坦克图像所使用的确切参数(不包括模型或采样器)(同样,取自此处):
在本节中,您可以在熟悉使用 WebUI 的 txt2image 选项卡中的模型、LoRA、VAE、提示、参数、脚本和扩展后可以执行的更高级操作。
也称为快速混合。提示编辑允许您让模型更改指定步骤的提示。下图取自 4chan 帖子并描述了该技术。例如,如本指南所述,提示编辑可用于混合面部。
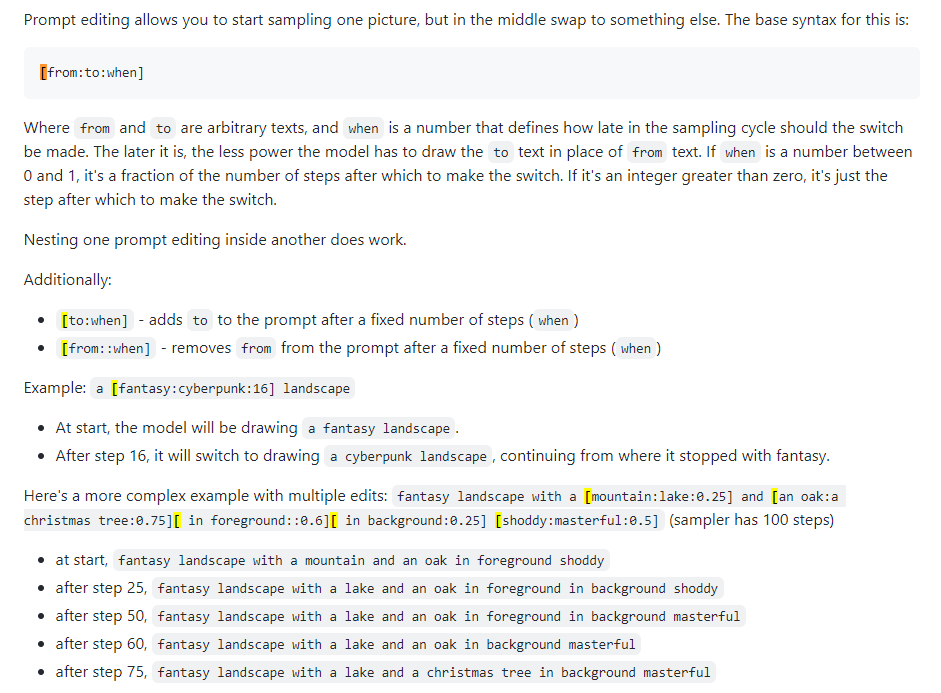
Xformers,或交叉注意层。一种在 Nvidia GPU 上加速图像生成(以秒/迭代或 s/it 为单位)的方法,可以降低 VRAM 使用率,但会导致不确定性。仅当您拥有强大的 GPU 时才考虑这一点;事实上,您需要一台 Quadro。
不太常用,有点令人困惑的选项卡。可用于生成给定草图的图像,例如 Huggingface Image to Image SD Playground 中。该选项卡有一个子选项卡“修复”,这是下一节的主题,也是 WebUI 的一项非常重要的功能。虽然您可以使用本节来生成您已经制作的更改后的图像(输出到stable-diffusion-webuioutputsimg2img-images ),但该功能对我来说很不稳定......它似乎使用了大量的内存并且我几乎无法让它工作。转到下面的下一部分。
这就是内容创建者或对图像扰动感兴趣的人的力量所在。输出位于stable-diffusion-webuioutputsimg2img-images中。
绘制是一个相当复杂的语义过程。外画可以让您拍摄图像并将其扩展任意多次,本质上是增加其边界。此处描述了该过程。您一次只能将图像扩展 64 像素。有两个用于此目的的 UI 工具(我可以找到):
此 WebUI 选项卡专门用于升级。如果您获得了真正喜欢的图像,可以在工作流程结束时在此处对其进行升级。升级后的图像存储在stable-diffusion-webuioutputsextras-images中。在 txt2img 选项卡中生成期间,与使用更强大的放大程序进行放大相关的一些内存问题(例如,4x+ 的图像)不会在这里发生,因为您没有生成新图像,而只是放大静态图像。
理解 ControlNet 功能的最佳方法就像是说“类固醇修复”。你给它一个输入图像(SD 生成的或非 SD 生成的),它可以修改整个图像。 ControlNet 也可以实现姿势。您可以为一个人提供一个参考姿势,并根据您的典型提示生成相应的图像。这里是了解 ControlNet 的良好开端。
stable-diffusion-webuiextensionssd-webui-controlnetmodels

这一切都很好,但有时您需要更好的模型或 LoRA 来实现专业用例。由于大多数 SD 内容实际上是为了生成女性或色情内容,因此可能需要训练特定模型和 LoRA。
请参阅有关 DreamBooth 的部分。
待办事项
WebUI 中的检查点合并选项卡可让您将两个模型组合在一起,就像在锅中混合两种酱汁一样,输出是两者组合的新酱汁。
待办事项
训练 LoRA 并不一定很难,只是收集足够数据的问题。
如果您必须远离设备工作,这是重要的一步。 Google Colab Pro 每月 10 美元,为您提供 89 GB RAM 和优质 GPU,因此从技术上讲,您可以通过手机运行提示,并让它们在廷巴克图的服务器上为您工作。如果你不介意一点额外的费用,Google Colab Pro+ 每月 50 美元,甚至更好。
gdrive/MyDrive/sd/stable-diffusion-webui ,并且从这个基本文件夹中您可以使用您在本地中执行的相同文件夹结构内容网页界面Google Colab 始终免费,您可以永久使用它,但速度可能有点慢。以每月 10 美元的价格升级到 Colab Pro 可为您提供更多功能。但每月 50 美元的 Colab Pro+ 才是真正的乐趣所在。即使关闭选项卡后,Pro+ 仍可让您运行代码 24 小时。
TODO当我将运行时 -> 运行时类型笔记本设置设置为高级 GPU 类别和高 RAM 时,我确实遇到了一个奇怪的错误,该错误破坏了我的 Pro 订阅。这是因为 xFormers 不是基于 CUDA 支持构建的。这可以通过使用 TPU 或禁用 xFormers 来解决,但我现在没有耐心。尝试 Colab 的问题。
MJ对于艺术家来说真的很好。它根本不像 WebUI 中的 SD 那样可扩展或强大(NSFW 是不可能的),但您可以生成一些非常棒的东西。您可以在 MJ Discord 中免费使用它(在他们的网站上注册)以获得一些提示,或者每月支付 8 美元的基本计划,之后您可以在您自己的私人服务器中使用它。所有 Discord 命令都可以在这里和这里找到。 MJ 的提示符结构为:
/imagine <optional image prompt> <prompt> --parameters
这些适用于 MJ V4,与 MJ 5 基本相同。此处描述了所有型号。
待办事项
DreamStudio(不是Dreambooth)是稳定AI公司的旗舰平台。他们的网站是一个平台Dreambooth Studio,您可以从中生成图像。就开放功能而言,它在Midjourney和WebUI之间。 Dreambooth Studio似乎是在Invoke.ai平台上建造的,您可以像WebUI一样在本地安装和运行。
待办事项
稳定的部落是社区的努力,以使每个人免费扩散稳定。从本质上讲,它的作用像洪流或比特币散列,每个人都贡献了一些GPU生成SD含量的功能。可以在此处访问部落应用程序。
待办事项
Dreambooth(不是Dreamstudio)是Google实施了稳定的扩散模型微调技术。简而言之:您可以使用它用自己的图片来训练模型。您可以直接从这里或此处使用它。当您努力实际训练和序列化新模型时,它比仅下载模型并在WebUI中单击更复杂。一些视频总结了如何做:
还有一些好的指南:
Dreambooth的Google Colab:
还有一个称为每个梦的模型培训师。在这里可以找到Dreambooth和Everydream之间的完整比较。
待办事项
从2023年3月开始,可以使用稳定的扩散来生成视频。目前(2023年4月),功能非常简单,因为视频是从类似图像中生成的,逐帧生成,从而使视频具有“翻转书”外观。您可以使用的WebUI有两个主要扩展:您可以使用:
我不太了解的东西,但需要研究
您可以遵循一个过程,以一遍又一遍地获得良好的结果...随着时间的流逝,这将进行完善。
chatgpt集成?
外画
dall-e 2
DeForum https://deforum.github.io/


