evalgpt
1.0.0
?该项目仍处于早期开发阶段,我们正在积极开展工作。如果您有任何问题或建议,请提交问题或 PR。
EvalGPT 是一个代码解释器框架,利用了 GPT-4、CodeLlama 和 Claude 2 等大型语言模型的强大功能。这个强大的工具允许用户编写任务,EvalGPT 将协助编写代码、执行代码并交付结果结果。
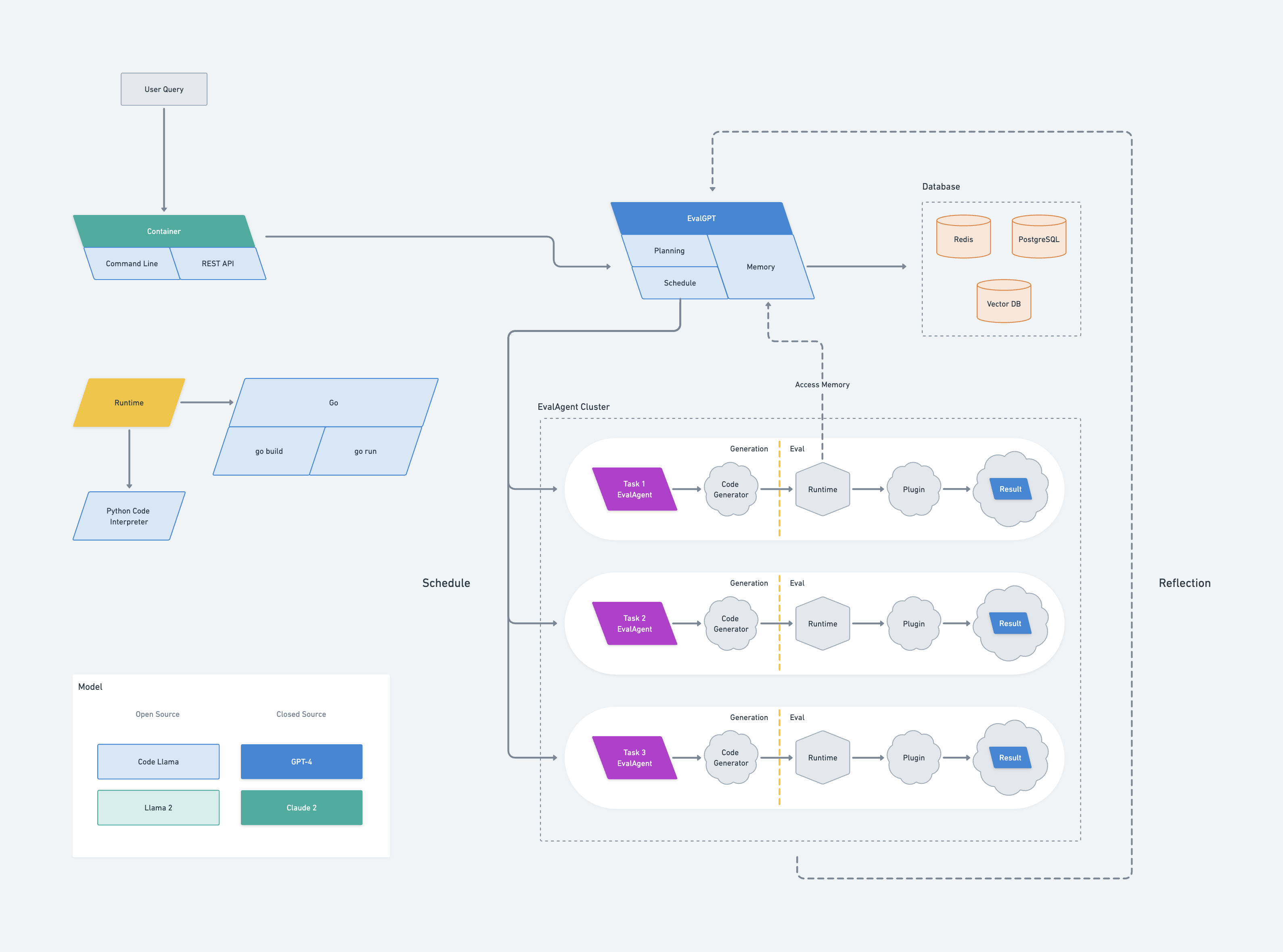
EvalGPT的架构从Google的Borg系统中汲取灵感。它包括一个称为 EvalGPT 的主节点,由三个组件组成:规划器、调度器和内存。
当 EvalGPT 收到请求时,它开始使用大型语言模型 (LLM) 规划任务,将较大的任务划分为较小的、可管理的任务。对于每个子任务,EvalGPT 将生成一个称为 EvalAgent 的新节点。
每个EvalAgent负责根据分配的小任务生成代码。生成代码后,EvalAgent 会启动运行时来执行代码,甚至在必要时利用外部工具。然后 EvalAgent 收集结果。
EvalAgent 节点可以从 EvalGPT 主节点访问内存,从而实现高效且有效的通信。如果EvalAgent在此过程中遇到任何错误,它会将错误报告给EvalGPT主节点,然后EvalGPT主节点重新规划任务以避免错误。
最后,EvalGPT 主节点会整理来自 EvalAgent 节点的所有结果并生成请求的最终答案。
evalgpt您可以使用以下命令安装 evalgpt:
go install github.com/index-labs/evalgpt@latest您可以通过运行以下命令来验证安装:
evalgpt -hgit clone https://github.com/index-labs/evalgpt.git
cd evalgpt
go mod tidy && go mod vendor
mkdir -p ./bin
go build -o ./bin/evalgpt ./ * .go
./bin/evalgpt -h然后就可以在bin目录下找到它了。
安装 evalgpt 命令行后,在执行之前,必须配置以下选项:
配置 Openai API 密钥
export OPENAI_API_KEY=sk_ ******另外,你可以通过命令args配置openai api密钥,但不推荐:
evalgpt --openai-api-key sk_ ***** -q < query >
配置Python解释器
默认情况下,代码解释器使用系统的Python解释器。但是,您可以使用 Python 的虚拟环境工具创建一个全新的 Python 解释器并进行相应的配置。
python3 -m venv /path/evalgpt/venv
# install third python libraries
/path/evalgpt/venv/bin/pip3 install -r requirements.txt
# config python interpreter
export PYTHON_INTERPRETER=/path/evalgpt/venv/bin/python3或者
evalgpt --python-interpreter /path/evalgpt/venv/bin/python3 -q < query >笔记:
在处理复杂的任务之前,请确保安装必要的Python第三方库。这使您的代码解释器能够处理相应的任务,提高效率并确保顺利运行。
帮助
> evalgpt -h
NAME:
evalgpt help - A new cli application
USAGE:
evalgpt help [global options] command [command options] [arguments...]
DESCRIPTION:
description
COMMANDS:
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--openai-api-key value Openai Api Key, if you use open ai model gpt3 or gpt4, you must set this flag [ $OPENAI_API_KEY ]
--model value LLM name (default: " gpt-4-0613 " ) [ $MODEL ]
--python-interpreter value python interpreter path (default: " /usr/bin/python3 " ) [ $PYTHON_INTERPRETER ]
--verbose, -v print verbose log (default: false) [ $VERBOSE ]
--query value, -q value what you want to ask
--file value [ --file value ] the path to the file to be parsed and processed, eg. --file /tmp/a.txt --file /tmp/b.txt
--help, -h show help笔记:
请记住在执行代码解释器之前配置 OpenAI API 密钥和 Python 解释器,以下示例已经配置了 OpenAI API 密钥和 Python 解释器的环境变量。
简单查询
获取机器的公网IP地址:
❯ evalgpt -q ' get the public IP of my computer '
Your public IP is: 104.28.240.133计算字符串的 sha256 哈希值:
❯ evalgpt -q ' calculate the sha256 of the "hello,world" '
77df263f49123356d28a4a8715d25bf5b980beeeb503cab46ea61ac9f3320eda获取网站的标题:
❯ evalgpt -q " get the title of a website: https://arxiv.org/abs/2302.04761 " -v
[2302.04761] Toolformer: Language Models Can Teach Themselves to Use Tools管道
您可以使用管道来输入上下文数据并对其进行查询:
> cat a.csv
date,dau
2023-08-20,1000
2023-08-21,900
2023-08-22,1100
2023-08-23,2000
2023-08-24,1800
> cat a.csv | evalgpt -q ' calculate the average dau '
Average DAU: 1360.0与文件交互
将 png 文件转换为 webp 文件:
> ls
a.png
> evalgpt -q ' convert this png file to webp ' --file ./a.png
created file: a.webp
> ls
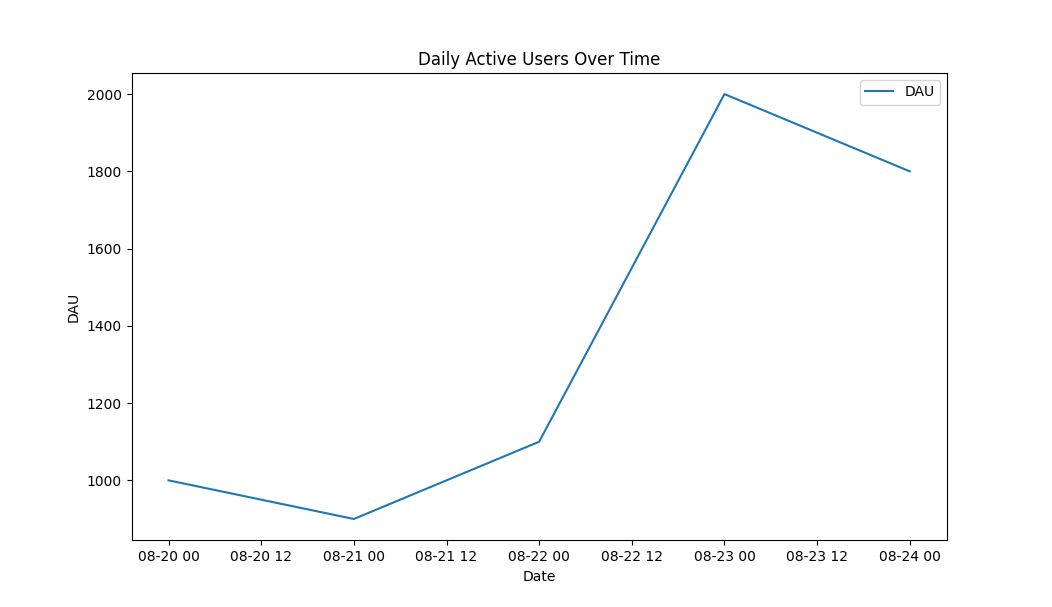
a.png a.webp根据 CSV 中的数据绘制折线图
> cat a.csv
date,dau
2023-08-20,1000
2023-08-21,900
2023-08-22,1100
2023-08-23,2000
2023-08-24,1800
> evalgpt -q ' draw a line graph based on the data from the CSV ' --file ./a.csv输出:
EvalGPT主节点充当框架的控制中心。它包含三个关键组件:规划、调度程序和内存。
规划组件利用大型语言模型根据用户的请求来规划任务。它将复杂的任务分解为更小的、可管理的子任务,每个子任务都由单独的 EvalAgent 节点处理。
调度器组件负责任务分配。它将每个子任务分配给一个EvalAgent节点,确保资源的高效利用和任务的并行执行以获得最佳性能。
内存组件充当所有 EvalAgent 节点的共享内存空间。它存储执行任务的结果,并为不同节点之间的数据交换提供平台。这种共享内存模型有助于复杂的计算,并通过允许在出现错误时重新规划任务来帮助进行错误处理。
如果代码执行过程中出现错误,主节点会重新规划任务以避免错误,从而保证运行的稳健可靠。
最后,EvalGPT主节点收集所有EvalAgent节点的结果,进行编译,生成针对用户请求的最终答案。这种集中控制和协调使得EvalGPT主节点成为EvalGPT框架的重要组成部分。
EvalAgent 节点是 EvalGPT 框架的主力。它们由主节点为每个子任务生成,负责代码生成、执行和结果收集。
EvalAgent 节点中的代码生成过程由分配给它的特定任务指导。使用大型语言模型,它可以生成完成任务所需的代码,确保它适合任务的要求和复杂性。
代码生成后,EvalAgent 节点会启动运行时环境来执行代码。该运行时非常灵活,能够根据需要合并外部工具,并为代码执行提供强大的平台。
在执行过程中,EvalAgent 节点收集结果并可以从 EvalGPT 主节点访问共享内存。这允许有效的数据交换并促进需要大量数据操作或访问先前计算结果的复杂计算。
如果代码执行期间出现任何错误,EvalAgent 节点会将这些错误报告回 EvalGPT 主节点。然后主节点重新计划任务以避免错误,确保稳健可靠的操作。
本质上,EvalAgent 节点是 EvalGPT 框架内的自治单元,能够生成和执行代码、处理错误并有效地传达结果。
EvalGPT 的运行时由 EvalAgent 节点管理。每个 EvalAgent 节点都会生成特定任务的代码并启动运行时来执行代码。运行时环境非常灵活,可以根据需要合并外部工具,提供高度适应性的执行上下文。
运行时还包括错误处理机制。如果 EvalAgent 节点在代码执行期间遇到任何错误,它会将这些错误报告回 EvalGPT 主节点。然后主节点重新规划任务以避免错误,确保代码执行稳健可靠。
运行时可以与EvalGPT主节点的内存交互,从而实现高效的数据交换并促进复杂的计算。这种共享内存模型允许执行需要大量数据操作或访问先前计算结果的任务。


