lightllm
1.0.0
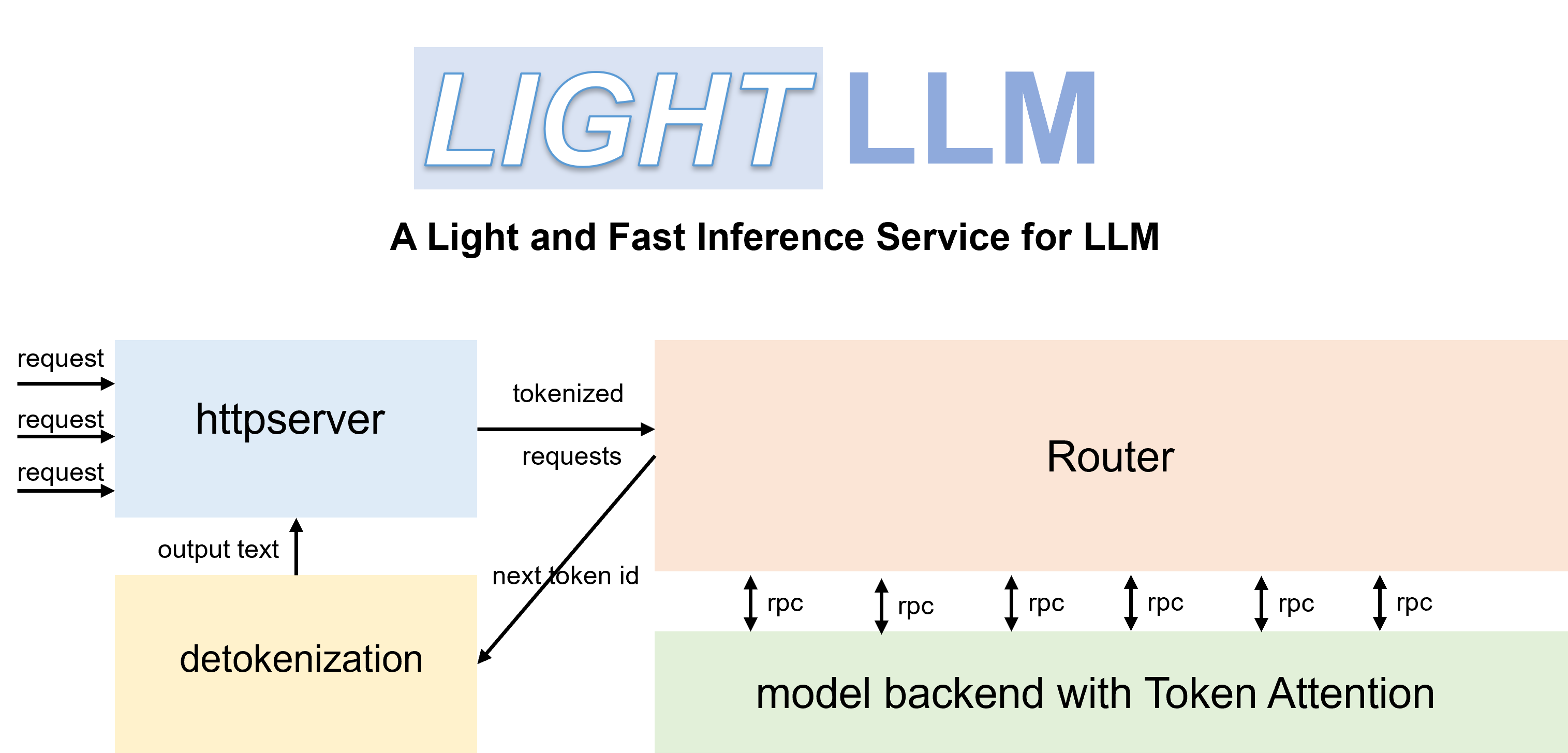
LightLLM 是一个基于 Python 的 LLM(大型语言模型)推理和服务框架,以其轻量级设计、易于扩展和高速性能而著称。 LightLLM 利用了众多备受推崇的开源实现的优势,包括但不限于 FasterTransformer、TGI、vLLM 和 FlashAttention。
英文文档 | 中文文档
启动Qwen-7b时,需要设置参数“--eos_id 151643 --trust_remote_code”。
ChatGLM2需要设置参数'--trust_remote_code'。
InternLM需要设置参数'--trust_remote_code'。
InternVL-Chat(Phi3)需要设置参数'--eos_id 32007 --trust_remote_code'。
InternVL-Chat(InternLM2)需要设置参数'--eos_id 92542 --trust_remote_code'。
Qwen2-VL-7b需要设置参数'--eos_id 151645 --trust_remote_code',并使用'pip install git+https://github.com/huggingface/transformers'升级到最新版本。
Stablelm 需要设置参数“--trust_remote_code”。
Phi-3 仅支持 Mini 和 Small。
DeepSeek-V2-Lite和DeepSeek-V2需要设置参数'--data_type bfloat16'
该代码已使用 Pytorch>=1.3、CUDA 11.8 和 Python 3.9 进行了测试。要安装必要的依赖项,请参阅提供的requirements.txt并按照以下说明进行操作
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5您可以使用官方的Docker容器更轻松地运行模型。为此,请按照下列步骤操作:
从 GitHub 容器注册表中拉取容器:
docker pull ghcr.io/modeltc/lightllm:main运行具有 GPU 支持和端口映射的容器:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bash或者,您可以自己构建容器:
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bash您还可以使用帮助程序脚本来启动容器和服务器:
python tools/quick_launch_docker.py --help注意:如果您使用多个 GPU,则可能需要通过在docker run命令中添加--shm-size来增加共享内存大小。
python setup.py install该代码已在一系列 GPU 上进行了测试,包括 V100、A100、A800、4090 和 H800。如果您在 A100、A800 等上运行代码,我们建议使用 triton==3.0.0。
pip install triton==3.0.0 --no-deps如果您在 H800 或 V100 上运行代码,您可以尝试 triton-nightly 以获得更好的性能。
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-deps借助高效的路由器和 TokenAttention,LightLLM 可以部署为服务并实现最先进的吞吐量性能。
启动服务器:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000参数max_total_token_num受部署环境的 GPU 内存影响。您还可以指定 --mem_faction 以自动计算。
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9要在 shell 中发起查询:
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json '从 Python 查询:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )附加 lanuch 参数:
--enable_multimodal、--cache_capacity、较大的--cache_capacity需要更大的shm-size
支持
--tp > 1,当tp > 1时,视觉模型运行在 gpu 0 上
Qwen-VL 的特殊图像标签是
<img></img>(<image>for Llava),data["multimodal_params"]["images"]的长度应与标签的数量相同,数量可以是 0、1、2、...
输入图像格式:字典列表,如
{'type': 'url'/'base64', 'data': xxx}
我们使用具有 80G GPU 内存的 A800 在 LLaMA-7B 上比较了 LightLLM 和 vLLM==0.1.2 的服务性能。
首先,准备数据如下:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json启动服务:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode auto评估:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200性能对比结果如下:
| 法学硕士 | 轻型法学硕士 |
|---|---|
| 总时间:361.79秒 吞吐量:5.53 个请求/秒 | 总时间:188.85秒 吞吐量:10.59 个请求/秒 |
为了调试,我们为各种模型提供静态性能测试脚本。例如,您可以通过以下方式评估 LLaMA 模型的推理性能
cd test/model
python test_llama.pypip install protobuf==3.20.0来解决此问题。error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ...启动如果您有需要合并的项目,请通过电子邮件联系或创建拉取请求。
一旦你安装了lightllm和lazyllm ,你就可以使用下面的代码来构建你自己的聊天机器人:
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()文档:https://lazyllm.readthedocs.io/
如需更多信息和讨论,请加入我们的不和谐服务器。
该存储库是在 Apache-2.0 许可证下发布的。
在开发 LightLLM 时,我们从以下项目中学到了很多东西。


