CareGPT
1.0.0
中文 | English
视频教程 安装部署 在线体验

⚡特性:
conda create -n llm python=3.11
conda activate llm
python -m pip install -r requirements.txt# 转为HF格式
python -m transformers.models.llama.convert_llama_weights_to_hf
--input_dir path_to_llama_weights --model_size 7B --output_dir path_to_llama_model如果您使用自定义数据集,请务必在 dataset_info.json 文件中以如下格式提供您的数据集定义。
"数据集名称": {
"hf_hub_url": "HuggingFace上的项目地址(若指定,则忽略下列三个参数)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略下列两个参数)",
"file_name": "该目录下数据集文件的名称(若上述参数未指定,则此项必需)",
"file_sha1": "数据集文件的SHA-1哈希值(可选)",
"columns": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)"
}
}其中 prompt 和 response 列应当是非空的字符串。query 列的内容将会和 prompt 列拼接作为模型输入。history 列应当是一个列表,其中每个元素是一个字符串二元组,分别代表用户请求和模型答复。
.txt格式,一行一个无监督数据。
Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.
Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, agriculture, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.[
{
"instruction": "听起来很不错。人工智能可能在哪些方面面临挑战呢?",
"input": "",
"output": "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。",
"history": [
["你好,你能帮我解答一个问题吗?", "当然,请问有什么问题?"],
["我想了解人工智能的未来发展方向,你有什么想法吗?", "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。"]
]
}
][
{
"instruction": "听起来很不错。人工智能可能在哪些方面面临挑战呢?",
"input": "",
"output": "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。",
"history": []
}
][
{
"instruction": "生成三个与“道歉”意思相同的动词",
"input": "",
"output": [
"承认,表示遗憾,弥补。",
"道歉"
]
}
]查看你的显卡是否是NVLINK连接,NVLINK连接才能有效使用accelerate进行并行加速训练。
nvidia-smi topo -m
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)# LLaMA-2
accelerate launch src/train_bash.py
--stage sft
--model_name_or_path ./Llama-2-7b-chat-hf
--do_train
--dataset mm
--finetuning_type lora
--quantization_bit 4
--overwrite_cache
--output_dir output
--per_device_train_batch_size 8
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 2.0
--plot_loss
--fp16
--template llama2
--lora_target q_proj,v_proj
# LLaMA
accelerate launch src/train_bash.py
--stage sft
--model_name_or_path ./Llama-7b-hf
--do_train
--dataset mm,hm
--finetuning_type lora
--overwrite_cache
--output_dir output-1
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 2000
--learning_rate 5e-5
--num_train_epochs 2.0
--plot_loss
--fp16
--template default
--lora_target q_proj,v_proj# LLaMA-2, DPO
accelerate launch src/train_bash.py
--stage dpo
--model_name_or_path ./Llama-2-7b-chat-hf
--do_train
--dataset rlhf
--template llama2
--finetuning_type lora
--quantization_bit 4
--lora_target q_proj,v_proj
--resume_lora_training False
--checkpoint_dir ./output-2
--output_dir output-dpo
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16# LLaMA-2
python src/web_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output
--finetuning_type lora
--template llama2
# LLaMA
python src/web_demo.py
--model_name_or_path ./Llama-7b-hf
--checkpoint_dir output-1
--finetuning_type lora
--template default
# DPO
python src/web_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output-dpo
--finetuning_type lora
--template llama2# LLaMA-2
python src/api_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output
--finetuning_type lora
--template llama2
# LLaMA
python src/api_demo.py
--model_name_or_path ./Llama-7b-hf
--checkpoint_dir output-1
--finetuning_type lora
--template default
# DPO
python src/api_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output-dpo
--finetuning_type lora
--template llama2测试API:
curl -X 'POST'
'http://127.0.0.1:8888/v1/chat/completions'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"model": "string",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"temperature": 0,
"top_p": 0,
"max_new_tokens": 0,
"stream": false
}'# LLaMA-2
python src/cli_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output
--finetuning_type lora
--template llama2
# LLaMA
python src/cli_demo.py
--model_name_or_path ./Llama-7b-hf
--checkpoint_dir output-1
--finetuning_type lora
--template default
# DPO
python src/cli_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output-dpo
--finetuning_type lora
--template llama2# LLaMA-2
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path ./Llama-2-7b-chat-hf
--do_predict
--dataset mm
--template llama2
--finetuning_type lora
--checkpoint_dir output
--output_dir predict_output
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path ./Llama-7b-hf
--do_predict
--dataset mm
--template default
--finetuning_type lora
--checkpoint_dir output-1
--output_dir predict_output
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate# LLaMA-2
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path ./Llama-2-7b-chat-hf
--do_eval
--dataset mm
--template llama2
--finetuning_type lora
--checkpoint_dir output
--output_dir eval_output
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path ./Llama-7b-hf
--do_eval
--dataset mm
--template default
--finetuning_type lora
--checkpoint_dir output-1
--output_dir eval_output
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate在4/8-bit评估时,推荐使用--per_device_eval_batch_size=1和--max_target_length 128
# LLaMA-2
python src/export_model.py
--model_name_or_path ./Llama-2-7b-chat-hf
--template llama2
--finetuning_type lora
--checkpoint_dir output-1
--output_dir output_export
# LLaMA
python src/export_model.py
--model_name_or_path ./Llama-7b-hf
--template default
--finetuning_type lora
--checkpoint_dir output
--output_dir output_export%cd Gradio
python app.py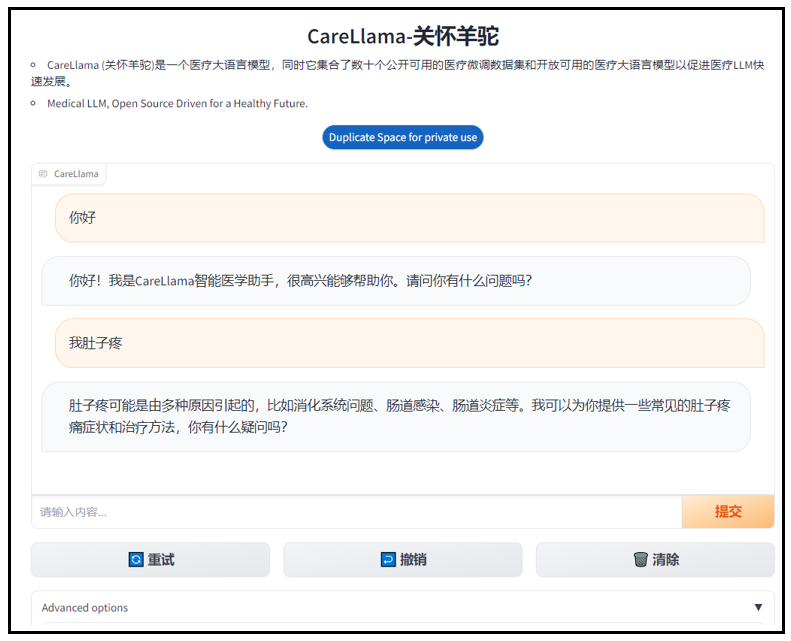
# LLaMA-2
python src/api_demo.py
--model_name_or_path ./Llama-2-7b-chat-hf
--checkpoint_dir output
--finetuning_type lora
--template llama2
# LLaMA
python src/api_demo.py
--model_name_or_path ./Llama-7b-hf
--checkpoint_dir output-1
--finetuning_type lora
--template default设置,修改接口地址为:http://127.0.0.1:8000/(即你的API接口地址),然后就可以使用了。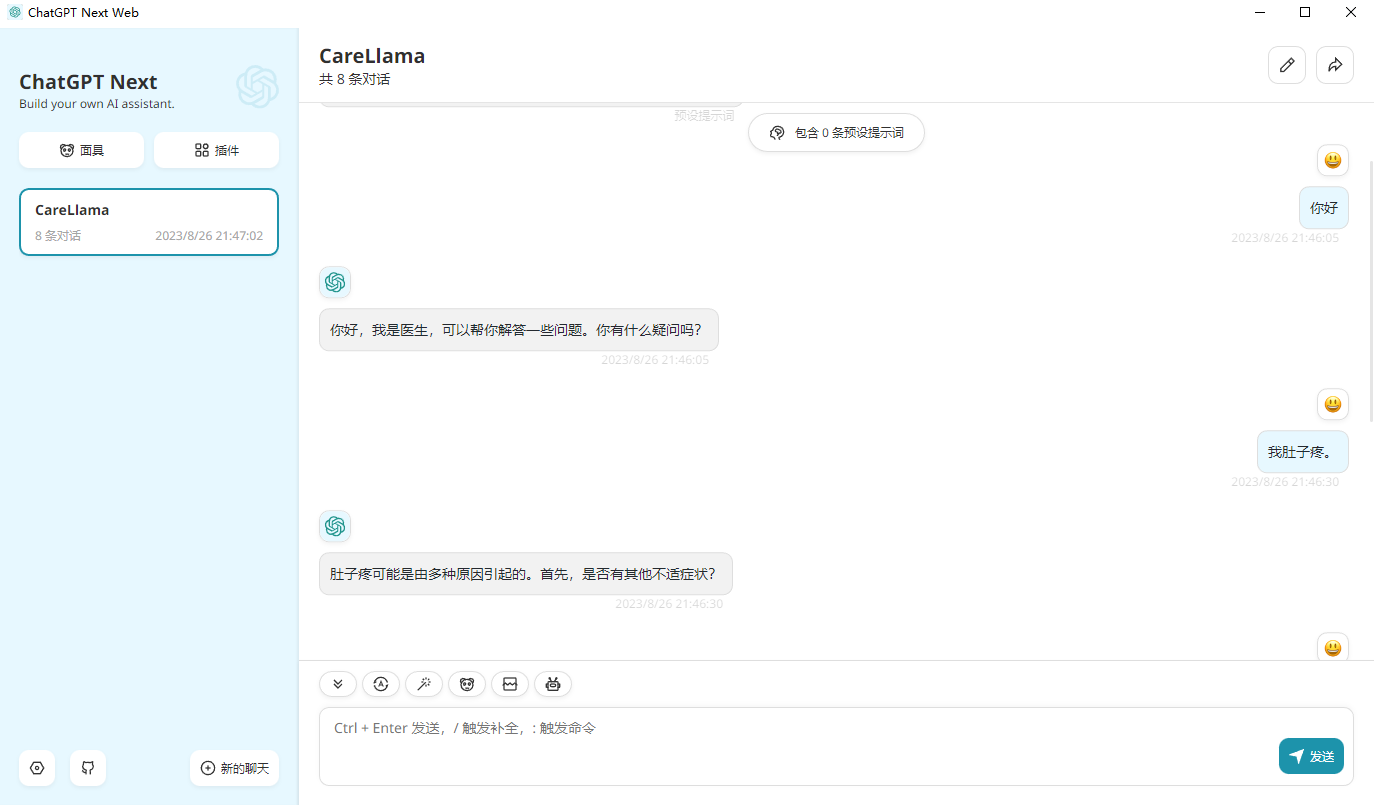
PubMed Central和PubMed Abstracts等。这些宝贵的文本极大地丰富了BLOOMZ模型的医学知识体系,所以很多开源项目都会优先选择BLOOMZ做医学微调的底座模型;质量 > 数量这个真理,如:Less is More! 上交清源 && 里海 | 利用200条数据微调模型,怒超MiniGPT-4!,超大规模的SFT数据会让下游任务LLM减弱或者失去ICL、CoT等能力;大规模预训练+小规模监督微调=超强的LLM模型;英文10B以下选择Mistral-7B中文, 10B以下选择Yi-6B, 10B以上选择Qwen-14B和Yi-34B;Important
欢迎大家在ISSUE中补充新的经验!
11~13方法论来自于130亿大语言模型仅改变1个权重就会完全丧失语言能力!复旦大学自然语言处理实验室最新研究.
14方法论来自于How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
17~25方法论来自LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA) 中文版解读
| 阶段 | 权重介绍 | 下载地址 | 特点 | 底座模型 | 微调方法 | 数据集 |
|---|---|---|---|---|---|---|
| ?监督微调 | 多轮对话数据基于LLaMA2-7b-Chat训练而来 | CareLlama2-7b-chat-sft-multi、?CareLlama2-7b-multi | 出色的多轮对话能力 | LLaMA2-7b-Chat | QLoRA | mm |
| 监督微调 | 丰富高效医患对话数据基于LLaMA2-7b-Chat训练而来 | CareLlama2-7b-chat-sft-med | 出色的患者疾病诊断能力 | LLaMA2-7b-Chat | QLoRA | hm |
| 监 |


