FasterTransformer
v5.3 release
注意:FasterTransformer 开发已过渡到 TensorRT-LLM。我们鼓励所有开发人员利用 TensorRT-LLM 来获得 LLM Inference 的最新改进。 NVIDIA/FasterTransformer 存储库将保持不变,但不会有进一步的开发。
该存储库提供了一个脚本和配方来运行高度优化的基于变压器的编码器和解码器组件,并由 NVIDIA 进行测试和维护。
在 NLP 中,编码器和解码器是两个重要的组件,变压器层成为这两个组件的流行架构。 FasterTransformer 为编码器和解码器实现了高度优化的转换器层以进行推理。在 Volta、Turing 和 Ampere GPU 上,当数据和权重的精度为 FP16 时,会自动使用 Tensor Core 的计算能力。
FasterTransformer 构建在 CUDA、cuBLAS、cuBLASLt 和 C++ 之上。我们提供以下框架的至少一种 API:TensorFlow、PyTorch 和 Triton 后端。用户可以将FasterTransformer直接集成到这些框架中。对于支持框架,我们还提供了示例代码来演示如何使用,并展示这些框架的性能。
| 型号 | 框架 | FP16 | INT8(图灵之后) | 稀疏性(安培之后) | 张量平行 | 管道并联 | FP8(继料斗之后) |
|---|---|---|---|---|---|---|---|
| 伯特 | TensorFlow | 是的 | 是的 | - | - | - | - |
| 伯特 | 火炬 | 是的 | 是的 | 是的 | 是的 | 是的 | - |
| 伯特 | 海卫一后端 | 是的 | - | - | 是的 | 是的 | - |
| 伯特 | C++ | 是的 | 是的 | - | - | - | 是的 |
| XL网 | C++ | 是的 | - | - | - | - | - |
| 编码器 | TensorFlow | 是的 | 是的 | - | - | - | - |
| 编码器 | 火炬 | 是的 | 是的 | 是的 | - | - | - |
| 解码器 | TensorFlow | 是的 | - | - | - | - | - |
| 解码器 | 火炬 | 是的 | - | - | - | - | - |
| 解码 | TensorFlow | 是的 | - | - | - | - | - |
| 解码 | 火炬 | 是的 | - | - | - | - | - |
| GPT | TensorFlow | 是的 | - | - | - | - | - |
| 通用技术/选择 | 火炬 | 是的 | - | - | 是的 | 是的 | 是的 |
| 通用技术/选择 | 海卫一后端 | 是的 | - | - | 是的 | 是的 | - |
| GPT-教育部 | 火炬 | 是的 | - | - | 是的 | 是的 | - |
| 盛开 | 火炬 | 是的 | - | - | 是的 | 是的 | - |
| 盛开 | 海卫一后端 | 是的 | - | - | 是的 | 是的 | - |
| GPT-J | 海卫一后端 | 是的 | - | - | 是的 | 是的 | - |
| 长形器 | 火炬 | 是的 | - | - | - | - | - |
| T5/UL2 | 火炬 | 是的 | - | - | 是的 | 是的 | - |
| T5 | TensorFlow 2 | 是的 | - | - | - | - | - |
| T5/UL2 | 海卫一后端 | 是的 | - | - | 是的 | 是的 | - |
| T5 | 张量RT | 是的 | - | - | 是的 | 是的 | - |
| T5-教育部 | 火炬 | 是的 | - | - | 是的 | 是的 | - |
| 斯温变压器 | 火炬 | 是的 | 是的 | - | - | - | - |
| 斯温变压器 | 张量RT | 是的 | 是的 | - | - | - | - |
| 维特 | 火炬 | 是的 | 是的 | - | - | - | - |
| 维特 | 张量RT | 是的 | 是的 | - | - | - | - |
| GPT-NeoX | 火炬 | 是的 | - | - | 是的 | 是的 | - |
| GPT-NeoX | 海卫一后端 | 是的 | - | - | 是的 | 是的 | - |
| 巴特/巴特 | 火炬 | 是的 | - | - | 是的 | 是的 | - |
| 微网 | C++ | 是的 | - | - | - | - | - |
| 德贝尔塔 | TensorFlow 2 | 是的 | - | - | 正在进行中 | 正在进行中 | - |
| 德贝尔塔 | 火炬 | 是的 | - | - | 正在进行中 | 正在进行中 | - |
具体模型的更多详细信息放在docs/的xxx_guide.md中,其中xxx表示模型名称。一些常见问题和相应的答案放在docs/QAList.md中。请注意,Encoder 和 BERT 的模型类似,我们将说明放在bert_guide.md中。
以下代码列出了FasterTransformer的目录结构:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
请注意,许多文件夹包含许多子文件夹来分割不同的模型。量化工具已转移到examples ,例如examples/tensorflow/bert/bert-quantization/和examples/pytorch/bert/bert-quantization-sparsity/ 。
FasterTransformer提供了一些方便的环境变量用于调试和测试。
FT_LOG_LEVEL :此环境控制调试消息的日志级别。更多详细信息位于src/fastertransformer/utils/logger.h中。请注意,当级别低于DEBUG时,程序会打印大量消息,并且程序会变得非常慢。FT_NVTX :如果将其设置为ON (如FT_NVTX=ON ./bin/gpt_example ,则程序将插入 nvtx 的标记以帮助分析程序。FT_DEBUG_LEVEL :如果设置为DEBUG ,则程序将在每个内核之后运行cudaDeviceSynchronize() 。否则,内核默认异步执行。有助于调试时定位错误点。但这个标志对程序的性能影响很大。因此,它应该仅用于调试。 硬件设置:
为了运行以下基准测试,我们需要安装unix计算工具“bc”:
apt-get install bc通过运行benchmarks/bert/tf_benchmark.sh获得 TensorFlow 的 FP16 结果。
通过运行benchmarks/bert/tf_int8_benchmark.sh获得 TensorFlow 的 INT8 结果。
PyTorch 的 FP16 结果是通过运行benchmarks/bert/pyt_benchmark.sh获得的。
PyTorch的INT8结果是通过运行benchmarks/bert/pyt_int8_benchmark.sh获得的。
更多基准测试放在docs/bert_guide.md中。
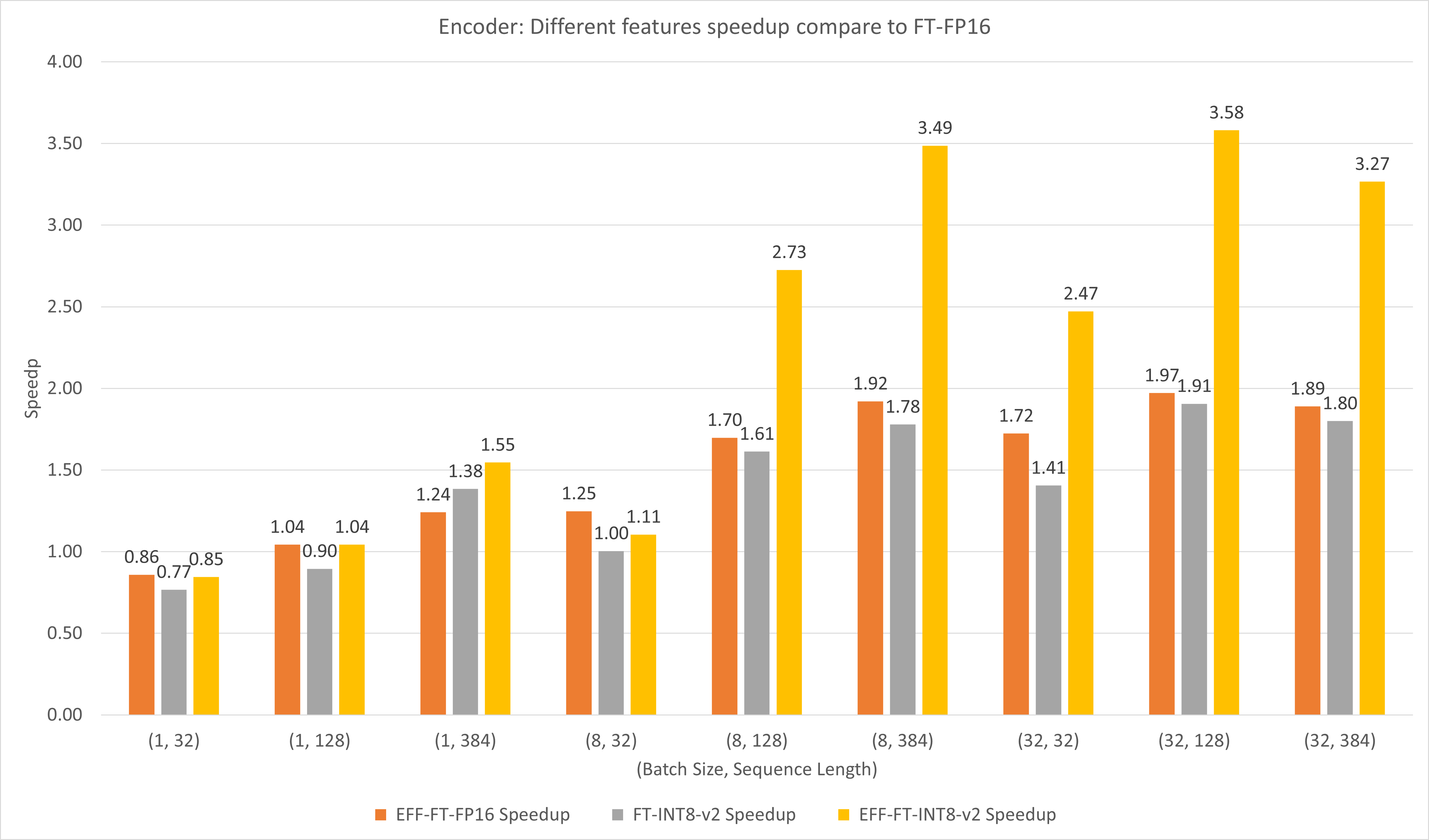
下图比较了FasterTransformer和FasterTransformer在T4上FP16下不同特征的表现。
对于大批量和序列长度,EFF-FT 和 FT-INT8-v2 都带来 2 倍的加速。对于大型案例,同时使用Effective FasterTransformer和int8v2可以比FasterTransformer FP16带来约3.5倍的加速。
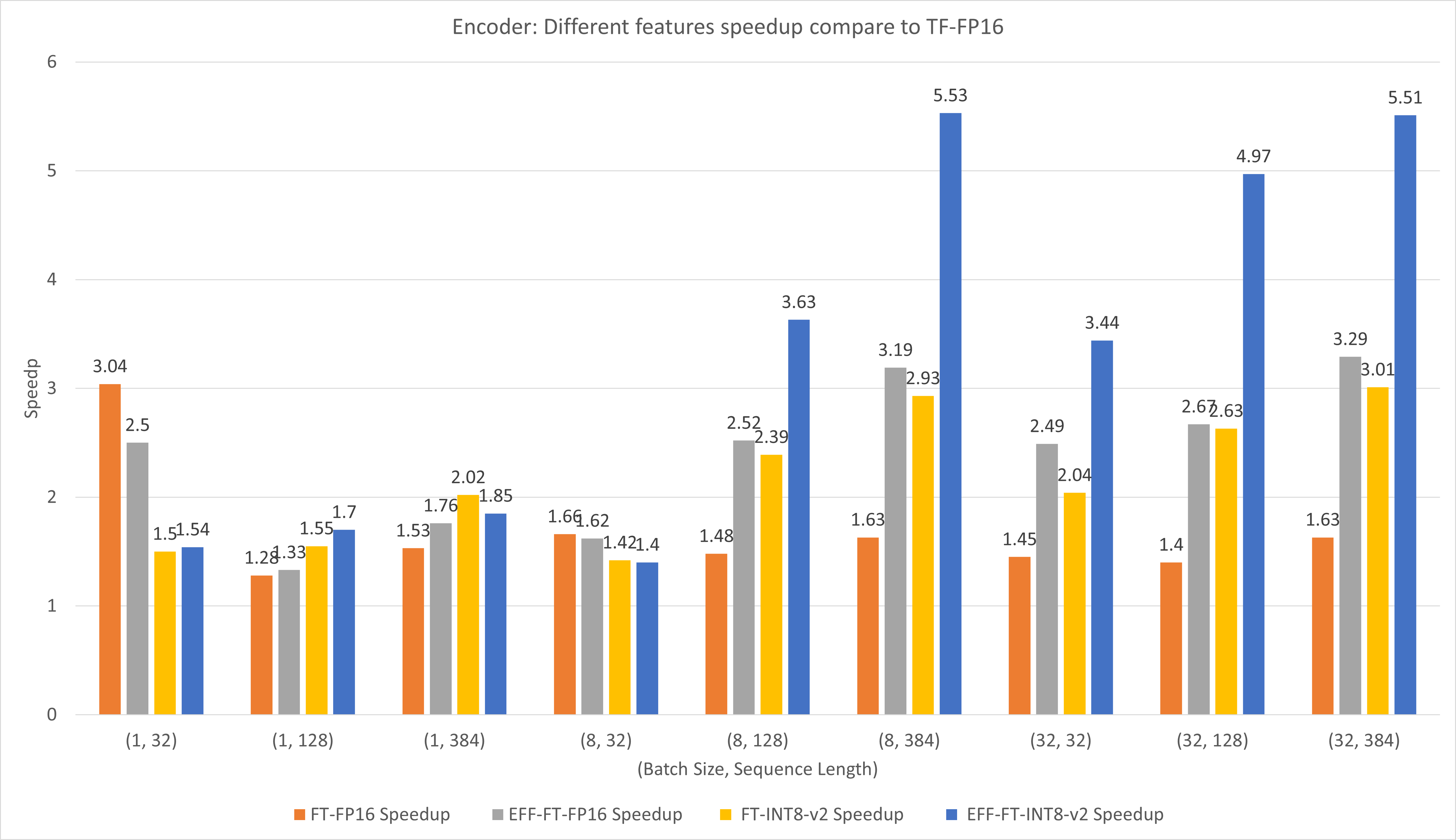
下图比较了FasterTransformer和TensorFlow XLA在T4上FP16下不同特征的表现。
对于小批量和序列长度,使用 FasterTransformer 可以带来约 3 倍的加速。
对于大批量和序列长度,使用有效的 FasterTransformer 和 INT8-v2 量化可以带来约 5 倍的加速。
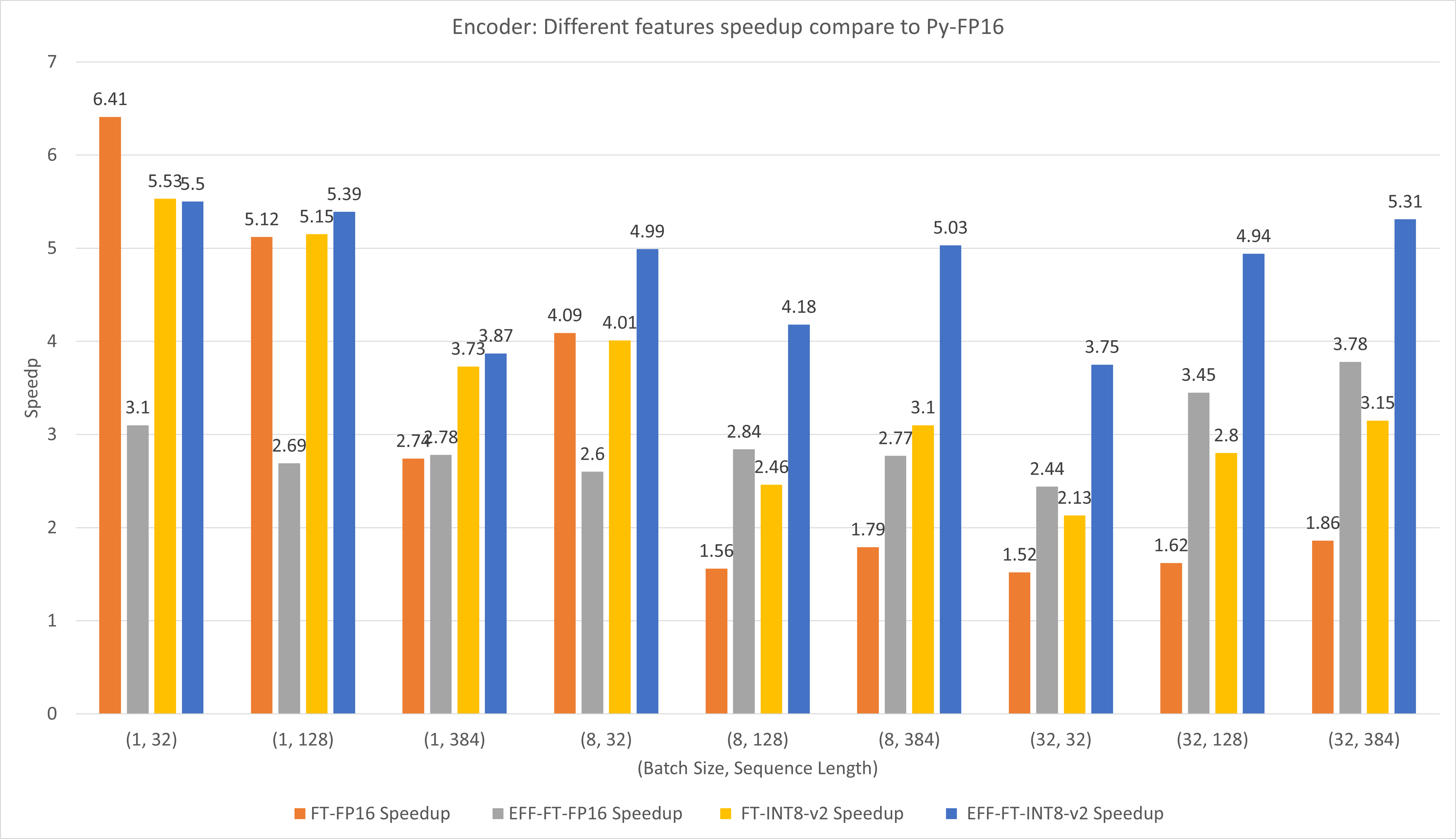
下图比较了FasterTransformer和PyTorch TorchScript在T4上FP16下不同特征的表现。
对于小批量和序列长度,使用 FasterTransformer CustomExt 可以带来约 4x ~ 6x 的加速。
对于大批量和序列长度,使用有效的 FasterTransformer 和 INT8-v2 量化可以带来约 5 倍的加速。
通过运行benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh和benchmarks/decoding/tf_decoding_sampling_benchmark.sh得到 TensorFlow 的结果
PyTorch的结果是通过运行benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh获得的。
在解码实验中,我们更新了以下参数:
更多基准测试放在docs/decoder_guide.md中。
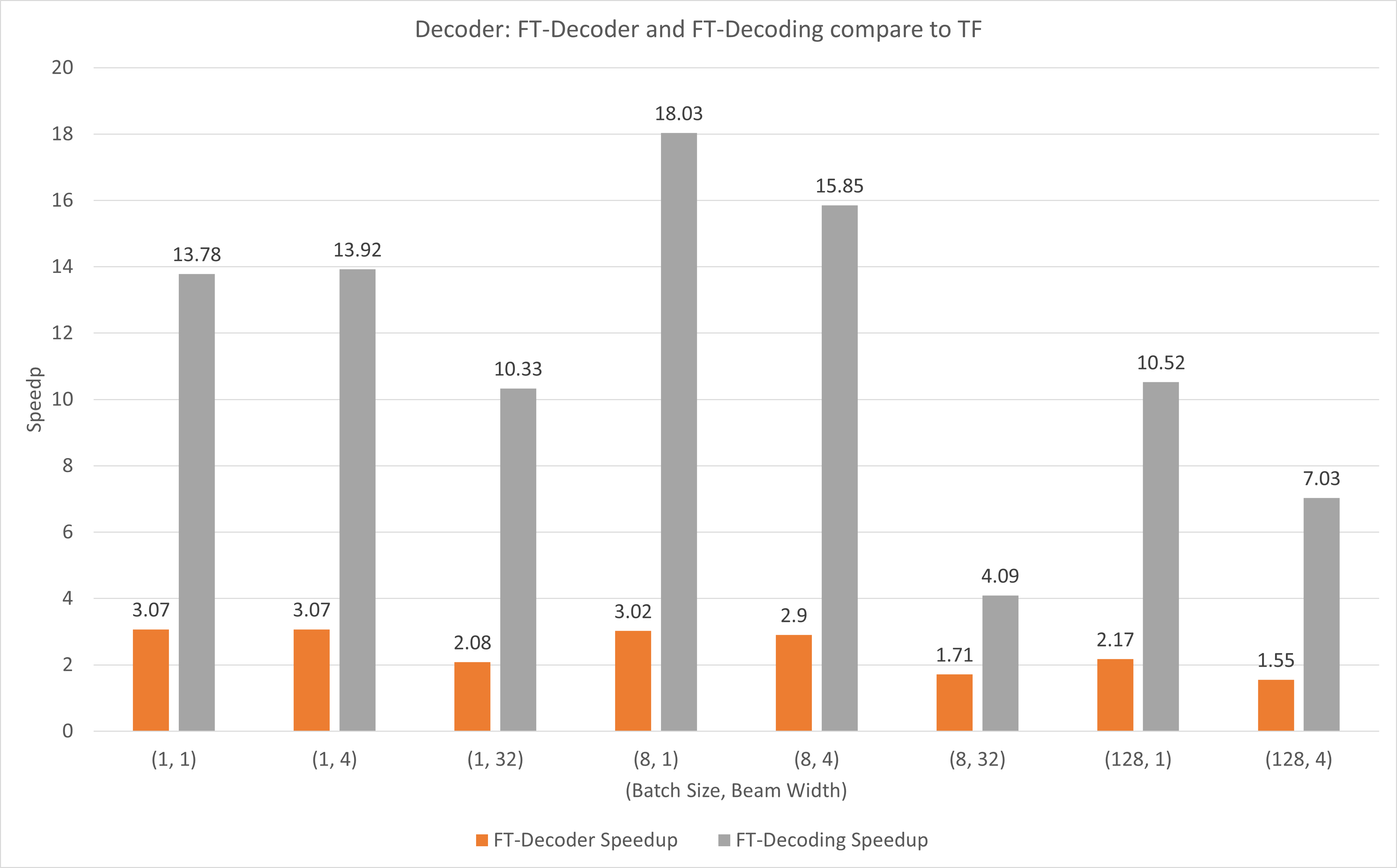
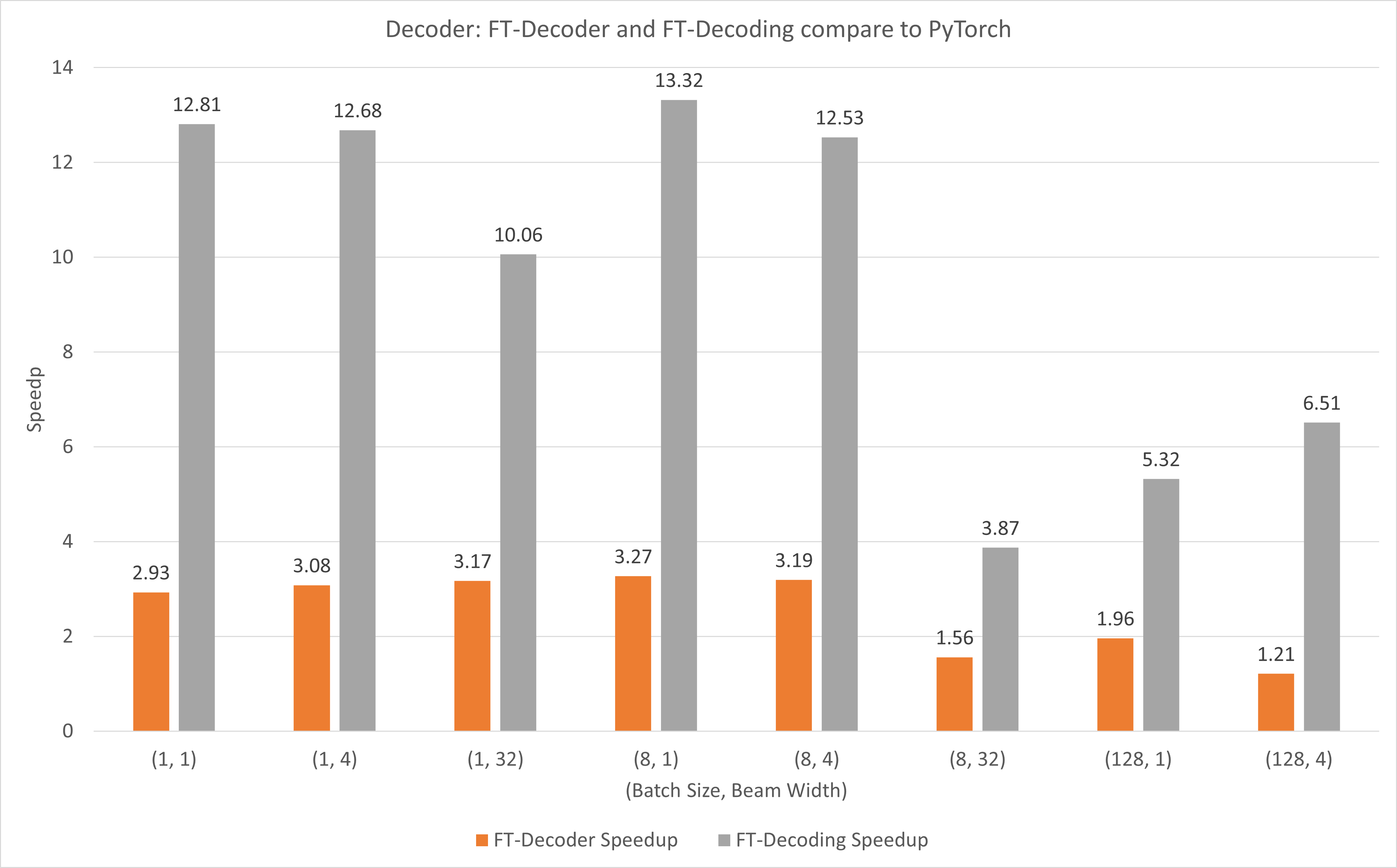
下图显示了 FT-Decoder 操作和 FT-Decoding 操作与 FP16 下 T4 下的 TensorFlow 相比的加速情况。这里,我们使用翻译测试集的吞吐量来防止每种方法的总令牌可能不同。与 TensorFlow 相比,FT-Decoder 提供 1.5x ~ 3x 的加速比;而 FT-Decoding 提供 4x ~ 18x 的加速。
下图显示了 FT-Decoder 操作和 FT-Decoding 操作与使用 T4 的 FP16 下的 PyTorch 相比的加速情况。这里,我们使用翻译测试集的吞吐量来防止每种方法的总令牌可能不同。与 PyTorch 相比,FT-Decoder 提供 1.2x ~ 3x 的加速;而 FT-Decoding 则提供 3.8x ~ 13x 的加速。
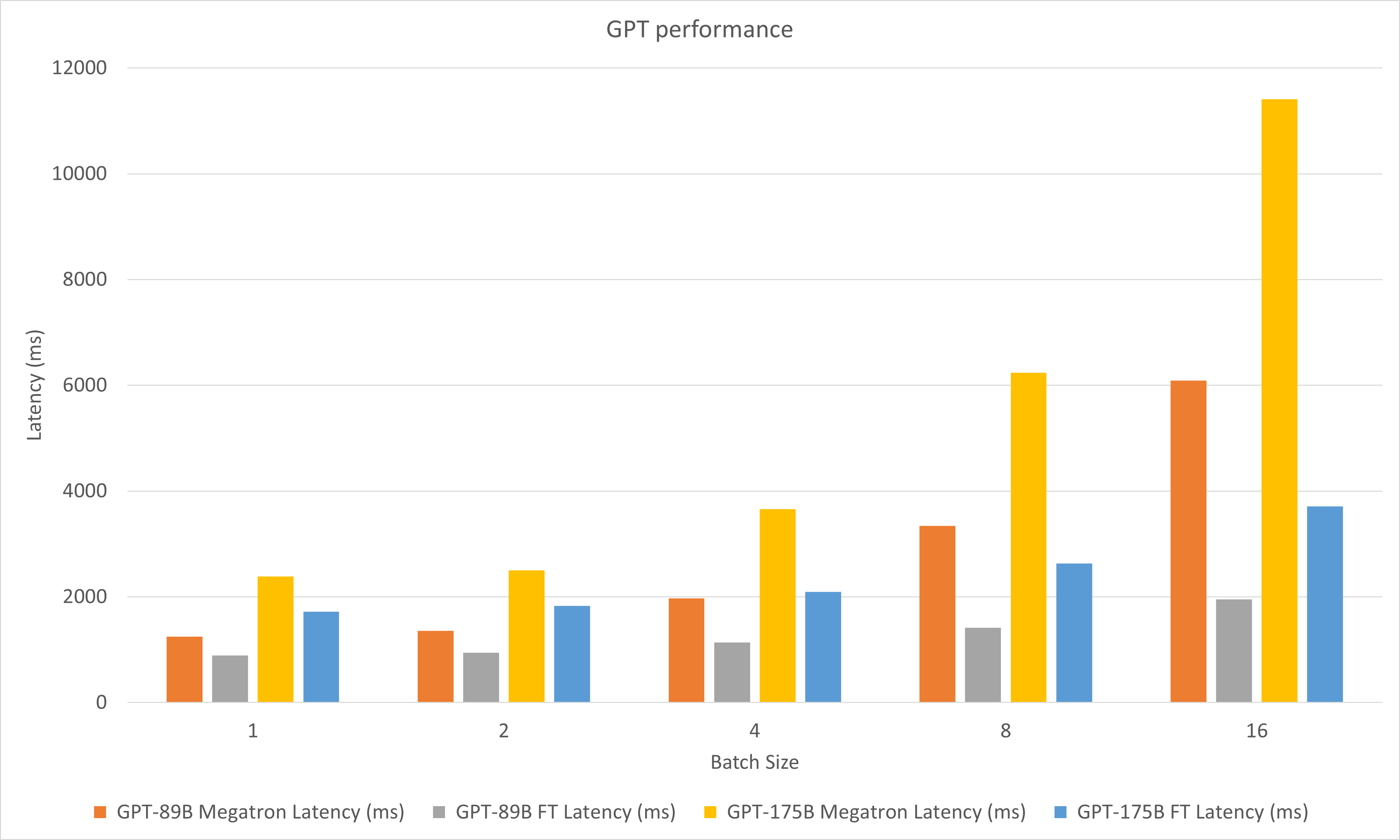
下图对比了A100上FP16下Megatron和FasterTransformer的性能。
在解码实验中,我们更新了以下参数:
2023年5月
2023 年 1 月
2022 年 12 月
2022 年 11 月
2022 年 10 月
2022 年 9 月
2022 年 8 月
2022 年 7 月
2022 年 6 月
2022年5月
2022 年 4 月
2022 年 3 月
stop_ids和ban_bad_ids 。start_id和end_id 。2022 年 2 月
2021 年 12 月
2021 年 11 月
2021 年 8 月
layer_para重命名为pipeline_para 。size_per_head 96、160、192、224、256。2021 年 6 月
2021 年 4 月
2020年12月
2020年11月
2020 年 9 月
2020年8月
2020年6月
2020年5月
translate_sample.py中加载模型的方法。2020年4月
decoding_opennmt.h重命名为decoding_beamsearch.hdecoding_sampling.h中bert_transformer_op.h 、 bert_transformer_op.cu.cc合并到bert_transformer_op.ccdecoder.h 、 decoder.cu.cc合并到decoder.ccdecoding_beamsearch.h 、 decoding_beamsearch.cu.cc合并到decoding_beamsearch.ccbleu_score.py添加到utils中。请注意,BLEU 分数需要 python3。2020年3月
translate_sample.py来演示如何通过恢复OpenNMT-tf的预训练模型来翻译句子。2020年2月
2019年7月
import torch 。如果这样做了,那是由于 C++ ABI 不兼容。你可能需要检查编译和执行过程中使用的PyTorch是否相同,或者你需要检查你的PyTorch是如何编译的,或者你的GCC版本等。

