EasyEdit
1.0.0

易于使用的大型语言模型知识编辑框架。
安装 • 快速入门 • 文档 • 论文 • 演示 • 基准测试 • 贡献者 • 幻灯片 • 视频 • AK 精选
2024年10月23日,EasyEdit集成了从转向编辑到减轻LLM和MLLM幻觉的受限解码方法,详细信息可在DoLa和DeCo中找到。
2024年9月26日,??我们的论文《WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models》已被NeurIPS 2024接收。
2024年9月20日,??我们的论文:《Knowledge Mechanisms in Large Language Models: A Survey and Perspective》和《Editing Conceptual Knowledge for Large Language Models》已被EMNLP 2024Findings接收。
2024年7月29日,EasyEdit添加了新的模型编辑算法EMMET,将ROME推广到批量设置。这本质上允许使用 ROME 损失函数进行批量编辑。
2024-07-23,我们发布了一篇新论文:“Knowledge Mechanisms in Large Language Models: A Survey and Perspective”,回顾了知识在大型语言模型中是如何获取、利用和演化的。这项调查可能为法学硕士中精确有效地操纵(编辑)知识提供基本机制。
2024年6月4日,?? EasyEdit Paper 已被ACL 2024系统演示轨道接受。
2024-06-03,我们发布了一篇题为“WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models”的论文,并介绍了一种新的编辑任务:连续知识编辑以及相应的终身编辑方法WISE。
2024-04-24,EasyEdit 宣布支持Llama3-8B 的 ROME 方法。建议用户将其 Transformer 软件包更新至版本 4.40.0。
2024-03-29,EasyEdit 引入了对 GRACE 的回滚支持。详细介绍请参考EasyEdit文档。未来的更新将逐渐包括对其他方法的回滚支持。
2024年3月22日,发布了题为“通过知识编辑对大型语言模型进行解毒”的新论文,以及名为 SafeEdit 的新数据集和名为 DINM 的新解毒方法。
2024年3月12日,另一篇题为“Editing Conceptual Knowledge for Large Language Models”的论文发布,介绍了一个名为ConceptEdit的新数据集。
2024-03-01,EasyEdit 添加了对名为FT-M的新方法的支持。该方法涉及使用目标答案的交叉熵损失来训练特定的 MLP 层并屏蔽原始文本。它的性能优于罗马的FT-L实施。感谢第 173 期的作者提供的建议。
2024年2月27日,EasyEdit增加了对名为InstructEdit的新方法的支持,技术细节在论文“InstructEdit:基于指令的大型语言模型知识编辑”中提供。
Accelerate 。大型语言模型知识编辑的综合研究[论文][基准][代码]
IJCAI 2024 教程 Google 云端硬盘
COLING 2024 教程 Google 云端硬盘
AAAI 2024 教程 Google 云端硬盘
AACL 2023教程【Google Drive】【百度盘】
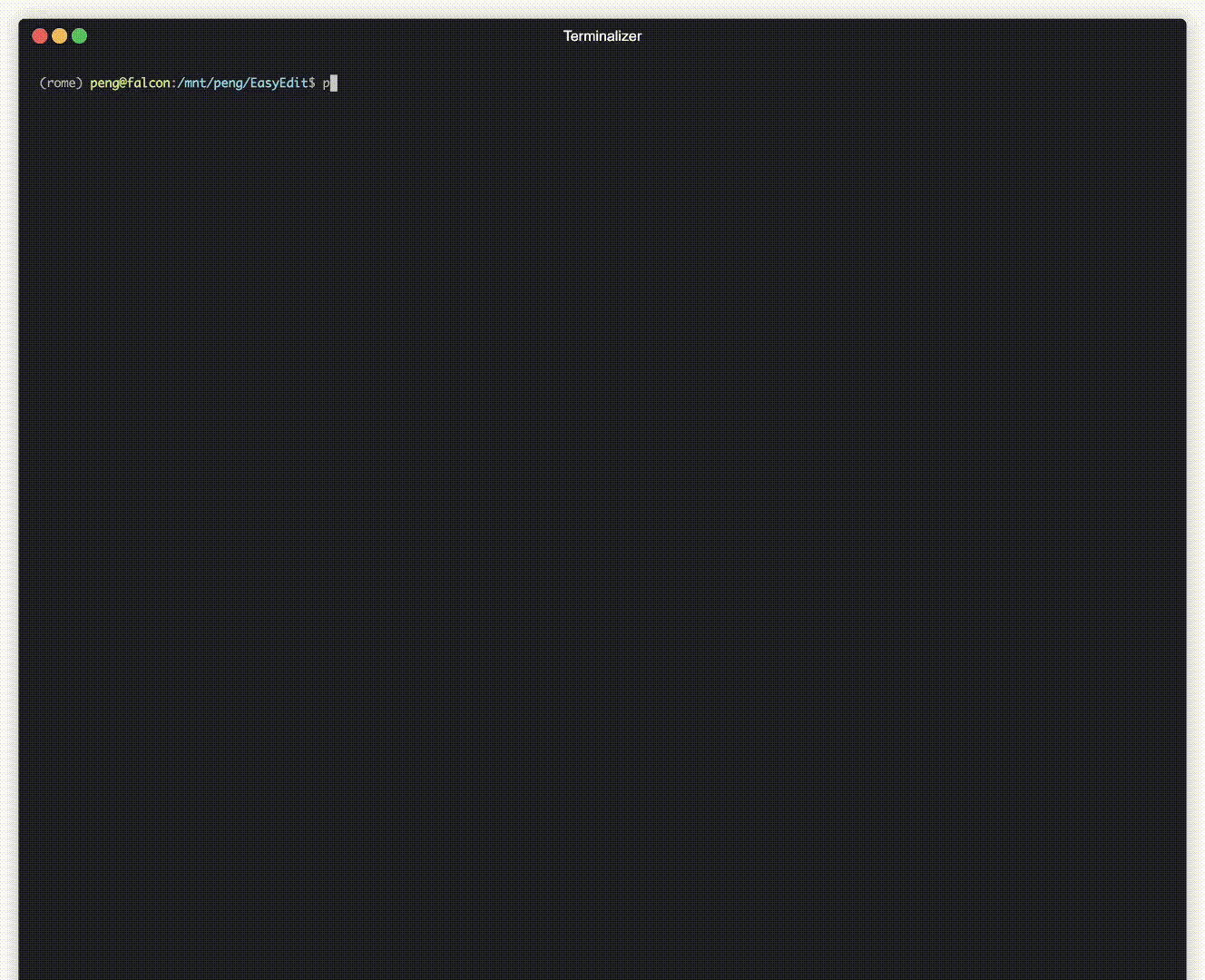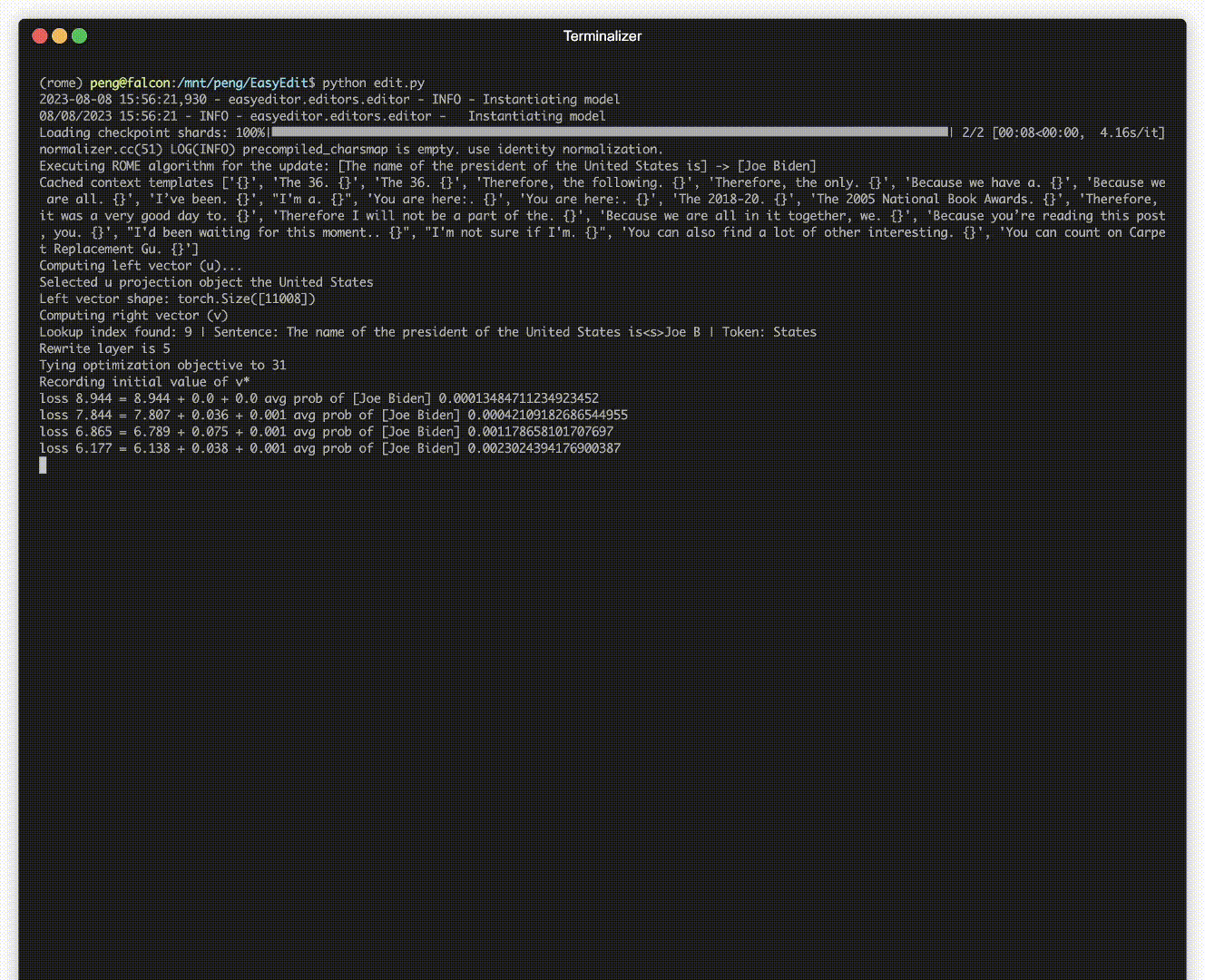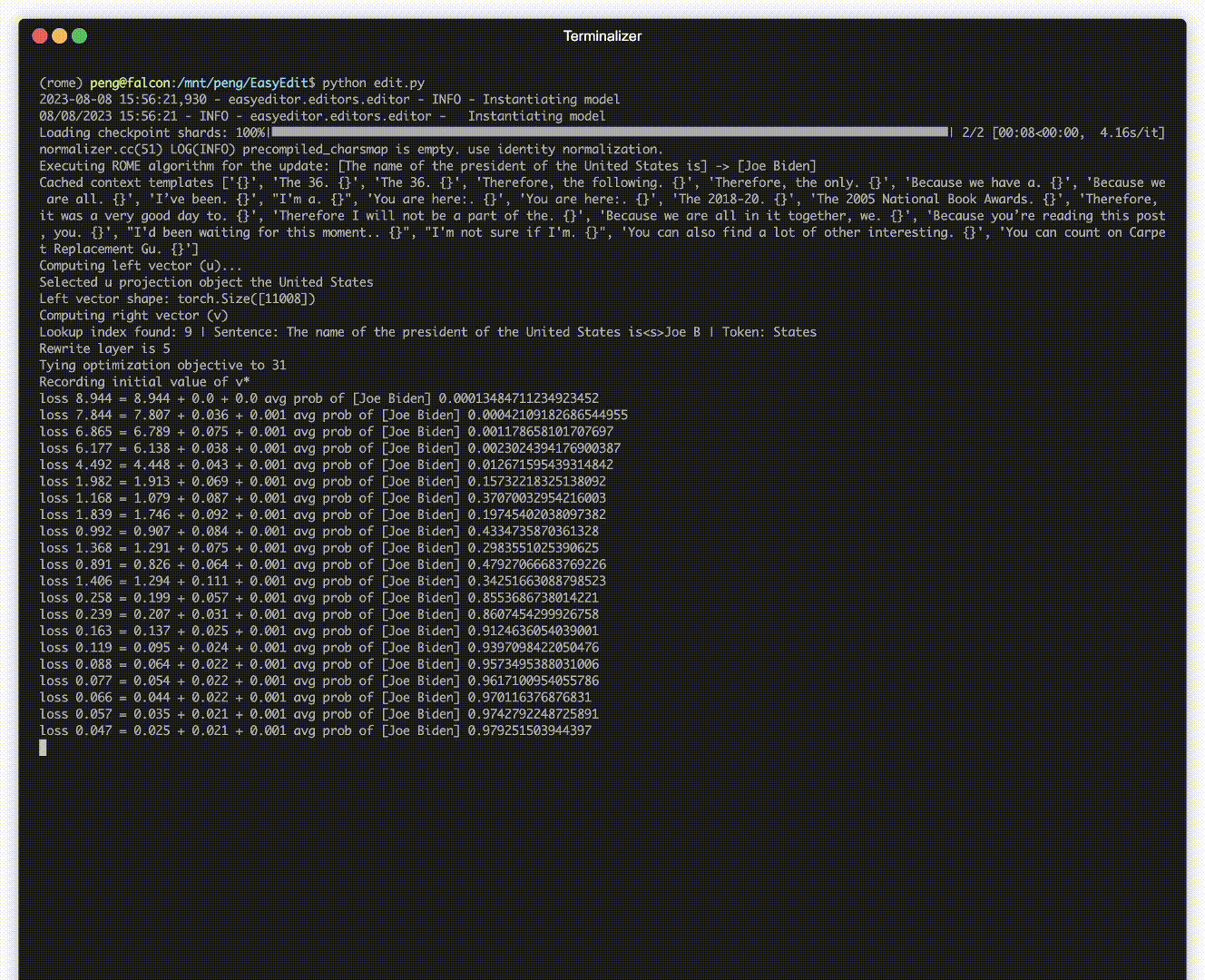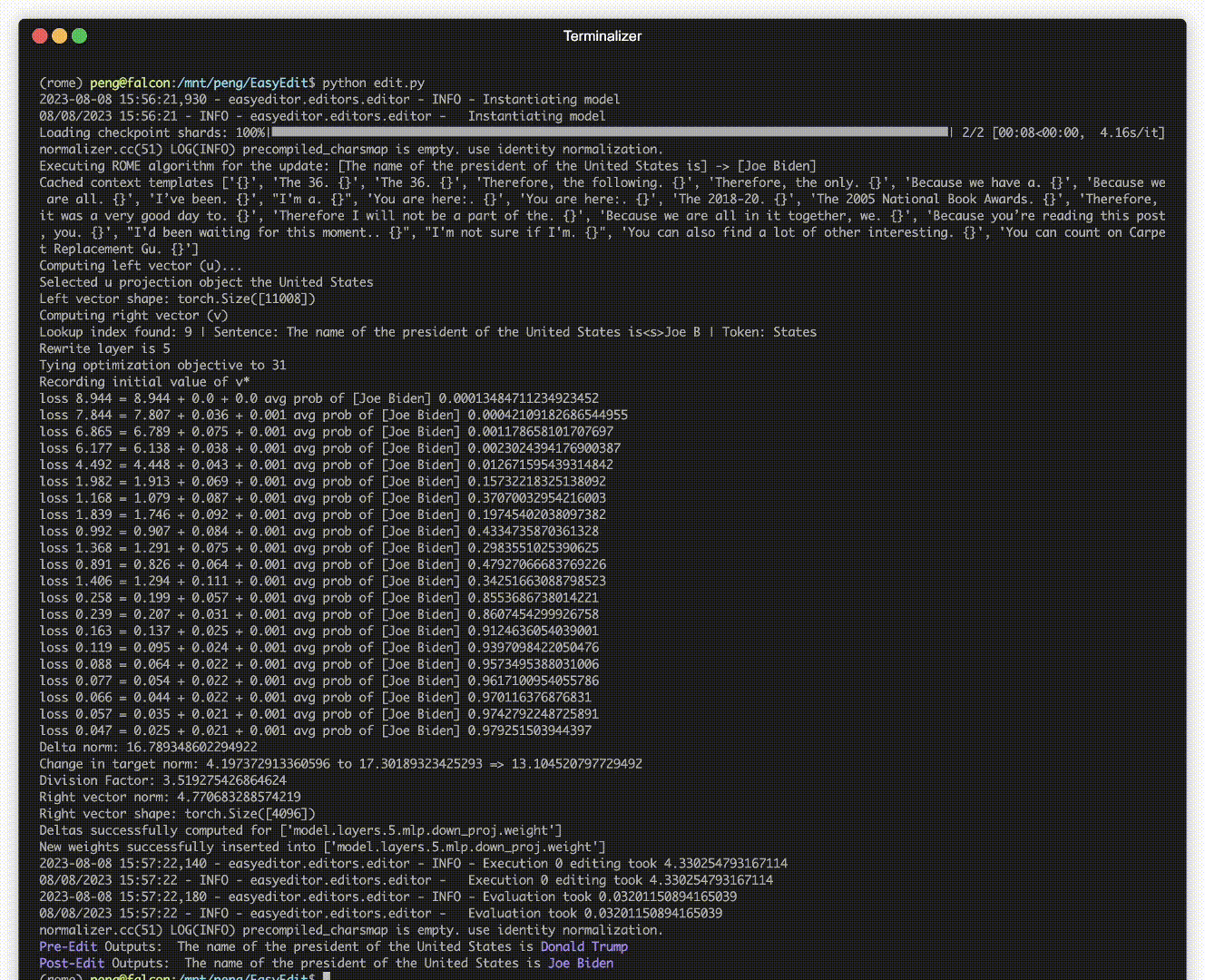
有编辑演示。 GIF 文件是由 Terminalizer 创建的。
我们提供了一个方便的 Jupyter Notebook!它允许您编辑法学硕士对美国总统的了解,从拜登切换到特朗普,甚至回到拜登。这包括 WISE、AlphaEdit、AdaLoRA 和基于提示的编辑等方法。
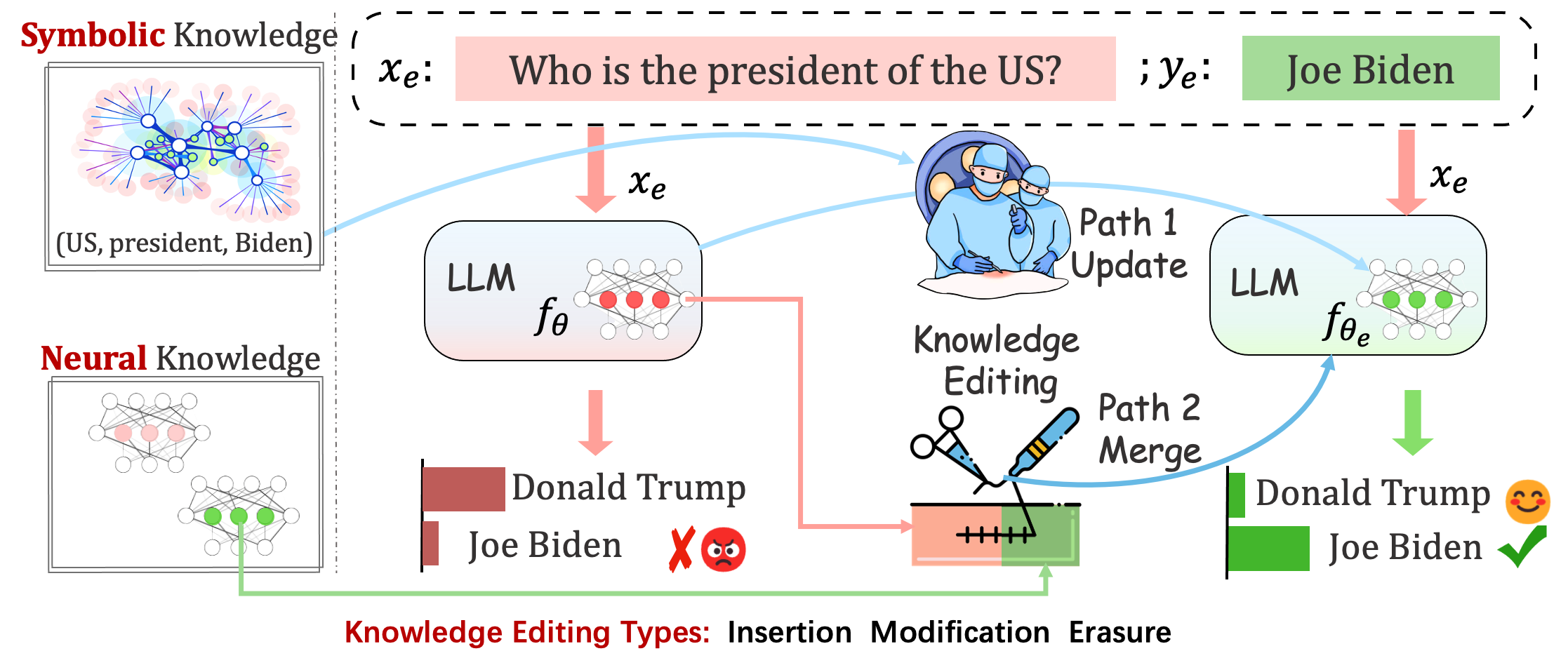
部署的模型仍然可能会出现不可预测的错误。例如,众所周知,法学硕士会产生幻觉、延续偏见和事实衰退,因此我们应该能够调整预训练模型的特定行为。
知识编辑的目的是调整基础模型的
在单次编辑后评估模型的性能。在一次编辑后,模型会重新加载原始权重(例如 LoRA 丢弃适配器权重)。你应该设置sequential_edit=False
这需要顺序编辑,并在应用所有知识更新后进行评估:
它进行参数调整sequential_edit=True :README(了解更多详细信息)。
在不影响不相关样本上的模型行为的情况下,最终目标是创建编辑后的模型
图像字幕和视觉问答的编辑任务。自述文件
鉴于个人的观点可以反映其人格特质的各个方面,拟议的任务通过编辑法学硕士对特定主题的观点来初步尝试编辑他们的个性。我们利用已建立的“五大”理论作为构建数据集和评估法学硕士个性表达的基础。自述文件
评估
基于Logits
基于世代的
当评估Acc和TPEI时,您可以从这里下载经过训练的分类器。
知识编辑过程通常会影响与编辑示例密切相关的一组广泛输入的预测,称为编辑范围。
成功的编辑应该在编辑范围内调整模型的行为,同时保留不相关的输入:
Reliability :使用给定编辑描述符进行编辑的成功率Generalization :编辑范围内编辑的成功率Locality :模型的输出在编辑不相关的输入后是否发生变化Portability :推理/应用编辑的成功率(一跳、同义词、逻辑概括)Efficiency :时间和内存消耗EasyEdit 是一个用于编辑大型语言模型 (LLM) 的 Python 包,例如GPT-J 、 Llama 、 GPT-NEO 、 GPT2 、 T5 (支持从1B到65B 的模型),其目标是在特定领域而不会对其他输入的性能产生负面影响。它被设计为易于使用且易于扩展。
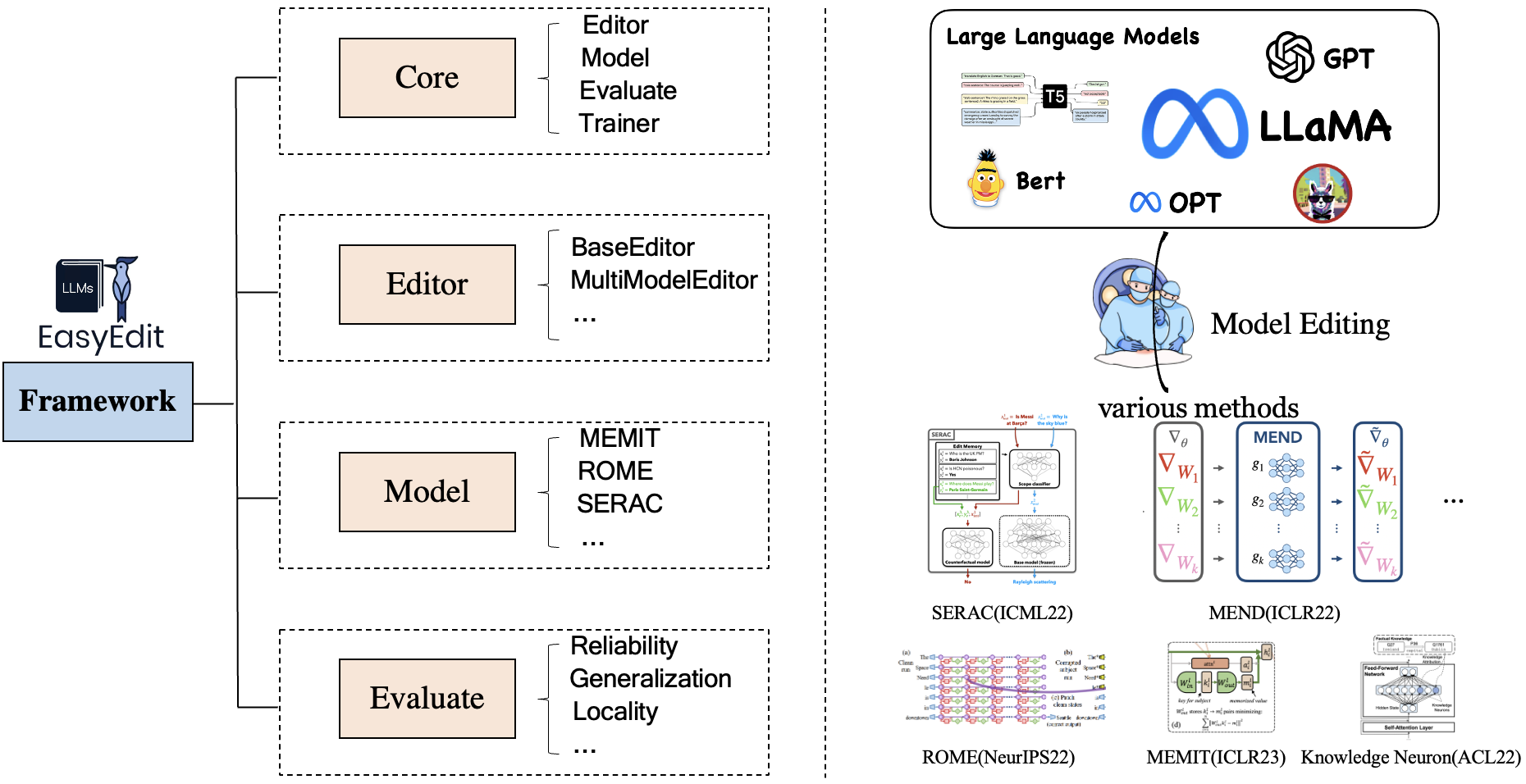
EasyEdit 包含统一的Editor 、 Method和Evaluate框架,分别代表编辑场景、编辑技术和评估方法。
每个知识编辑场景都包含三个组件:
Editor :例如LM的BaseEditor(事实知识和生成编辑器),MultiModalEditor(多模态知识)。Method :所使用的具体知识编辑技术(例如ROME 、 MEND 、..)。Evaluate :评估知识编辑性能的指标。Reliability , Generalization , Locality , Portability目前支持的知识编辑技术如下:
注1:由于该工具包兼容性有限,不支持T-Patcher、KE、CaliNet等部分知识编辑方法。
注2:同样,由于同样的原因,MALMEN方法仅部分支持,并将继续改进。
您可以根据您的具体需求选择不同的编辑方式。
| 方法 | T5 | GPT-2 | GPT-J | GPT-NEO | 骆驼 | 百川 | 聊天GLM | 实习生LM | 奎文 | 米斯特拉尔 |
|---|---|---|---|---|---|---|---|---|---|---|
| 金融时报 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 阿达洛拉 | ✅ | ✅ | ||||||||
| 塞拉克 | ✅ | ✅ | ✅ | ✅ | ||||||
| IKE | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 修补 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| 罗马 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| 罗马 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| 梅特 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| 埃米特 | ✅ | ✅ | ✅ | |||||||
| 优雅 | ✅ | ✅ | ✅ | |||||||
| 梅洛 | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| 指示编辑 | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| 明智的 | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| Alpha编辑 | ✅ | ✅ | ✅ |
❗️❗️如果您打算使用Mistral,请手动将
transformers库更新到4.34.0版本。您可以使用以下代码:pip install transformers==4.34.0。
| 工作 | 描述 | 小路 |
|---|---|---|
| 指示编辑 | InstructEdit:大型语言模型的基于指令的知识编辑 | 快速入门 |
| DINM | 通过知识编辑消除大型语言模型的毒害 | 快速入门 |
| 明智的 | WISE:重新思考大型语言模型终身模型编辑的知识记忆 | 快速入门 |
| 概念编辑 | 编辑大型语言模型的概念知识 | 快速入门 |
| MM编辑 | 我们可以编辑多模态大型语言模型吗? | 快速入门 |
| 性格编辑 | 编辑大型语言模型的个性 | 快速入门 |
| 迅速的 | 基于PROMPT的知识编辑方法 | 快速入门 |
基准测试:KnowEdit [抱脸][WiseModel][ModelScope]
❗️❗️需要说明的是, KnowEdit是通过重新组织和扩展现有数据集(包括WikiBio 、 ZsRE 、 WikiData Counterfact 、 WikiDataRecent 、 Consent 、 Sanitation)构建的,对知识编辑进行综合评估。特别感谢这些数据集的构建者和维护者。
请注意,Counterfact 和 WikiData Counterfact不是同一个数据集。
| 任务 | 知识插入 | 知识修改 | 知识擦除 | |||
|---|---|---|---|---|---|---|
| 数据集 | 维基最近 | ZsRE | 维基百科 | 维基数据反事实 | 康文森特 | 卫生 |
| 类型 | 事实 | 问答 | 幻觉 | 反事实 | 情绪 | 不需要的信息 |
| # 火车 | 第570章 | 10,000 | 第592章 | 1,455 | 14,390 | 80 |
| # 测试 | 1,266 | 1301 | 1,392 人 | 第885章 | 800 | 80 |
我们提供了详细的脚本供用户轻松使用KnowEdit,请参考示例。
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| 数据集 | 抱脸 | 智慧模型 | 模型范围 | 描述 |
|---|---|---|---|---|
| 知道编辑 | [拥抱脸] | [智慧模型] | [模型范围] | 中文知识编辑数据集 |
CKnowEdit是一个高质量的中文知识编辑数据集,具有很强的中文特色,所有数据均来源于中文知识库。它经过精心设计,旨在更深入地洞察当前法学硕士在理解中文方面固有的细微差别和挑战,为法学硕士内精炼中文特定知识提供了强大的资源。
CKnowEdit中数据的字段说明如下:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| 数据集 | 谷歌云端硬盘 | 百度网盘 | 描述 |
|---|---|---|---|
| ZsRE加 | [谷歌云端硬盘] | [百度网盘] | 使用问题改写的问答数据集 |
| 反事实加 | [谷歌云端硬盘] | [百度网盘] | 使用实体替换的 Counterfact 数据集 |
我们提供 zsre 和 counterfact 数据集来验证知识编辑的有效性。您可以在这里下载它们。 [谷歌云端硬盘]、[百度网盘]。
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse等一对一关系的评价| 数据集 | 谷歌云端硬盘 | HuggingFace 数据集 | 描述 |
|---|---|---|---|
| 概念编辑 | [谷歌云端硬盘] | [HuggingFace 数据集] | 用于编辑概念知识的数据集 |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
概念特定评估指标
Instance Change :捕获这些实例级更改的复杂性Concept Consistency :生成的概念定义的语义相似度| 数据集 | 谷歌云端硬盘 | 百度网盘 | 描述 |
|---|---|---|---|
| 电子集成电路 | [谷歌云端硬盘] | [百度网盘] | 用于编辑图像字幕的数据集 |
| 电子质量保证 | [谷歌云端硬盘] | [百度网盘] | 用于编辑视觉问答的数据集 |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| 数据集 | HuggingFace 数据集 | 描述 |
|---|---|---|
| 安全编辑 | [HuggingFace 数据集] | 法学硕士解毒数据集 |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
排毒具体评估指标
Defense Duccess (DS) :对抗性输入(攻击提示+有害问题)编辑LLM的解毒成功率,用于修改LLM。Defense Generalization (DG) :编辑后的LLM对域外恶意输入的解毒成功率。General Performance :不相关任务表现的副作用。 | 方法 | 描述 | GPT-2 | 骆驼 |
|---|---|---|---|
| IKE | 情境学习 (ICL) 编辑 | [Colab-gpt2] | [Colab-llama] |
| 罗马 | 定位然后编辑神经元 | [Colab-gpt2] | [Colab-llama] |
| 梅特 | 定位然后编辑神经元 | [Colab-gpt2] | [Colab-llama] |
注意:EasyEdit 请使用 Python 3.9+要开始使用,只需安装 conda 并运行:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txt我们的结果都是基于默认配置
| 骆驼-2-7B | 聊天glm2 | GPT-J-6B | GPT-XL | |
|---|---|---|---|---|
| 金融时报 | 60GB | 58GB | 55GB | 7GB |
| 塞拉克 | 42GB | 32GB | 31GB | 10GB |
| IKE | 52GB | 38GB | 38GB | 10GB |
| 修补 | 46GB | 37GB | 37GB | 13GB |
| KN | 42GB | 39GB | 40GB | 12GB |
| 罗马 | 31GB | 29GB | 27GB | 10GB |
| 梅特 | 33GB | 31GB | 31GB | 11GB |
| 阿达洛拉 | 29GB | 24GB | 25GB | 8GB |
| 优雅 | 27GB | 23GB | 6GB | |
| 明智的 | 34GB | 27GB | 7GB |
编辑大型语言模型 (LLM) 大约5 秒
以下示例向您展示如何使用 EasyEdit 进行编辑。更多示例和教程可以在示例中找到
BaseEditor是语言模态知识编辑的类。您可以根据您的具体需求选择合适的编辑方法。
凭借EasyEdit的模块化和灵活性,您可以轻松地使用它来编辑模型。
步骤1:定义一个PLM作为要编辑的对象。选择要编辑的 PLM。 EasyEdit支持在 HuggingFace 上检索部分模型(到目前为止T5 、 GPTJ 、 GPT-NEO 、 LlaMA )。对应的配置文件目录为hparams/YUOR_METHOD/YOUR_MODEL.YAML ,如hparams/MEND/gpt2-xl.yaml ,设置对应的model_name来选择知识编辑的对象。
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingStep2:选择合适的知识编辑方法
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )Step3:提供编辑描述符和编辑目标
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ]第四步:将它们组合成一个BaseEditor EasyEdit提供了一种简单且统一的方式来初始化Editor ,例如 Huggingface: from_hparams 。
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )步骤5:提供评估数据注意,可移植性和局部性的数据都是可选的(设置为“无”仅用于基本编辑成功率评估)。两者的数据格式都是dict ,对于每个测量维度,都需要提供相应的提示及其对应的groundtruth。以下是数据示例:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}在上面的例子中,我们评估了有关“邻里”和“分散注意力”的编辑方法的性能。
Step6:编辑和评估完成!我们可以对您要编辑的模型进行编辑和评估。 edit功能将返回一系列与编辑过程相关的指标以及修改后的模型权重。 [ sequential_edit=True表示连续编辑]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelEasyEdit 的最大输入长度为 512。如果超过此长度,您将遇到错误“CUDA 错误:设备端断言已触发”。您可以在以下文件中修改最大长度:LINK
步骤7:回滚在连续编辑中,如果您对其中一项编辑的结果不满意并且不希望丢失之前的编辑,可以使用回滚功能来撤消之前的编辑。目前,我们仅支持GRACE方法。您需要做的只是一行代码,使用 edit_key 来恢复您的编辑。
editor.rolllback('edit_key')
在 EasyEdit 中,我们默认使用 target_new 作为 edit_key
我们将返回指标指定为dict格式,包括编辑前后的模型预测评估。对于每次编辑,它将包含以下指标:
rewrite_acc rephrase_acc locality portablility 

