mengzi retrieval lm
1.0.0
在Langboat Technology,我们专注于增强预训练模型,使其更轻,以满足实际的行业需求。基于检索的方法(如 RETRO、REALM 和 RAG)对于实现这一目标至关重要。
该存储库是检索增强语言模型的实验性实现。目前仅支持GPT-Neo上的检索拟合。
我们分叉了 Huggingface Transformers 和 lm-evaluation-harness 以添加检索支持。索引部分实现为HTTP服务器,以更好地解耦检索和训练。
大部分模型实现是从 RETRO-pytorch 和 GPT-Neo 复制的。我们使用transformers-cli在GPT-Neo的基础上添加一个名为Re_gptForCausalLM的新模型,然后向其添加检索部分。
我们使用 200G 检索库上传了安装在 EleutherAI/gpt-neo-125M 上的模型。
您可以像这样初始化模型:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )并像这样评估模型:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1我们使用句子转换器的嵌入作为文本表示来计算相似度。您可以像这样初始化 Sentence-BERT 模型:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )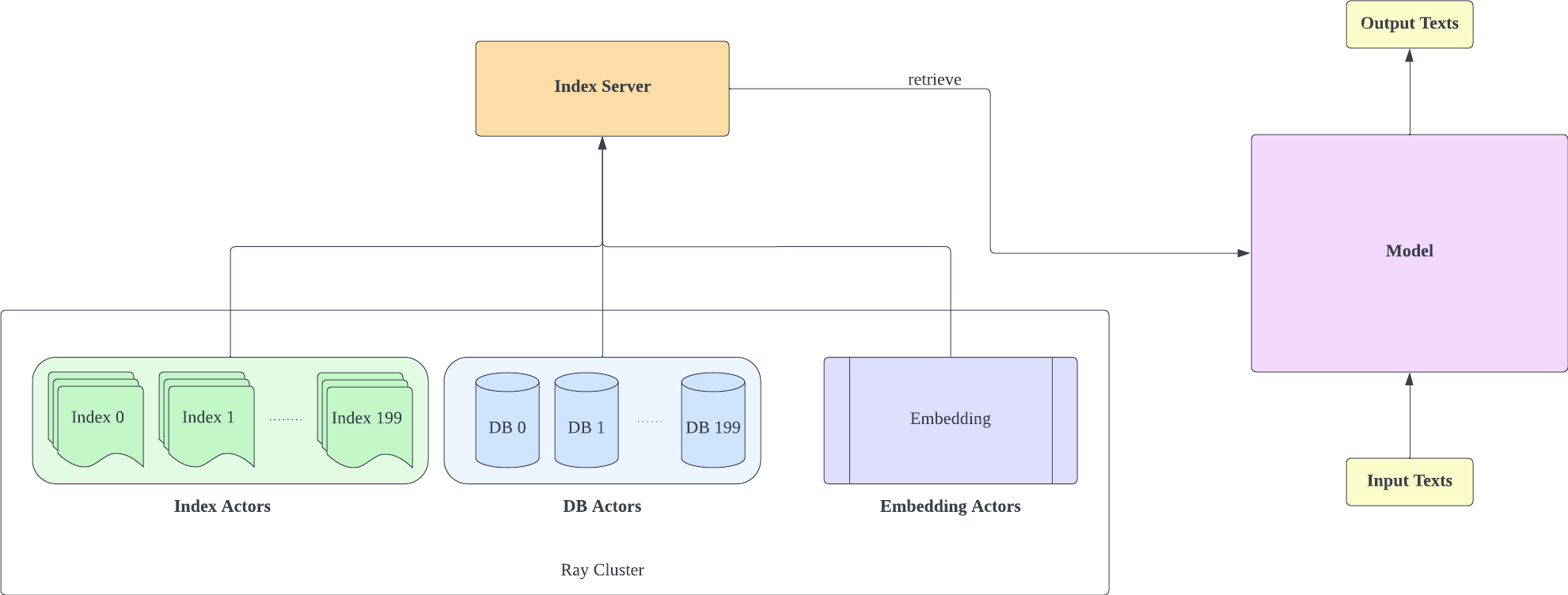
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " 使用IVF1024PQ48作为faiss索引工厂,我们将索引和数据库上传到huggingface模型中心,可以使用以下命令下载。
在download_index_db.py中,您可以指定要下载的索引和数据库的数量。
python -u download_index_db.py --num 200您可以从这里手动下载拟合模型:https://huggingface.co/Langboat/ReGPT-125M-200G
索引服务器基于FastAPI和Ray。通过 Ray 的 Actor,计算密集型任务被异步封装,使我们只需一个 FastAPI 服务器实例即可高效利用 CPU 和 GPU 资源。您可以像这样初始化索引服务器:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- 请记住,配置 IVF1024PQ48.json 分片计数必须与下载的索引数匹配。可以在db_path下查看当前下载的索引号
- 此配置已在 A100-40G 上进行了测试,因此如果您有不同的 GPU,我们建议根据您的硬件进行调整。
- 部署索引服务器后,需要修改 lm-evaluation-harness/config.json 和 train/config.json 中的 request_server 。
- 您可以减少config_IVF1024PQ48.json中的encoder_actor_count来减少所需的内存资源。
· db_path:huggingface 数据库的下载位置。 “../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966”就是一个示例。
该命令将从 Huggingface 下载数据库和索引数据。
更改配置文件 (config IVF1024PQ48) 中的索引文件夹以指向索引文件夹的路径,并将数据库文件夹的快照作为 db 路径发送到 api.py 脚本。
使用以下命令停止索引服务器
ray stop
- 请记住,您需要在训练、评估和推理期间保持索引服务器启用
使用train/train.py实现训练;可以修改train/config.json来更改训练参数。
您可以像这样初始化训练:
cd train
python -u train.py
- 由于索引服务器需要使用内存资源,因此最好将索引服务器和模型训练部署在不同的GPU上
使用 train/inference.py 作为推理来确定文本的丢失及其困惑度。
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- data文件夹中的test_data.json和train_data.json是目前支持的文件格式,您可以将您的数据修改为该格式。
使用 lm-evaluation-harness 作为评估方法
我们将 lm-evaluation-harness 的 seq_len 设置为 1025 作为模型比较的初始设置,因为我们模型训练的 seq_len 是 1025。
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:拟合模型路径
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1评估结果如下
| 模型 | 维基文本 word_perplexity |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| 浪舟/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| 浪舟/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

