graph gpt
v0.4.0
该存储库是 PyTorch 中“GraphGPT:使用生成式预训练 Transformers 进行图学习”的官方实现。
GraphGPT:使用生成式预训练 Transformer 进行图学习
赵其芳、任卫东、李天宇、徐潇潇、刘红
2024年10月13日
CHANGELOG.md了解详细信息。2024年8月18日
CHANGELOG.md了解详细信息。2024年7月9日
2024年3月19日
permute_nodes ,以增加欧拉路径的变化,并产生更好、更稳健的结果。StackedGSTTokenizer使得语义(即节点/边属性)标记可以与结构标记堆叠在一起,并且序列的长度将减少很多。2024年1月23日
2024年1月3日

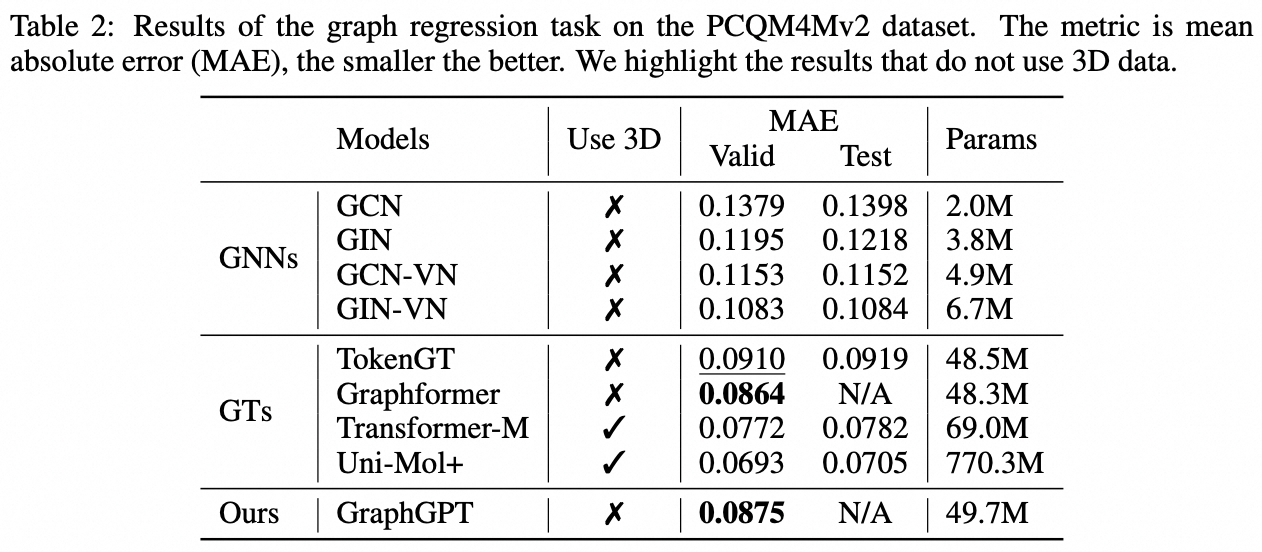
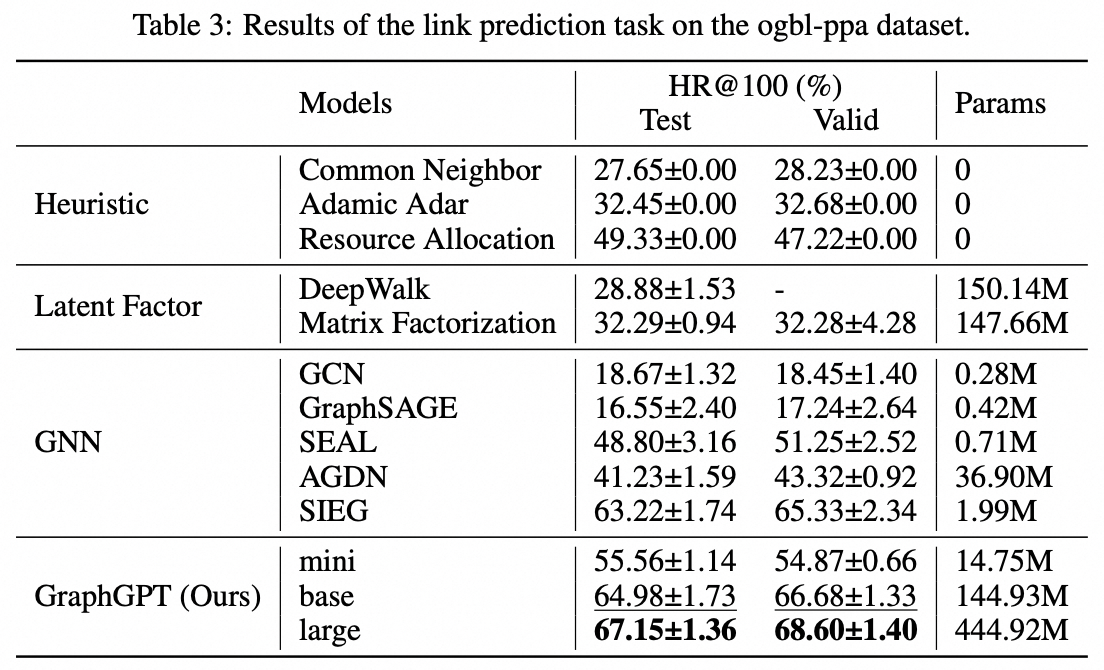
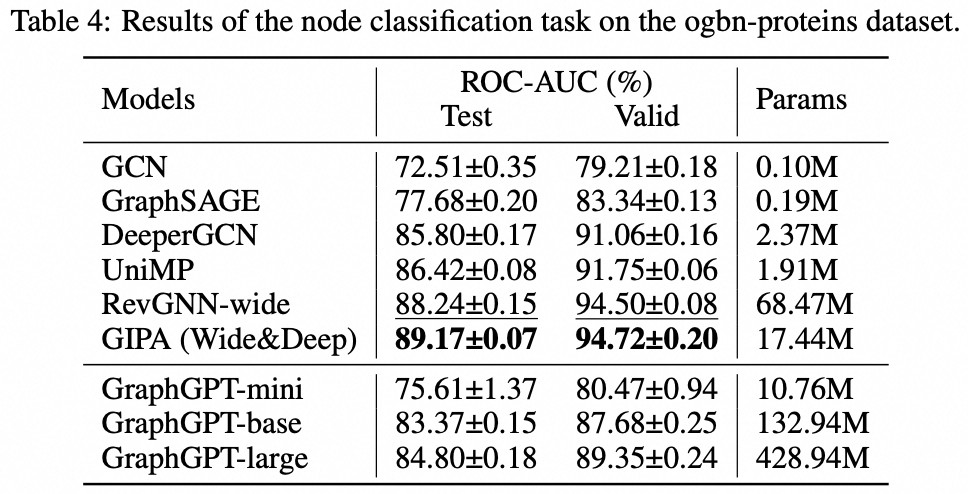
我们提出了 GraphGPT,这是一种通过自监督生成预训练图欧拉变换器(GET)进行图学习的新模型。我们首先介绍 GET,它由一个普通的 Transformer 编码器/解码器主干和一个转换组成,该转换将每个图或采样子图转换为使用欧拉路径可逆地表示节点、边和属性的标记序列。然后,我们使用下一个令牌预测 (NTP) 任务或计划的屏蔽令牌预测 (SMTP) 任务来预训练 GET。最后,我们根据监督任务对模型进行微调。这种直观而有效的模型在大规模分子数据集 PCQM4Mv2、蛋白质-蛋白质关联数据集 ogbl-ppa 上实现了优于或接近最先进的图形、边缘和节点级任务的结果、来自开放图基准 (OGB) 的引文网络数据集 ogbl-itation2 和 ogbn-蛋白质数据集。此外,生成式预训练使我们能够训练 GraphGPT 高达 2B+ 的参数,并且性能不断提高,这超出了 GNN 和之前的图转换器的能力。
将欧拉图转换为序列后,有多种不同的方法将节点和边属性附加到序列。我们将这些方法命名为short 、 long和prolonged 。
给定图,我们首先对其进行欧拉化,然后将其转换为等价序列。然后,我们循环地重新索引节点。
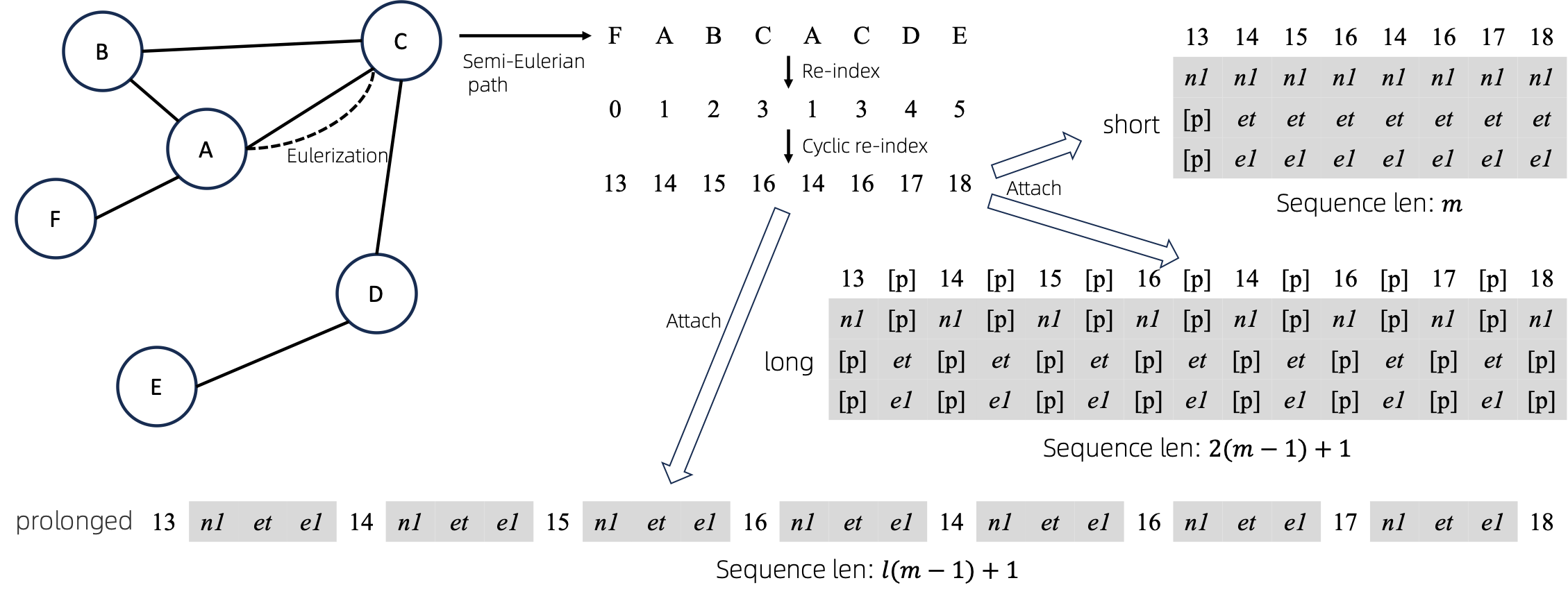
假设图有1个节点属性和1个边属性,则short 、 long 、 prolong方法如上所示。
上图中, n1 、 n2和e1表示节点和边属性的标记, [p]表示填充标记。
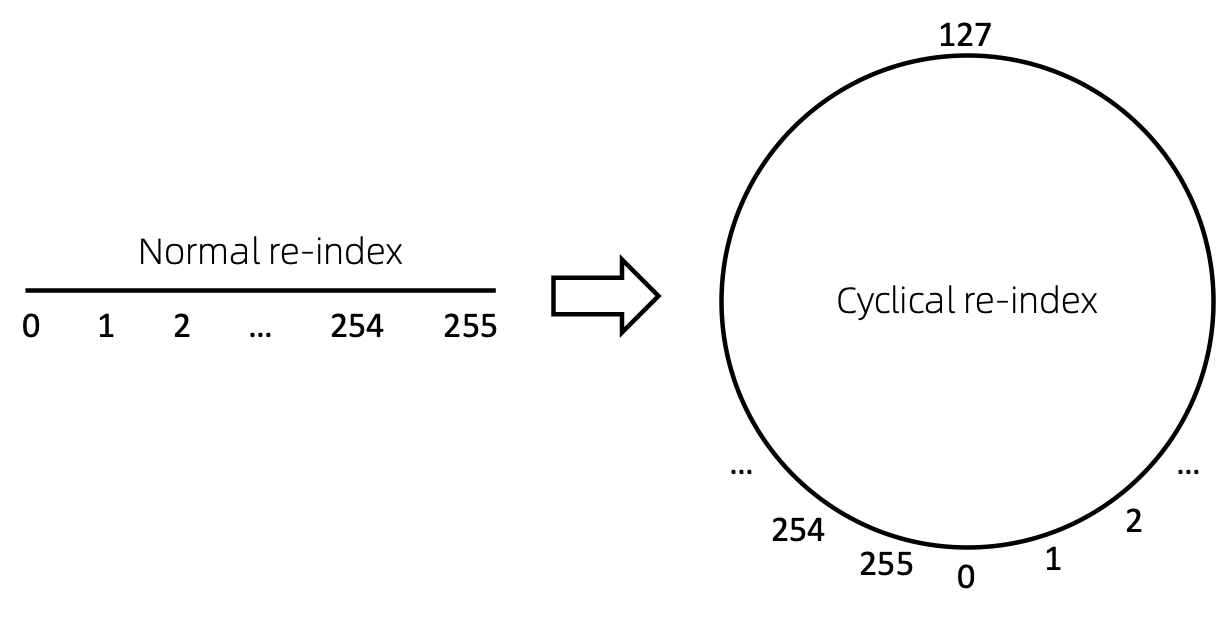
重新索引节点序列的一种直接方法是从 0 开始并递增地添加 1。这样,小索引的 token 将得到充分的训练,而大索引则不会。为了克服这个问题,我们提出了cyclical re-index ,它以给定范围内的随机数开始,例如[0, 255] ,然后递增 1。达到边界后,例如255 ,下一个节点索引将为 0 。
过时了。即将更新。
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc数据集是使用 python 包 ogb 下载的。
当您运行./examples中的脚本时,将自动下载数据集。
然而,数据集PCQM4M-v2很大,下载和预处理可能会出现问题。我们建议cd ./src/utils/和python dataset_utils.py分别下载和预处理数据集。
./examples/graph_lvl/pcqm4m_v2_pretrain.sh中的参数,例如dataset_name 、 model_name 、 batch_size 、 workerCount等,然后运行./examples/graph_lvl/pcqm4m_v2_pretrain.sh使用 PCQM4M-v2 预训练模型数据集。./examples/toy_examples/reddit_pretrain.sh 。./examples/graph_lvl/pcqm4m_v2_supervised.sh中的参数,例如dataset_name 、 model_name 、 batch_size 、 workerCount 、 pretrain_cpt等,然后运行./examples/graph_lvl/pcqm4m_v2_supervised.sh与下游任务进行微调。./examples/toy_examples/reddit_supervised.sh 。 .pre-commit-config.yaml :为 python 创建包含以下内容的文件 repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : blackpre-commit install :将 pre-commit 安装到你的 git hooks 中。pre-commit install应该始终是您要做的第一件事。pre-commit run --all-files :在存储库上运行所有预提交挂钩pre-commit autoupdate :自动将您的挂钩更新到最新版本git commit -n :可以使用以下命令禁用特定提交的预提交检查如果您发现这项工作有用,请引用以下论文:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}赵其芳 ([email protected])
衷心感谢您对我们工作提出的建议!
根据 MIT 许可证发布(参见LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


