ComfyUI N Nodes
1.0.0
ComfyUI 的一套自定义节点,包括整数、字符串和浮点变量节点、GPT 节点和视频节点。
重要的
这些节点主要在 Windows 中由 ComfyUI 提供的默认环境以及笔记本为 Paperspace 特别使用 cyberes/gradient-base-py3.10:latest docker 镜像创建的环境中进行了测试。其他环境尚未测试。
克隆存储库: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
到您的 ComfyUI custom_nodes目录
重要提示:如果您希望 GPU 上的 GPT 节点,您需要运行install_dependency bat files 。有 2 个版本:适用于旧 ggmlv3 模型的install_dependency_ggml_models.bat和适用于所有新模型 (GGUF) 的install_dependency_gguf_models.bat 。您一次只能使用其中之一!由于llama-cpp-python需要从源代码进行编译才能使用 GPU,因此您首先需要安装 CUDA 和 Visual Studio 2019 或 2022(以我的 bat 为例)来编译它。有关详细信息和完整指南,您可以访问此处。
如果您打算将 GPTLoaderSimple 与 Moondream 模型一起使用,则需要执行“install_extra.bat”脚本,该脚本将安装 Transformers 版本 4.36.2。
重启ComfyUI
如果您需要恢复这些更改(由于与其他节点不兼容),您可以使用“remove_extra.bat”脚本。
ComfyUI 将在启动时自动加载所有自定义脚本和节点。
笔记
llama-cpp-python 安装将由脚本自动完成。如果您有 NVIDIA GPU,则无需再构建 CUDA,感谢 jllllll repo。我还放弃了对 GGMLv3 模型的支持,因为所有著名模型现在都应该切换到最新版本的 GGUF。
笔记
自2024年2月14日起,该节点进行了大规模重写,这也导致了所有节点名称的更改,以避免将来与其他扩展发生任何冲突(或者至少我希望如此)。因此,旧的工作流程不再兼容,需要手动更换每个节点。为了避免这种情况,我创建了一个允许自动替换的工具。在 Windows 上,只需将任何 *.json 工作流程拖到位于 (custom_nodes/ComfyUI-N-Nodes) 的 migrate.bat 文件上,就会在与当前工作流程相同的文件夹中创建另一个后缀为 _migerated 的工作流程。在 Linux 上,您可以通过以下方式使用该脚本:python libs/migrate.py path/to/original/workflow/。出于安全原因,原始工作流程不会被删除。”要在 Comfyui-N-Suite 发生此更改之前安装此存储库的最后一个版本,请执行git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083
custom_nodes中的ComfyUI-N-Nodes文件夹ComfyUIwebextensions中的comfyui-n-nodes文件夹ComfyUIstyles中的n-styles.csv和n-styles.csv.backup文件ComfyUImodels中的GPTcheckpoints文件夹custom_nodes/ComfyUI-N-Nodesgit pull
LoadVideoAdvanced 节点允许加载视频文件并从中提取帧。名称已从LoadVideo更改为LoadVideoAdvanced以避免与LoadVideo节点发生冲突。
video :选择要加载的视频文件。framerate :选择是保持原始帧速率还是降低到一半或四分之一速度。resize_by :选择如何调整框架大小 - '无'、'高度'或'宽度'。size :如果按高度或宽度调整大小,则目标尺寸。images_limit :限制要提取的帧数。batch_size :编码帧的批量大小。starting_frame :选择从哪一帧开始。autoplay :选择是否自动播放视频。use_ram :使用 RAM 而不是磁盘来解压缩视频帧。 IMAGES :提取帧图像作为 PyTorch 张量。LATENT :空的潜在向量。METADATA :视频元数据 - FPS 和帧数。WIDTH:框架宽度。HEIGHT :框架高度。META_FPS :帧速率。META_N_FRAMES :帧数。该节点以指定的帧速率从输入视频中提取帧。如果选择,它会调整帧的大小,并将它们作为一批 PyTorch 图像张量以及潜在向量、元数据和帧尺寸返回。
SaveVideo 节点接收提取的帧并将它们另存为视频文件。 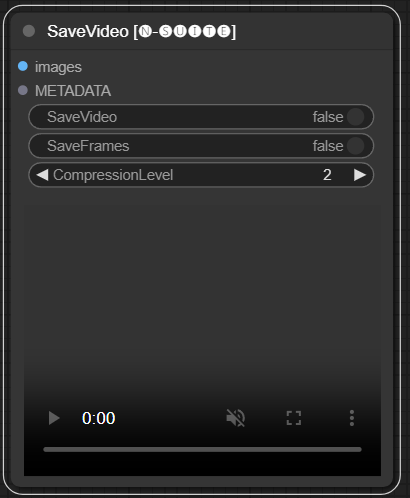
images :将图像框架为张量。METADATA :来自 LoadVideo 节点的元数据。SaveVideo :切换保存输出视频文件。SaveFrames :切换将帧保存到文件夹。CompressionLevel :用于保存帧的 PNG 压缩级别。 保存输出视频文件和/或提取的帧。
该节点获取提取的帧和元数据,并将它们保存为新的视频文件和/或单个帧图像。可以配置视频压缩和帧PNG压缩。注意:如果您使用LoadVideo作为帧源,则原始文件的音频将被保留,但前提是images_limit和starting_frame等于零。
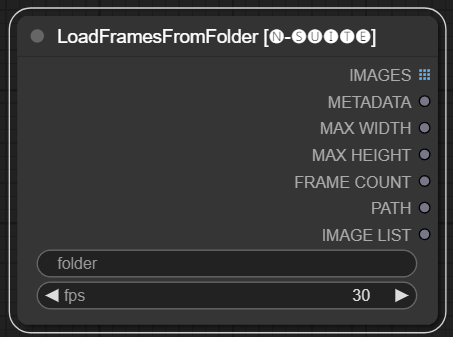
LoadFramesFromFolder 节点允许从文件夹加载图像帧并将它们批量返回。
folder :包含帧图像的文件夹路径。必须是 png 格式,以数字命名(例如 1.png 甚至 0001.png)。图像将按顺序加载。fps :分配给加载帧的每秒帧数。 IMAGES :一批加载的帧图像作为 PyTorch 张量。METADATA :包含设置的 FPS 值的元数据。MAX_WIDTH :最大框架宽度。MAX_HEIGHT :最大框架高度。FRAME COUNT :文件夹中的帧数。PATH :包含帧图像的文件夹的路径。IMAGE LIST : 文件夹中的帧图像列表(不是真正的列表,只是除以 n 的字符串)。该节点从指定文件夹加载所有图像文件,将它们转换为 PyTorch 张量,并将它们作为批处理张量以及包含设置 FPS 值的简单元数据返回。
这允许轻松加载之前提取和保存的一组帧,例如,重新加载并再次处理它们。通过设置 FPS 值,可以将帧正确解释为视频序列。
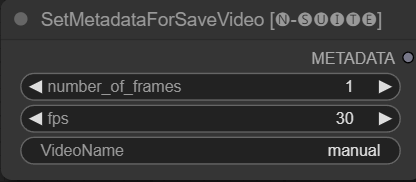
SetMetadataForSaveVideo 节点允许设置 SaveVideo 节点的元数据。
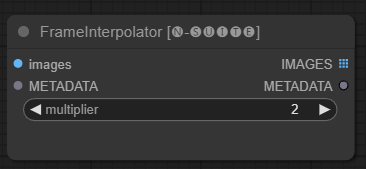
FrameInterpolator 节点允许在提取的视频帧之间进行插值,以提高帧速率和平滑运动。
images :提取帧图像作为张量。METADATA :视频的元数据 - FPS 和帧数。multiplier :增加帧速率的因子。 IMAGES :插值帧作为图像张量。METADATA :使用新的帧速率更新元数据。该节点将提取的帧和元数据作为输入。它使用插值模型 (RIFE) 以更高的帧速率生成额外的中间帧。
将元数据中的原始帧速率乘以乘multiplier以获得新的插值帧速率。
插值帧作为一批图像张量返回,以及包含新帧速率的更新元数据。
这允许提高现有视频的帧速率,以实现更平滑的运动和更慢的播放。插值模型创建新的真实帧来填补空白,而不是仅仅复制现有帧。
原始代码取自此处
由于原始节点在链接方面存在限制(例如,在我撰写本文时,您无法将另一个 ksampler 的“start_at_step”和“steps”链接在一起),因此我决定创建这些简单的节点变量来绕过此限制。变量是:
这些自定义节点旨在通过使用 GGUF GPT 模型生成文本来增强 ConfyUI 框架的功能。本自述文件概述了两个自定义节点及其在 ConfyUI 中的用法。
您可以通过以下方式在extra_model_paths.yaml中添加模型 GGUF 所在的路径(示例):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
否则,它将在 ComfyUI 的模型文件夹中创建一个 GPTcheckpoints 文件夹,您可以在其中放置 .gguf 模型。
还在“GPTcheckpoints”文件夹的“Llava”目录中为 LLava 模型创建了两个文件夹:
clips :此文件夹指定用于存储 LLava 模型的剪辑(通常是存储库中以mm开头的文件)。 models :此文件夹指定用于存储 LLava 模型。
该节点实际上支持 4 种不同的模型:
GGUF 模型可以从 Huggingface Hub 下载
这里有一个关于如何使用 boricuapab 的 GGUF 模型的示例视频
以下是该节点支持的模型的一小部分列表:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Vision
####Llava 模型示例: 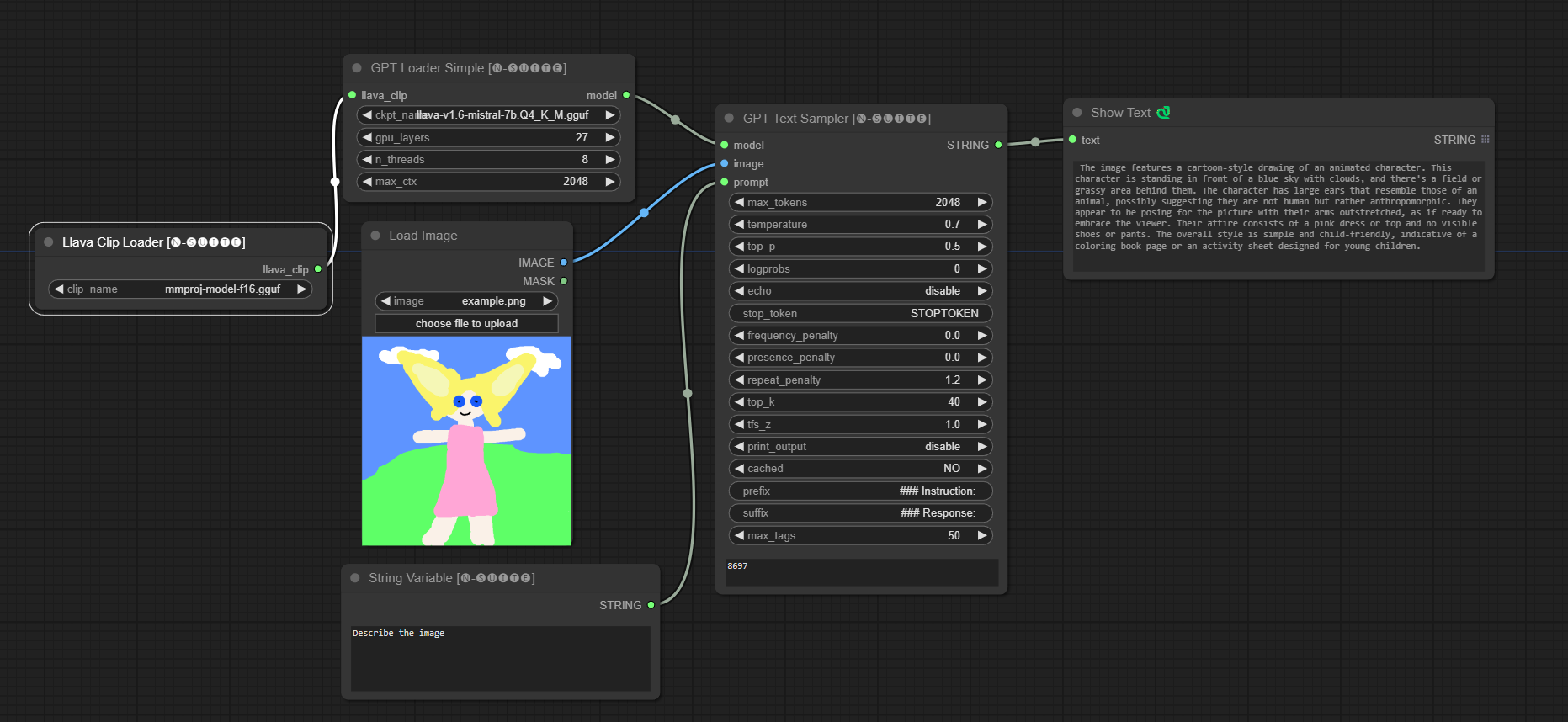
第一次运行时会自动下载模型。无论如何,可以在此处获取从该存储库中获取的代码
####Moondream 模型示例: 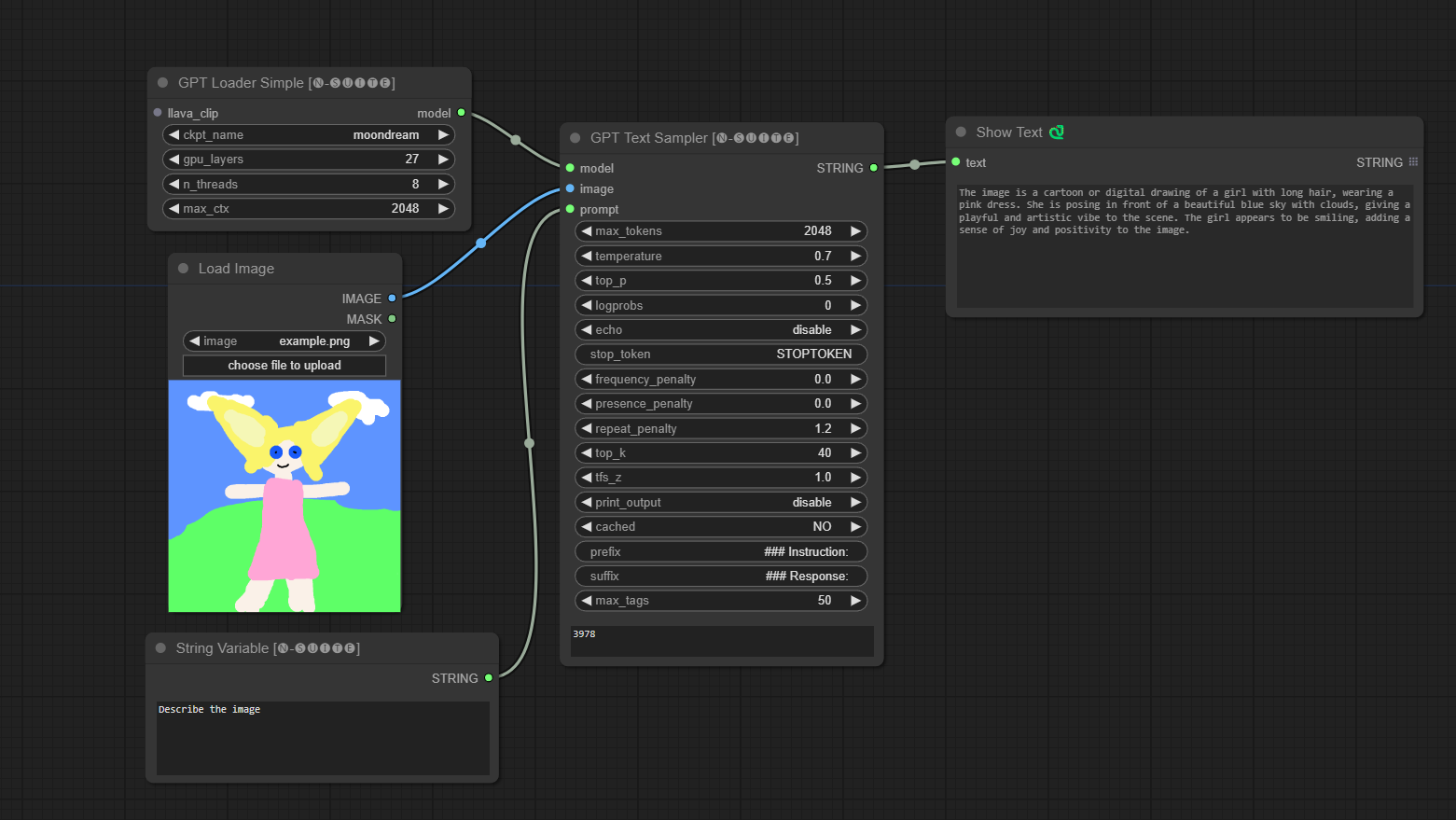
第一次运行时会自动下载模型。无论如何,可以在此处获取从该存储库中获取的代码
####Joytag 模型示例: 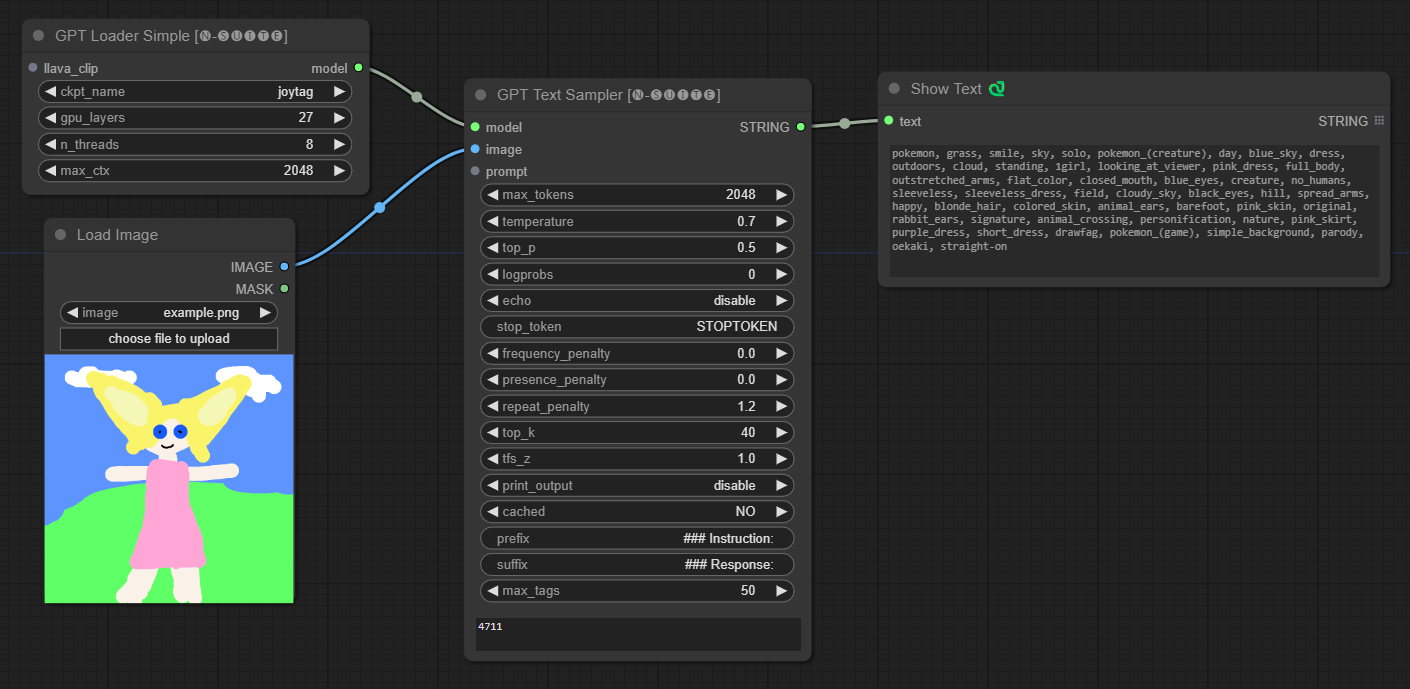
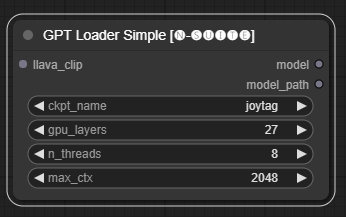
GPTLoaderSimple节点负责加载 GPT 模型检查点并创建用于文本生成的 Llama 库实例。它提供了一个接口来配置 GPU 层、线程数和文本生成的最大上下文。
ckpt_name :从可用选项中选择 GPT 检查点名称(joytag 和 Moondream 将在第一次使用时自动下载)。gpu_layers :指定要使用的 GPU 层数(默认值:27)。n_threads :指定文本生成的线程数(默认值:8)。max_ctx :指定文本生成的最大上下文长度(默认值:2048)。 该节点返回 Llama 库的实例 (MODEL) 和加载的检查点的路径 (STRING)。
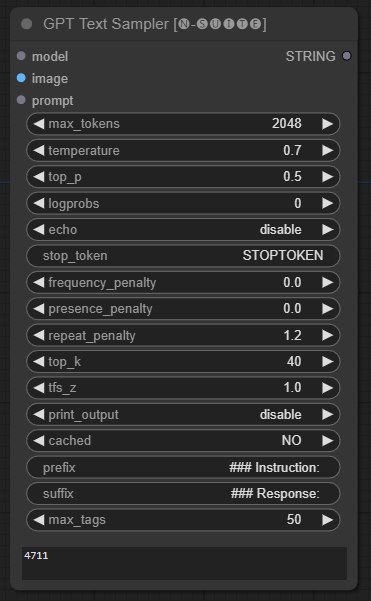
GPTSampler节点有助于根据输入提示和各种生成参数使用 GPT 模型生成文本。它允许您控制温度、top-p 采样、惩罚等方面。
prompt :输入文本生成的输入提示。image :Joytag、moondream 和 llava 模型的图像输入。model :选择用于文本生成的 GPT 模型。max_tokens :设置生成文本中的最大标记数(默认值:128)。temperature :设置随机性的温度参数(默认值:0.7)。top_p :设置核采样的 top-p 概率(默认值:0.5)。logprobs :指定要输出的对数概率数(默认值:0)。echo :启用或禁用在生成的文本旁边打印输入提示。stop_token :指定文本生成停止的标记。frequency_penalty 、 presence_penalty 、 repeat_penalty :控制单词生成惩罚。top_k :设置生成期间要考虑的 top-k 标记(默认值:40)。tfs_z :设置最频繁样本的温度缩放因子(默认值:1.0)。print_output :启用或禁用将生成的文本打印到控制台。cached :选择是否使用缓存生成(默认值:NO)。prefix , suffix :指定要在提示前添加和附加到提示的文本。max_tags :这只影响 Joydag 生成的最大标签数。 该节点返回生成的文本以及 UI 友好的表示形式。
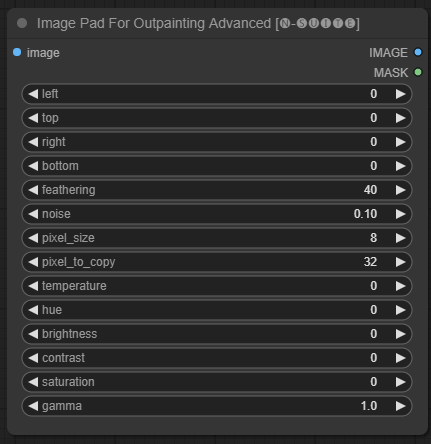
ImagePadForOutpaintingAdvanced节点是ImagePadForOutpainting节点的替代方案,它应用了本视频中在 outpainting mask 下看到的技术。颜色校正部分取自 Sipherxyz 的这个自定义节点
image :图像输入。left :从左侧延伸的像素,top :从顶部延伸的像素,right :从右侧延伸的像素,bottom :从底部延伸的像素。feathering :羽化强度noise :混合噪声和复制边框的强度pixel_size :像素化效果中的像素有多大pixel_to_copy :要复制多少像素(从每一侧)temperature :仅应用于遮罩部分的色彩校正设置。hue :仅应用于遮罩部分的色彩校正设置。brightness :仅应用于遮罩部分的颜色校正设置。contrast :仅应用于遮罩部分的颜色校正设置。saturation :仅应用于蒙版部分的色彩校正设置。gamma :仅应用于遮罩部分的色彩校正设置。 该节点返回处理后的图像和掩模。

DynamicPrompt节点通过将固定提示与从可变提示中随机选择的标签相结合来生成提示。这使得能够为各种用例生成灵活且动态的提示。
variable_prompt :输入标签选择的变量提示。cached :选择是否缓存生成的提示(默认:NO)。number_of_random_tag :在“固定”和“随机”之间选择要包含的随机标签的数量。fixed_number_of_random_tag :如果number_of_random_tag如果“固定”,则指定要包含的随机标签的数量(默认值:1)。fixed_prompt (可选):输入用于生成最终提示的固定提示。 该节点返回生成的提示,该提示是固定提示和选定的随机标签的组合。
variable_prompt字段即可, fixed_prompt是可选的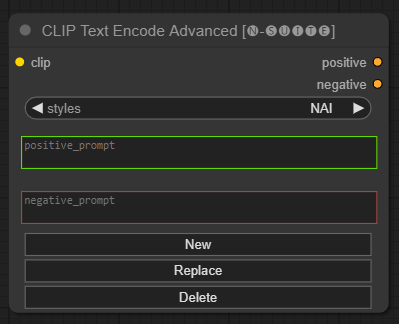
CLIP Text Encode Advanced节点是标准CLIP Text Encode节点的替代方案。它提供对添加/替换/删除样式的支持,允许在单个节点中包含正面和负面提示。
基本样式文件称为n-styles.csv ,位于ComfyUIstyles文件夹中。该样式文件遵循与 A1111 中使用的当前styles.csv文件相同的格式(在撰写本文时)。
注意:此注释是实验性的,仍然有很多错误
clip :剪辑输入style :根据选择的风格自动填充正负提示positive :积极的条件negative :消极的条件欢迎通过报告问题或提出改进建议来为该项目做出贡献。在 GitHub 存储库上提出问题或提交拉取请求。
该项目已获得 MIT 许可证的许可。有关详细信息,请参阅许可证文件。


