JoyVASA
1.0.0
曹旭阳1*王国新12*石盛 1*赵军1杨耀1
费金涛1高敏宇1
1京东健康国际有限公司2浙江大学
音频驱动的肖像动画在基于扩散的模型方面取得了重大进展,提高了视频质量和口型同步准确性。然而,这些模型日益复杂,导致训练和推理效率低下,以及视频长度和帧间连续性的限制。在本文中,我们提出了 JoyVASA,一种基于扩散的方法,用于在音频驱动的面部动画中生成面部动态和头部运动。具体来说,在第一阶段,我们引入了一个解耦的面部表示框架,它将动态面部表情与静态 3D 面部表示分开。这种解耦允许系统通过将任何静态 3D 面部表征与动态运动序列相结合来生成更长的视频。然后,在第二阶段,训练扩散变压器直接根据音频提示生成运动序列,而与角色身份无关。最后,在第一阶段训练的生成器使用 3D 面部表示和生成的运动序列作为输入来渲染高质量的动画。凭借解耦的面部表示和独立于身份的运动生成过程,JoyVASA 超越了人类肖像,无缝地制作了动物面部动画。该模型在私人中文和公共英语数据的混合数据集上进行训练,从而实现多语言支持。实验结果验证了我们方法的有效性。未来的工作将集中在提高实时性能和细化表情控制上,进一步扩展该框架在人像动画方面的应用。
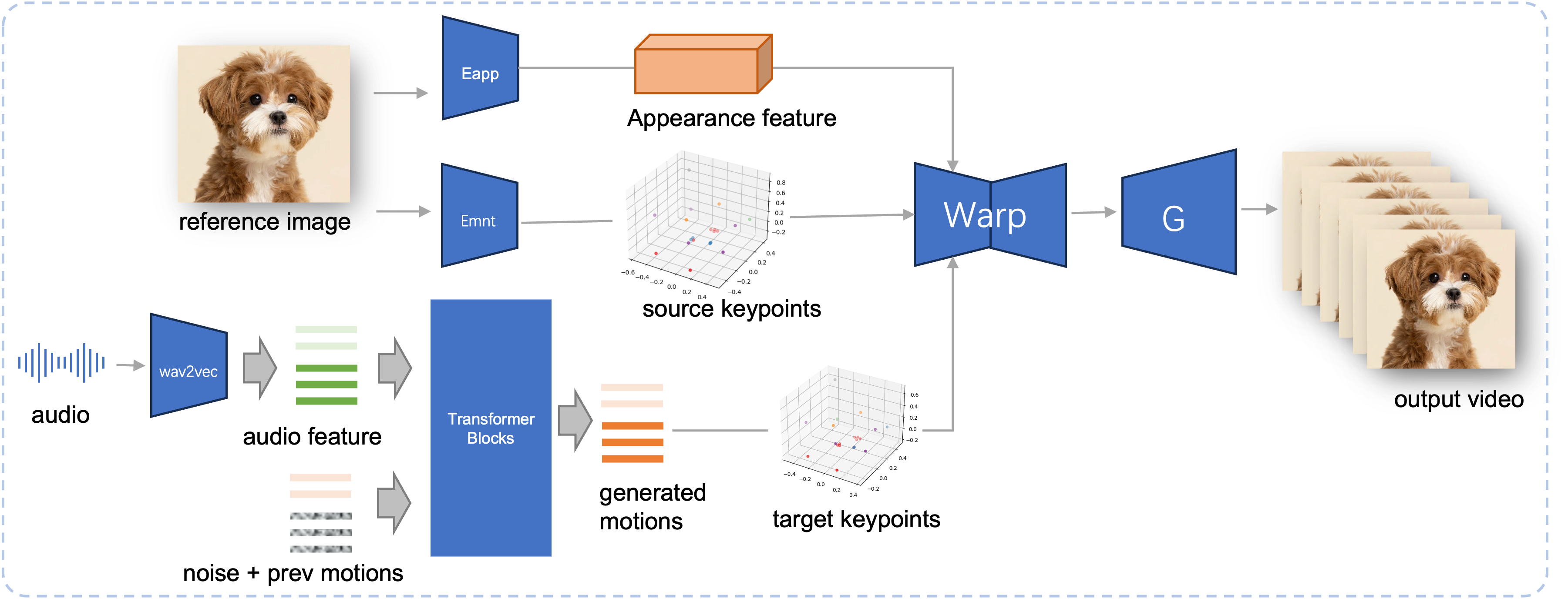
拟议的 JoyVASA 的推理管道。给定参考图像,我们首先使用 LivePortrait 中的外观编码器提取 3D 面部外观特征,并使用运动编码器提取一系列学习的 3D 关键点。对于输入语音,最初使用 wav2vec2 编码器提取音频特征。然后使用在第二阶段以滑动窗口方式训练的扩散模型对音频驱动的运动序列进行采样。使用参考图像的 3D 关键点和采样的目标运动序列,计算目标关键点。最后,3D 面部外观特征根据源和目标关键点进行变形,并由生成器渲染以生成最终输出视频。
系统要求:
乌班图:
在 Ubuntu 20.04、Cuda 11.3 上测试
测试的 GPU:A100
视窗:
在 Windows 11、CUDA 12.1 上测试
测试的 GPU:RTX 4060 笔记本电脑 8GB VRAM GPU
创建环境:
# 1.创建基础环境conda create -n Joyvasa python=3.10 -y conda 激活 Joyvasa # 2. 安装requirementspip install -rrequirements.txt# 3. 安装ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. 安装 MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # 等于 cd ../../../../../../../
确保您已安装 git-lfs 并将以下所有检查点下载到pretrained_weights :
git lfs 安装 git 克隆 https://huggingface.co/jdh-algo/JoyVASA
我们支持两种类型的音频编码器,包括 wav2vec2-base 和 hubert-chinese。
运行以下命令下载 hubert-chinese 预训练权重:
git lfs 安装 git 克隆 https://huggingface.co/TencentGameMate/chinese-hubert-base
要获取基于 wav2vec2 的预训练权重,请运行以下命令:
git lfs 安装 git 克隆 https://huggingface.co/facebook/wav2vec2-base-960h
笔记
稍后将支持带有 wav2vec2 编码器的运动生成模型。
# !pip install -U "huggingface_hub[cli]"huggingface-cli 下载 KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
更多下载方法请参考Liveportrait。
pretrained_weights内容最终的pretrained_weights目录应如下所示:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.json笔记
Windows下的TencentGameMate:chinese-hubert-base文件夹应重命名为chinese-hubert-base 。
动物:
python inference.py -r 资产/示例/imgs/joyvasa_001.png -a 资产/示例/audios/joyvasa_001.wav --animation_mode 动物 --cfg_scale 2.0
人类:
python inference.py -r asset/examples/imgs/joyvasa_003.png -a asset/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
您可以更改 cfg_scale 以获得不同表情和姿势的结果。
笔记
动画模式和参考图像不匹配可能会导致不正确的结果。
使用以下命令启动 Web 演示:
蟒蛇应用程序.py
该演示将在 http://127.0.0.1:7862 创建。
如果您发现我们的工作有帮助,请考虑引用我们:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}我们要感谢 LivePortrait、Open Facevid2vid、InsightFace、X-Pose、DiffPoseTalk、Hallo、wav2vec 2.0、中文语音预训练、Q-Align、Syncnet 和 VBench 存储库的贡献者,感谢他们的开放研究和出色的工作。


