wikisearch
1.0.0
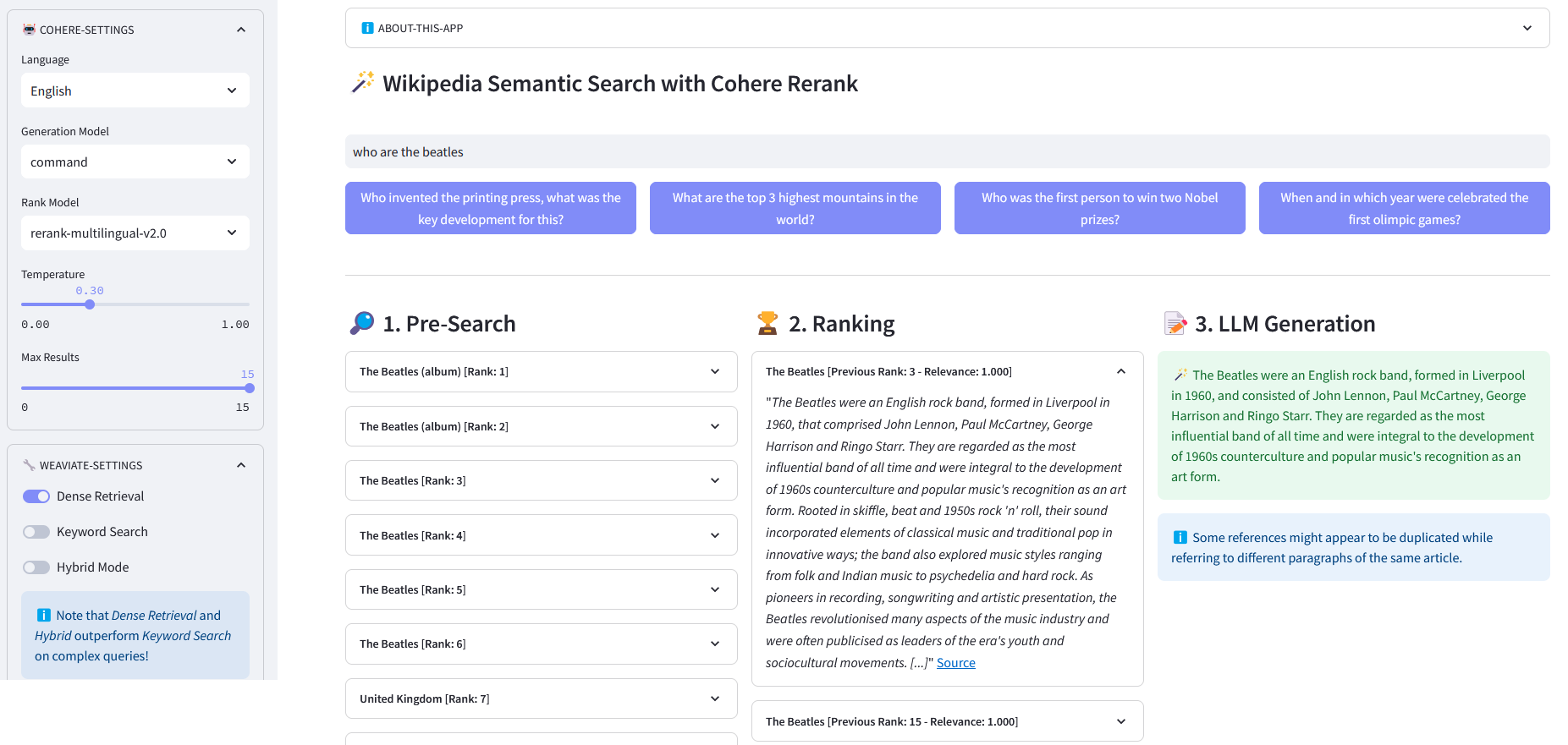
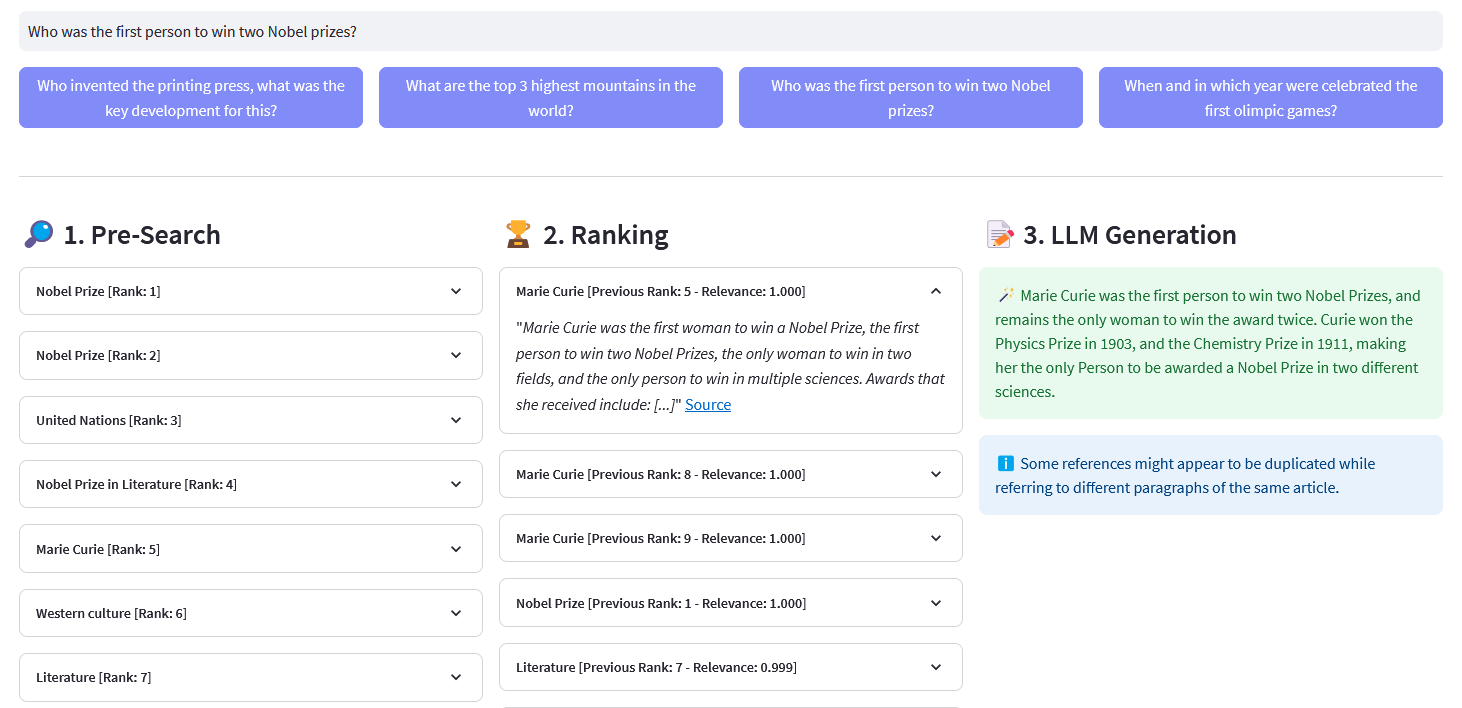
Streamlit 应用程序,用于对超过 1000 万个由 Weaviate 嵌入矢量化的维基百科文档进行多语言语义搜索。该实现基于 Cohere 的博客“使用 LLM 进行搜索”及其相应的笔记本。它可以比较关键字搜索、密集检索和混合搜索的性能来查询维基百科数据集。它进一步演示了如何使用 Cohere Rerank 来提高结果的准确性,并使用 Cohere Generation 根据所述排名结果提供响应。
语义搜索是指在生成结果时考虑搜索短语的意图和上下文含义的搜索算法,而不是仅仅关注关键字匹配。它通过理解查询背后的语义或含义来提供更准确和相关的结果。
嵌入是表示单词、句子、文档、图像或音频等数据的浮点数向量(列表)。所述数字表示捕获数据的上下文、层次结构和相似性。它们可用于下游任务,例如分类、聚类、异常值检测和语义搜索。
矢量数据库(例如 Weaviate)是专门为优化嵌入的存储和查询功能而构建的。在实践中,矢量数据库使用不同算法的组合,这些算法都参与近似最近邻 (ANN) 搜索。这些算法通过散列、量化或基于图的搜索来优化搜索。
预搜索:通过关键字匹配、密集检索或混合搜索对维基百科嵌入进行预搜索:
关键字匹配:它查找属性中包含搜索词的对象。根据BM25F函数对结果进行评分:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" 执行关键字使用 Weaviate 中存储的嵌入来搜索(稀疏检索): - query (str):搜索查询 - lang (str,可选):文章的语言。 - top_n(int,可选):返回的热门结果的数量。返回: - list:基于 BM25F 评分的热门文章列表。 ""logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("文章", self.WIKIPEDIA_PROPERTIES)
.with_bm25(查询=查询)
.with_where(where_filter)
.with_limit(top_n)
。做()
)返回响应["数据"]["获取"]["文章"]密集检索:查找与原始(非矢量化)文本最相似的对象:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" 执行语义使用 Weaviate 中存储的嵌入在维基百科文章上进行搜索(密集检索) 参数: - query (str):搜索查询 - lang (str,可选):文章的语言。 - top_n(int,可选):返回的热门结果的数量。返回: - list:基于语义相似度的热门文章列表。 ""logging.info("with_neartext()")nearText = {"concepts": [查询]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("文章", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(where_filter)
.with_limit(top_n)
。做()
)返回响应['数据']['获取']['文章']混合搜索:根据关键字 (bm25) 搜索和矢量搜索结果的加权组合生成结果。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" 执行混合使用 Weaviate 中存储的嵌入来搜索维基百科文章 参数: - query (str):搜索查询。默认为 'en'。 - top_n (int,可选):返回的热门结果数。默认为 10。返回: - list:基于混合评分的热门文章列表。 with_hybrid()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("文章", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(查询=查询)
.with_where(where_filter)
.with_limit(top_n)
。做()
)返回响应["数据"]["获取"]["文章"]ReRank :Cohere Rerank 通过为给定用户查询的每个预搜索结果分配相关性分数来重新组织预搜索。与基于嵌入的语义搜索相比,它会产生更好的搜索结果 - 特别是对于复杂和特定领域的查询。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, 查询, 文档, top_n=10, model='rerank-english-v2.0') -> dict:""" 使用 Cohere 的重新排名 API 对响应列表进行重新排名。参数: - query (str):搜索查询。 - Documents (list):要排序的文档列表- top_n(int,可选):要返回的顶部重新排名结果的数量。 - model:用于重新排名的模型。返回: - dict:来自 Cohere 的 API 的重新排名文档。 """return self.cohere.rerank(query=query,documents=documents,top_n=top_n,model=model)
来源:Cohere
答案生成:Cohere Generation 根据排名结果撰写答案。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, temp=0.2, model="command", lang="english") -> list:prompt = f""" 使用下面提供的信息回答最后的问题。/包括从上下文中提取的一些好奇或相关的事实。/以查询的语言生成答案。如果您无法确定查询的语言使用 {lang}。 / 如果问题的答案未包含在所提供的信息中,则生成“答案不在上下文中” --- 上下文信息:{context} --。 - 问题:{query} """return self.cohere.generate(prompt=prompt,num_ Generations=1,max_tokens=1000,温度=温度,model=model,
)克隆存储库:
[email protected]:dcarpintero/wikisearch.git
创建并激活虚拟环境:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
安装依赖项:
pip install -r requirements.txt
启动网络应用程序
streamlit run ./app.py
演示 Web 应用程序部署到 Streamlit Cloud,可在 https://wikisearch.streamlit.app/ 获取
连贯重排序
流光云
嵌入档案:数以百万计的多种语言的维基百科文章嵌入
使用法学硕士进行密集检索和重新排名搜索
矢量数据库
维维特矢量搜索
维维特 BM25 搜索
Weaviate 混合搜索


