EasyDetect
1.0.0

易于使用的 MLLM 多模态幻觉检测框架
致谢 • 基准测试 • 演示 • 概述 • ModelZoo • 安装 • 快速入门 • 引用
致谢
概述
统一多模态幻觉
数据集:MHalluBench 统计
框架:UniHD 插图
模型动物园
安装
⏩快速入门
引文
2024-05-17 论文Unified Hallucination Inspection for Multimodal Large Language Models被ACL 2024主会议接收。
2024-04-21 我们用我们自己训练的模型替换了演示中的所有基础模型,显着减少了推理时间。
2024-04-21 我们发布了开源幻觉检测模型HalDet-LLAVA,可以在huggingface、modelscope和wisemodel中下载。
2024-02-10 我们发布了 EasyDetect 演示。
2024-02-05 我们发布了论文:“Unified Hallucination Inspection for Multimodal Large Language Models”,带有新的基准 MHaluBench!我们期待有关此主题的任何评论或讨论:)
2023-10-20 EasyDetect项目已上线,正在开发中。
该项目的部分实施得到了相关幻觉工具包的协助和启发,包括 FactTool、Woodpecker 等。该存储库还受益于 mPLUG-Owl、MiniGPT-4、LLaVA、GroundingDINO 和 MAERec 的公共项目。我们遵循相同的开源许可,并感谢他们对社区的贡献。
EasyDetect 是一个系统包,在您的研究实验中被提议作为多模态大型语言模型(MLLM)(如 GPT-4V、Gemini、LlaVA)的易于使用的幻觉检测框架。
统一检测的先决条件是对 MLLM 内幻觉的主要类别进行一致分类。我们的论文从统一的角度粗略地审视了以下幻觉分类法:


图 1:统一多模态幻觉检测旨在识别和检测物体、属性和场景文本等各个层面的模态冲突幻觉,以及图像到文本和文本到图像中的事实冲突幻觉一代。
模态冲突的幻觉。 MLLM 有时会生成与其他模式的输入相冲突的输出,从而导致诸如不正确的对象、属性或场景文本等问题。上图 (a) 中的示例包括 MLLM 不准确地描述运动员的制服,展示了由于 MLLM 实现细粒度文本-图像对齐的能力有限而导致的属性级冲突。
与事实相矛盾的幻觉。 MLLM 的输出可能与既定的事实知识相矛盾。图像到文本模型可以通过合并不相关的事实来生成偏离实际内容的叙述,而文本到图像模型可能产生无法反映文本提示中包含的事实知识的视觉效果。这些差异凸显了 MLLM 为保持事实一致性而付出的努力,代表了该领域的重大挑战。
多模态幻觉的统一检测需要检查每个图像-文本对a={v, x} ,其中v表示提供给 MLLM 的视觉输入或由其合成的视觉输出。相应地, x表示 MLLM 基于v生成的文本响应或用于合成v文本用户查询。在此任务中,每个x可能包含多个声明,表示为a确定它是“幻觉”还是“非幻觉”,并根据提供的幻觉定义为他们的判断提供依据。 LLM 的文本幻觉检测表示此设置中的一个子情况,其中v为空。
为了推进这一研究轨迹,我们引入了元评估基准 MHaluBench,它涵盖了从图像到文本和文本到图像生成的内容,旨在严格评估多模态幻觉检测器的进展。下图提供了有关 MHaluBench 的更多统计详细信息。
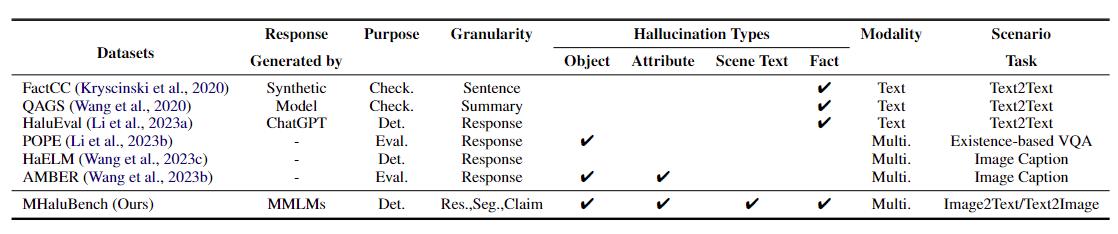
表 1:现有事实核查或幻觉评估的基准比较。 “查看。”表示验证事实一致性,“Eval”。表示评估不同法学硕士产生的幻觉,其响应基于被测的不同法学硕士,而“Det”。体现了对探测器识别幻觉能力的评价。
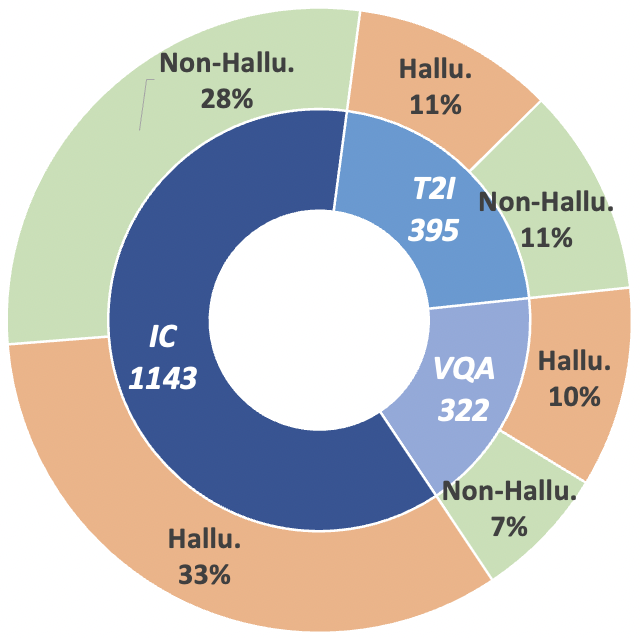
图2: MHaluBench的索赔级数据统计。 “IC”表示图像字幕,“T2I”表示文本到图像合成。
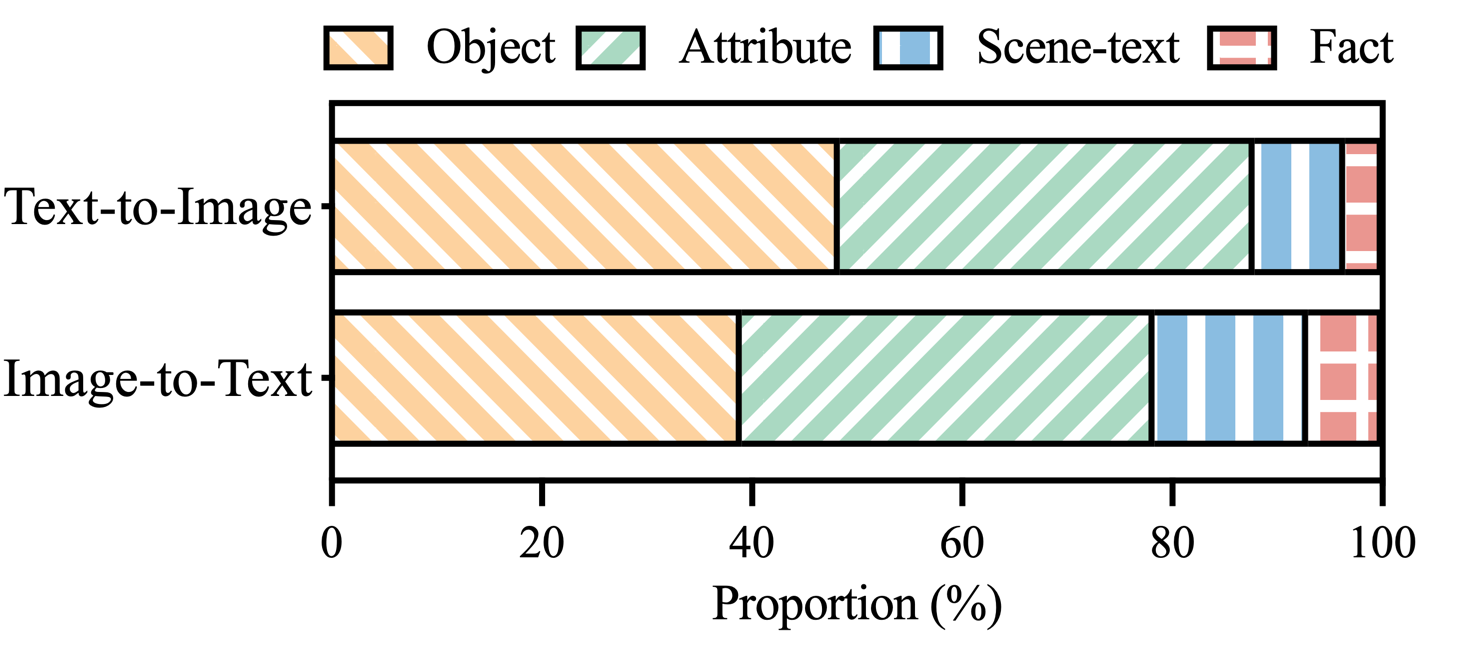
图 3: MHaluBench 幻觉标签声明中幻觉类别的分布。
为了解决幻觉检测中的关键挑战,我们在图 4 中引入了一个统一的框架,该框架系统地解决了图像到文本和文本到图像任务的多模态幻觉识别。我们的框架利用各种工具的特定领域优势来有效收集多模式证据来确认幻觉。
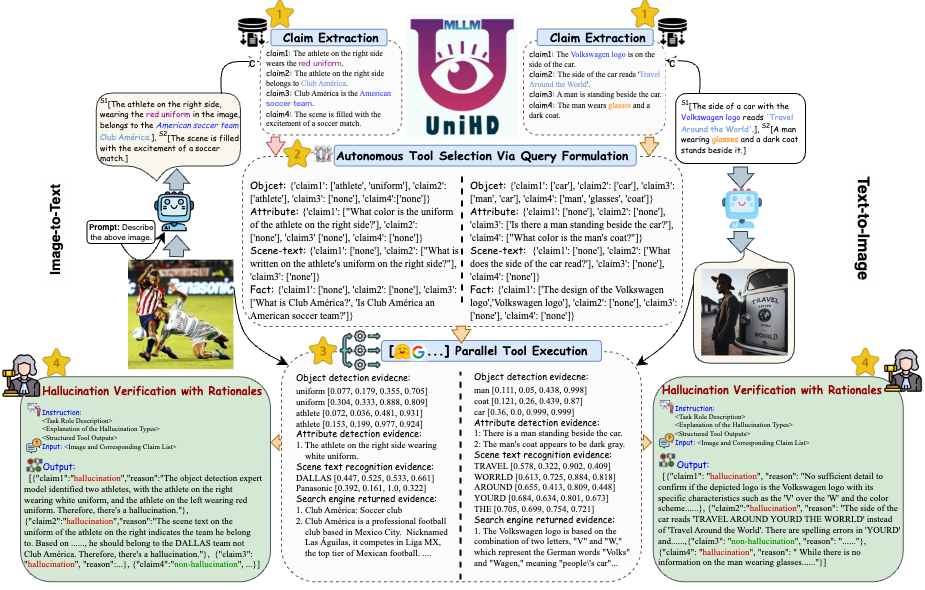
图4: UniHD用于统一多模态幻觉检测的具体图示。
您可以在三个平台上下载 HalDet-LLaVA 的两个版本:7b 和 13b:HuggingFace、ModelScope 和 WiseModel。
| 抱脸 | 模型范围 | 智慧模型 |
|---|---|---|
| 哈尔德拉瓦-7b | 哈尔德拉瓦-7b | 哈尔德拉瓦-7b |
| 哈尔德特拉瓦-13b | 哈尔德特拉瓦-13b | 哈尔德特拉瓦-13b |
验证数据集上的声明级别结果
Self-Check(GPT-4V) 表示使用 GPT-4V 0 或 2 例
UniHD(GPT-4V/GPT-4o) 表示使用带有 2-shot 和工具信息的 GPT-4V/GPT-4o
HalDet (LLAVA) 意味着使用在我们的训练数据集上训练的 LLAVA-v1.5
| 任务类型 | 模型 | 加速器 | 平均预测值 | 平均召回率 | 麦克F1 |
| 图像到文本 | 自检0shot (GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| 自检2shot (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| 哈尔德特 (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| 哈尔德特 (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| UniHD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| UniHD(GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| 文本到图像 | 自检0shot (GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| 自检2shot (GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| 哈尔德特 (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| 哈尔德特 (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| UniHD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
要查看有关 HalDet-LLaVA 和训练数据集的更多详细信息,请参阅自述文件。
本地开发安装:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
工具安装(GroundingDINO 和 MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
我们提供示例代码,供用户快速上手 EasyDetect。
用户可以轻松地在yaml文件中配置EasyDetect的参数,或者快速使用我们提供的配置文件中的默认参数。配置文件的路径为 EasyDetect/pipeline/config/config.yaml
openai: api_key: 输入您的 openai api 密钥
base_url:输入base_url,默认为None
温度:0.2
最大令牌数:1024工具:
检测:groundingdino_config:GroundingDINO_SwinT_OGC.pymodel_path:groundingdino_swint_ogc.pthdevice的路径:cuda:0BOX_TRESHOLD:0.35TEXT_TRESHOLD:0.25AREA_THRESHOLD:0.001
ocr:dbnetpp_config: dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015的路径.pydbnetpp_path: dbnetpp的路径.pthmaerec_config: maerec_b_union14m的路径.pymaerec_path: maerec_b.pthdevice的路径: cuda:0content: word.numbercachefiles_path:保存临时图像的cache_files路径BOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: 输入您的 serper api 密钥nippet_cnt: 10prompts: Claim_generate: pipeline/prompts/claim_generate.yaml
query_generate:管道/提示/query_generate.yaml
验证:管道/提示/verify.yaml示例代码
from pipeline.run_pipeline import *pipeline = Pipeline()text = "图像中的咖啡馆名为“Hauptbahnhof”"image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response, Claim_list = pipeline .run(文本=文本,图像路径=图像路径,类型=类型)打印(响应)打印(声明列表)
如果您在工作中使用 EasyDetect,请引用我们的存储库。
@article{chen23factchd,作者={Xiang Chen and Duanzheng Song and Honghao Gui and Chengxi Wang and Ningyu Zhang and Jiang Yong and Fei Huang and Chengfei Lv and Dan Zhang and Huajun Chen},标题={FactCHD:事实冲突幻觉检测基准测试},期刊 = {CoRR},卷 = {abs/2310.12086},年份 = {2023},网址= {https://doi.org/10.48550/arXiv.2310.12086},doi = {10.48550/ARXIV.2310.12086},eprinttype = {arXiv},eprint = {2310.12086},biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib},bibsource = {dblp计算机科学参考书目,https://dblp.org}}@inproceedings{chen-etal-2024- Unified-hallucination,标题=“多模态大语言模型的统一幻觉检测”,作者=“Chen,Xiang和Wang,Chenxi和Xue,伊达和张、宁宇和杨、小燕和李、强和申、岳和梁、雷和顾、金杰和陈、华军”,编辑=“库、伦伟和马丁斯、安德烈和斯里库马尔、维韦克”,书名=“计算语言学协会第62届年会论文集(第一卷:长论文)”,月= 8月,年= “2024”,地址=“泰国曼谷”,出版商=“计算语言学协会”,url =“https://aclanthology.org/2024.acl-long.178”,页面=“3235--3252”,
}我们将提供长期维护来修复错误、解决问题并满足新的要求。因此,如果您有任何问题,请向我们提出问题。


