ssebowa
1.0.0
Ssebowa 是一个开源 Python 库,提供生成式 AI 模型,包括:
ssebowa-llm:用于文本生成的大型语言模型(LLM),ssebowa-vllm:用于视觉理解的视觉语言模型(VLLM),ssebowa-imagen:图像生成和定制微调模型,Ssebowa-vigen:视频生成模型。使用 Ssebowa,您可以轻松生成文本、翻译语言、编写不同类型的创意内容、生成个性化图像并以翔实的方式回答您的问题。
更详细的使用信息请参考:Ssebowa的技术文档
运行脚本之前,请确保已安装所需的库。您可以通过执行以下命令来完成此操作:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .然后安装Ssebowa
pip install ssebowa如果您在 colab 或 jupyter 笔记本中运行此命令,请使用此命令,
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowa现在,您可以通过从库导入来访问不同的模型:
Ssebowa-Imagen 是一种开源图像合成模型,它利用diffusion modeling和generative adversarial networks (GANs)的组合从text descriptions生成高质量图像,还允许将您的几张照片custom model为能够生成您chosen subject的令人惊叹的图像。它利用100 billion dataset集,使其能够准确捕捉现实世界图像的细微差别,并有效地将文本描述转换为引人注目的视觉表示。
10-20 high-quality个人照片(jpg or png)例如您的、朋友的、产品或宠物等,并将它们放在特定的目录中。16GB or more的机器上运行。 (如果您要微调 SDXL,则需要 24GB VRAM。) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()就像让我们生成“一只猫坐在书架上”
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm是Ssebowa AI开发的开源视觉大语言模型(VLLM)。它是一个可以用来理解图像的强大工具。 Ssebowa-vllm拥有110亿个视觉参数和70亿个语言参数,支持1120*1120分辨率的图像理解。
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)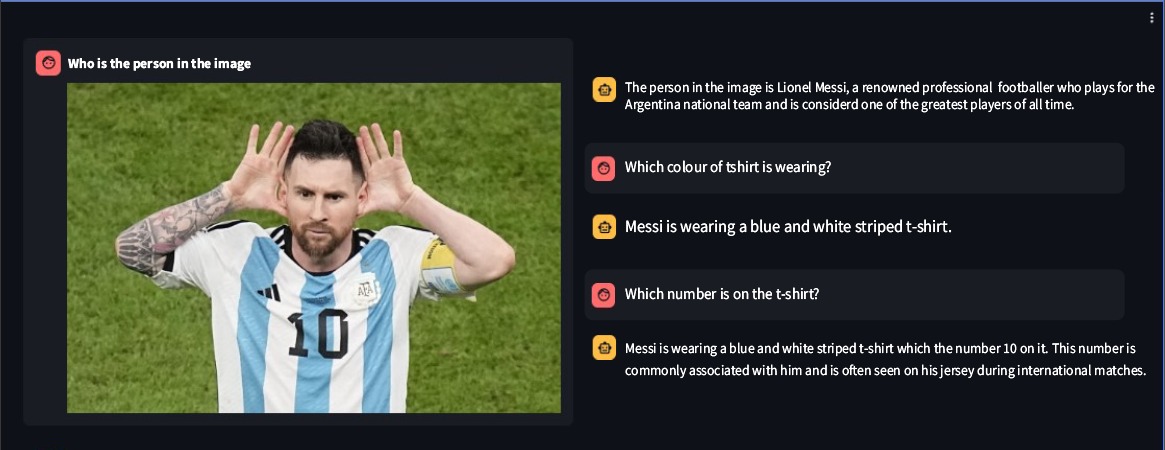
Ssebowa 开放供稿!指南正在进行中..
Ssebowa 是在 Apache License 2.0 下发布的。
如果您有任何问题或建议,请随时在 GitHub 上提出问题或通过 [email protected] 联系我们


