QuillGPT
1.0.0

QuillGPT 是 GPT 解码器块的实现,基于 Vaswani 等人的《Attention is All You Need》论文中的架构。等人。在 PyTorch 中实现。此外,该存储库还包含两个预训练模型——Shakespearean GPT 和 Harpoon GPT——及其训练过的权重。为了便于实验和部署,提供了 Streamlit Playground 来交互式探索这些模型,并使用 Docker 容器化实现 FastAPI 微服务以实现可扩展部署。您还将找到用于训练新 GPT 模型并对其进行推理的 Python 脚本,以及展示经过训练的模型的笔记本。为了促进文本编码和解码,实现了一个简单的分词器。探索 QuillGPT 以利用这些工具并增强您的自然语言处理项目!
该存储库中包含两个预先训练的模型和权重。
| 特征 | 莎士比亚GPT | 鱼叉GPT |
|---|---|---|
| 参数 | 10.7M | 226米 |
| 重量 | 重量 | 重量 |
| 型号配置 | 配置 | 配置 |
| 训练数据 | 莎士比亚戏剧中的文本 (input.txt) | 书籍中的随机文本 (corpus.txt) |
| 嵌入型 | 字符嵌入 | 字符嵌入 |
| 培训笔记本 | 笔记本 | 笔记本 |
| 硬件 | 英伟达T4 | 英伟达 A100 |
| 训练和验证损失 | 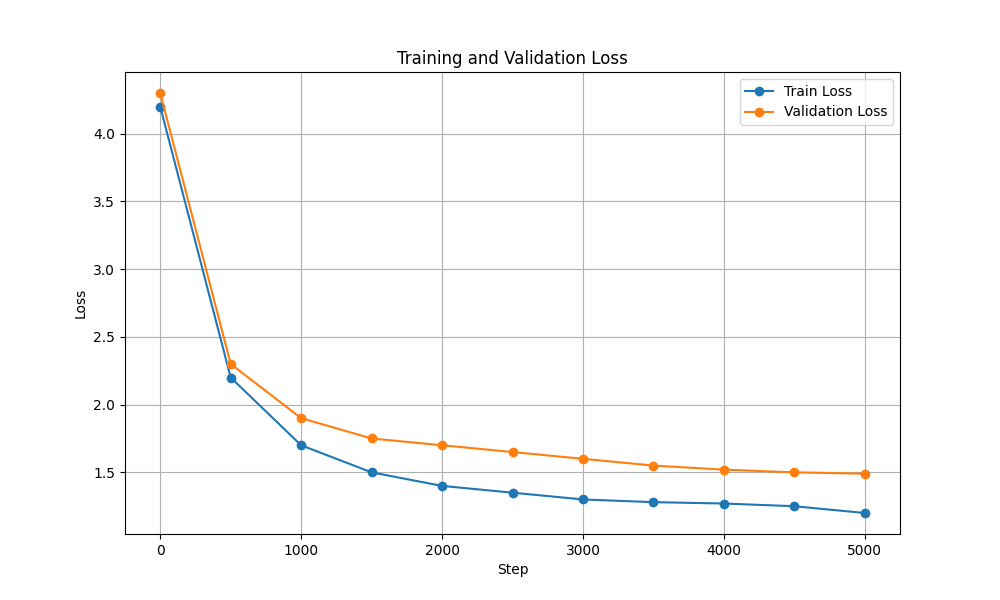 | 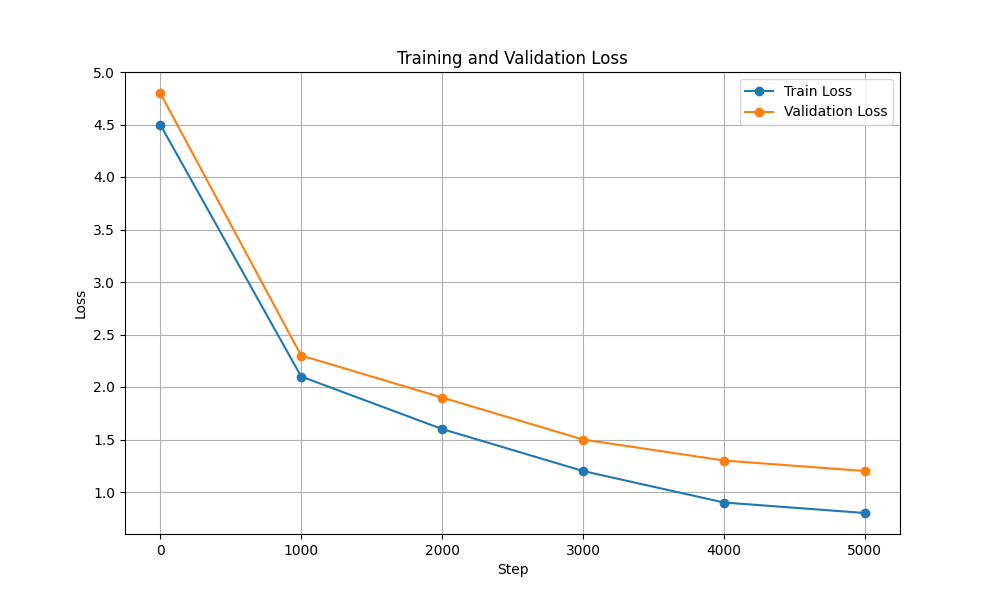 |
要运行训练和推理脚本,请执行以下步骤:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txt在继续之前,请确保从此处下载 Harpoon GPT 的权重!
它托管在 Streamlit 云服务上。您可以通过此处的链接访问它。
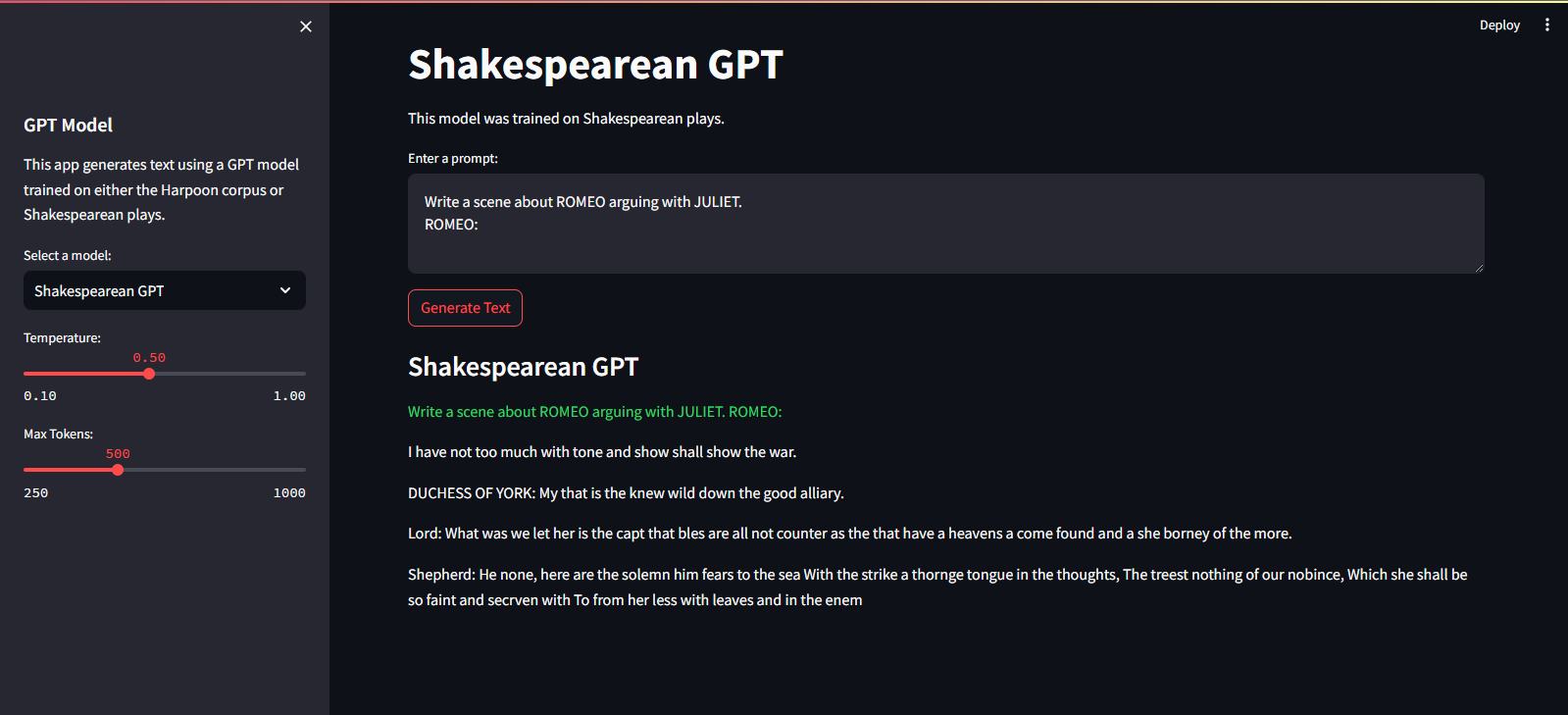
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-dev要训练 GPT 模型,请按照以下步骤操作:
准备数据。将整个文本数据放入单个 .txt 文件中并保存。
编写变压器的配置并保存文件。
例如: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
使用脚本scripts/train_gpt.py训练模型
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (您可以根据您的要求更改config_path 、 data_path和output_dir 。)
output_dir中。训练完成后,您可以使用训练好的GPT模型进行文本生成。以下是使用经过训练的模型进行推理的示例:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 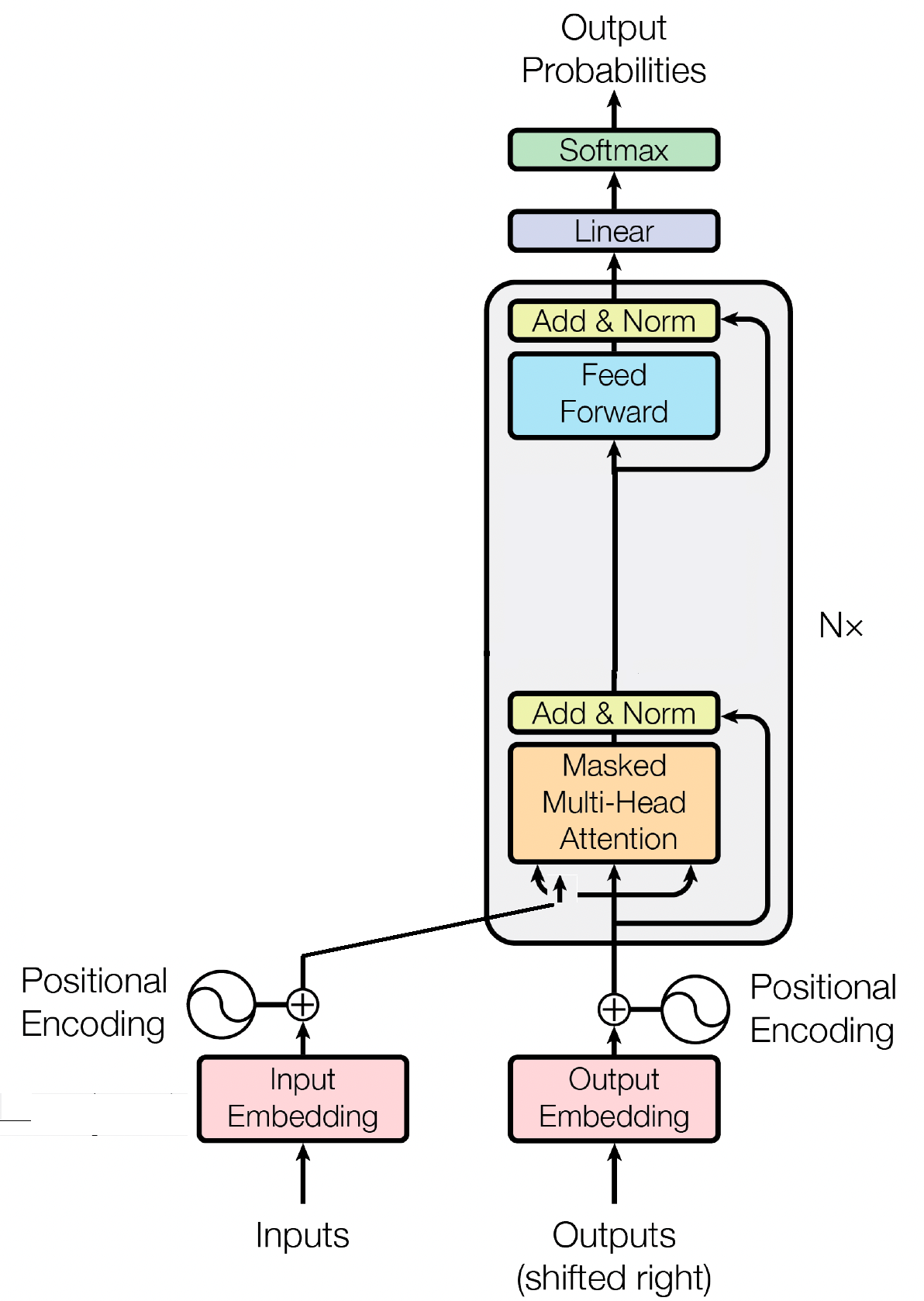
解码器块是 GPT(生成预训练变换器)模型的重要组成部分,它是 GPT 实际生成文本的地方。它利用自注意力机制来处理输入序列并生成一致的输出。每个解码器块由多个层组成,包括自注意力层、前馈神经网络和层归一化层。自注意力层允许模型权衡序列中不同单词的重要性,捕获上下文和依赖关系,无论它们的位置如何。这使得 GPT 模型能够生成上下文相关的文本。
输入嵌入通过将输入标记转换为有意义的数字表示,在 GPT 等基于转换器的模型中发挥着至关重要的作用。这些嵌入作为模型的初始输入,捕获有关序列中单词的语义信息。该过程涉及将输入序列中的每个标记映射到高维向量空间,其中相似的标记被放置得更靠近。这使得模型能够理解不同单词之间的关系并有效地从输入数据中学习。然后,输入嵌入被输入到模型的后续层中以进行进一步处理。
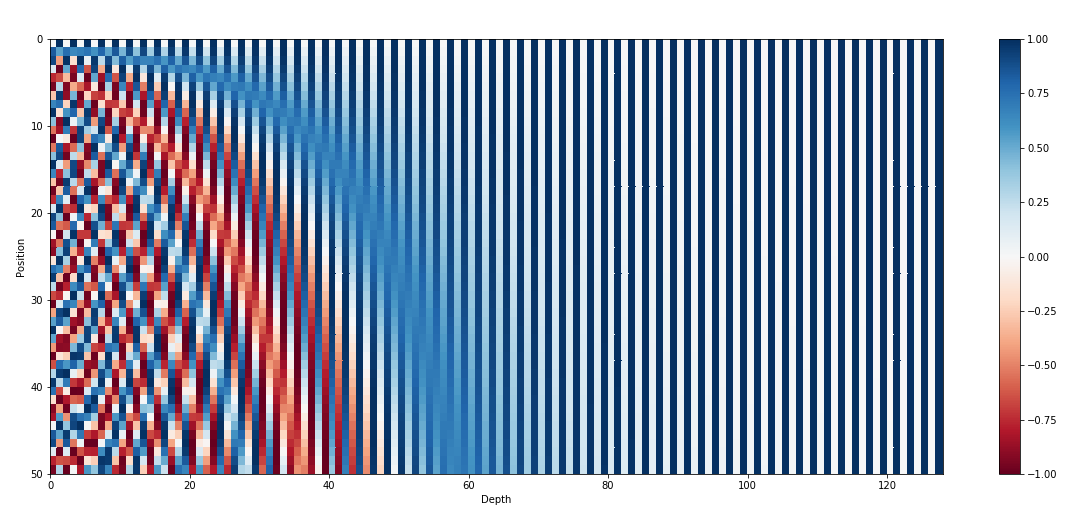
除了输入嵌入之外,位置嵌入是 GPT 等 Transformer 架构的另一个重要组成部分。由于转换器缺乏有关序列中标记顺序的固有信息,因此引入位置嵌入来为模型提供位置信息。这些嵌入对序列中每个标记的位置进行编码,允许模型根据标记的位置来区分标记。通过合并位置嵌入,GPT 等转换器可以有效地捕获数据的顺序性质并生成连贯的输出,从而保持生成文本中单词的正确顺序。

自注意力是 GPT 等基于 Transformer 的模型中的一种基本机制,它通过为序列中的不同单词分配重要性分数来运行。这个过程涉及三个关键步骤:计算注意力分数,应用softmax来获得注意力权重,最后将这些权重与输入嵌入相结合以生成上下文信息表示。从本质上讲,自注意力使模型能够更多地关注相关单词,同时弱化不太重要的单词,从而促进有效学习输入数据中的上下文依赖关系。这种机制对于捕获远程依赖关系和上下文细微差别至关重要,使 Transformer 模型能够生成长文本序列。
麻省理工学院 © Shrirang Mahajan
请随意提交拉取请求、创建问题或传播信息!
只需给这个存储库加注星标即可支持我!


