AttackVLM
1.0.0
[项目页面] | [幻灯片] | [arXiv] | [数据存储库]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

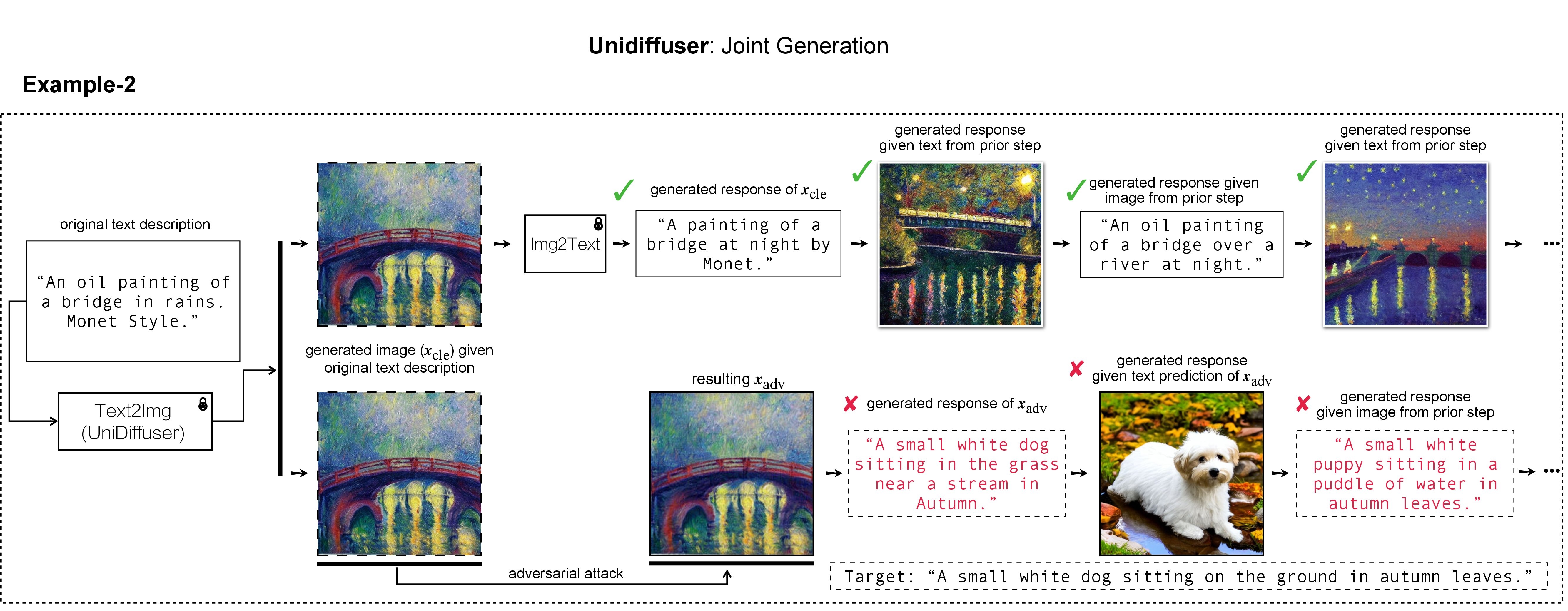
在我们的工作中,我们使用 DALL-E、Midjourney 和 Stable Diffusion 来生成和演示目标图像。对于大规模实验,我们应用稳定扩散来生成目标图像。为了安装稳定扩散,我们按照潜在扩散模型初始化 conda 环境。可以使用以下命令创建并激活名为ldm的合适的基础 conda 环境:
conda env create -f environment.yaml
conda activate ldm
请注意,对于不同的受害者模型,我们将遵循其官方实现和 conda 环境。
 正如我们论文中所讨论的,为了实现灵活的有针对性的攻击,我们利用预训练的文本到图像模型来生成目标图像,并将单个标题作为目标文本。这样你就可以自己指定攻击的目标标题了!
正如我们论文中所讨论的,为了实现灵活的有针对性的攻击,我们利用预训练的文本到图像模型来生成目标图像,并将单个标题作为目标文本。这样你就可以自己指定攻击的目标标题了!
我们在实验中使用 Stable Diffusion、DALL-E 或 Midjourney 作为文本到图像生成器。这里我们使用Stable Diffusion进行演示(感谢开源!)。
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
然后,从 MS-COCO 准备完整的目标字幕,或下载我们经过处理和清理的版本:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
并将其移至./stable-diffusion/ 。在实验中,可以随机采样 COCO 字幕的子集(例如10 、 100 、 1K 、 10K 、 50K )用于对抗性攻击。例如,假设我们随机采样了10K COCO 字幕作为目标文本 c_tar 并将它们存储在以下文件中:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
可以通过稳定扩散(Stable Diffusion)通过读取采样的 COCO 字幕中的文本提示,使用下面的脚本和txt2img_coco.py来获得目标图像 h_xi(c_tar) (请将txt2img_coco.py移至./stable-diffusion/ ,注意超参数可以是根据您的喜好进行调整):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
其中 ckpt 由 Stable Diffusion v1 提供,可以在此处下载:sd-v1-4-full-ema.ckpt。
通过稳定扩散生成文本到图像的其他实现细节可以在此处找到。
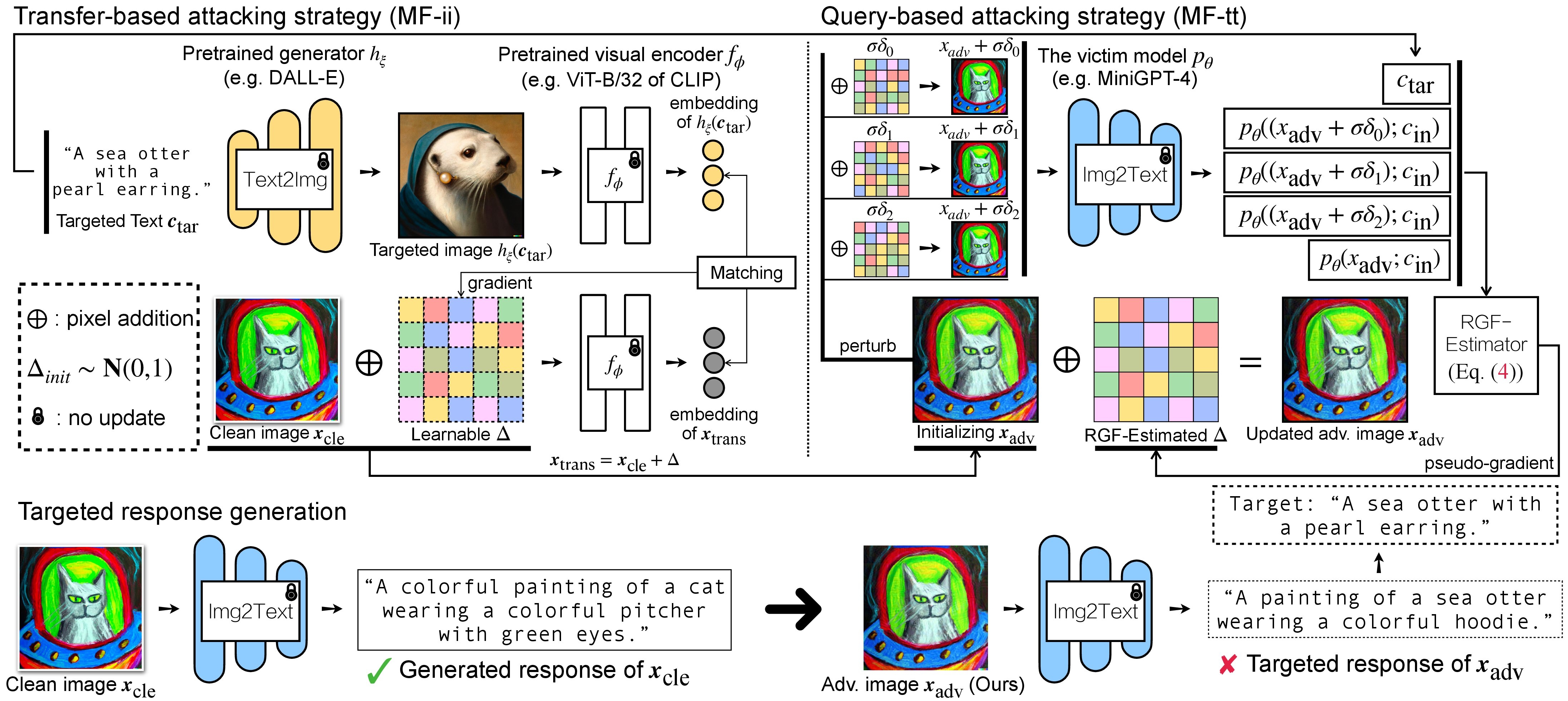
VLM 的对抗攻击有两个步骤:(1)基于传输的攻击策略和(2)使用(1)作为初始化的基于查询的攻击策略。对于 BLIP/BLIP-2/Img2Prompt 模型,请参考./LAVIS_tool 。这里我们以Unidiffuser为例。
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
然后,按照此处的步骤创建一个名为unidiffuser合适的conda环境,并准备相应的模型权重(我们使用uvit_v1.pth作为U-ViT的权重)。
conda activate unidiffuser
bash _train_adv_img_trans.sh
精心制作的广告图像 x_trans 将存储在--output指定dir of white-box transfer images中。然后,我们执行图像到文本并存储 x_trans 生成的响应。这可以通过以下方式实现:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
其中生成的响应将以.txt格式存储在dir of white-box transfer captions中。我们将通过 RGF 估计器使用它们进行伪梯度估计。
MF-ii + MF-tt使用固定扰动预算(例如,8 px) bash _train_trans_and_query_fixed_budget.sh
另一方面,如果您想使用单独的扰动预算进行基于传输+查询的攻击,我们还提供了一个脚本:
bash _train_trans_and_query_more_budget.sh
在这里,我们使用wandb动态监控 CLIP 分数(例如 RN50、ViT-B/32、ViT-L/14 等)的移动平均值,以评估 (a) 生成的响应(trans/查询图像)和(b)预定义的目标文本c_tar 。
如下所示的示例,其中虚线表示查询后(图像标题的)CLIP 分数的移动平均值: 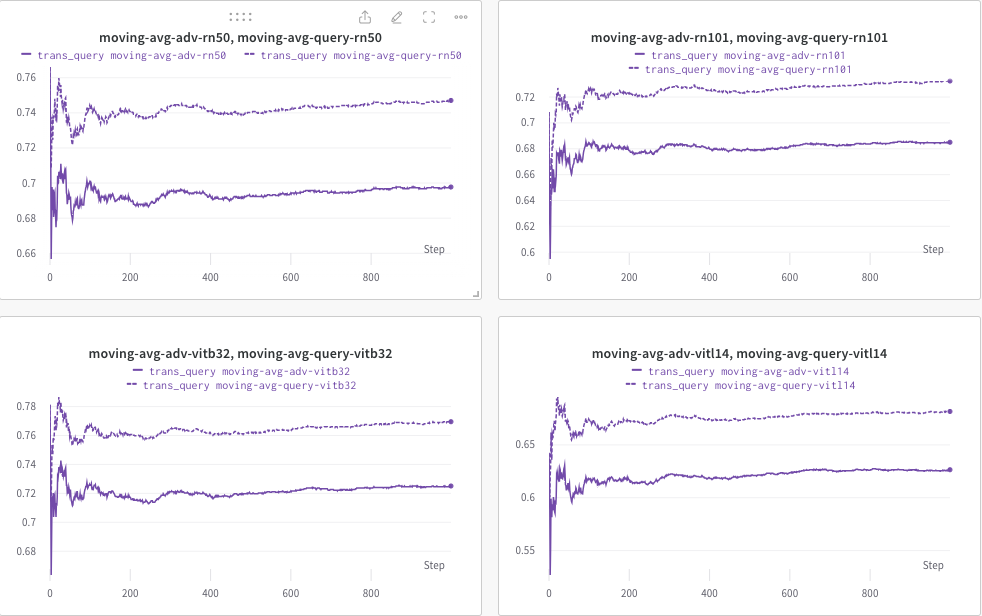
同时,查询后的图像标题会被存储,目录可以通过--output指定。
如果您发现该项目对您的研究有用,请考虑引用我们的论文:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
同时,一项旨在将水印嵌入到(多模态)扩散模型的相关研究:
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
我们赞赏 MiniGPT-4、LLaVA、Unidiffuser、LAVIS 和 CLIP 的出色基础实现。我们还感谢 @MetaAI 开源他们的 LLaMA checkponts。我们感谢 SiSi 在我们的研究中提供了一些由 @Midjourney 生成的令人愉快且视觉上愉悦的图像。


