SDV
v1.17.2 - 2024-11-18
该存储库是 DataCebo 的综合数据仓库项目的一部分。



Synthetic Data Vault (SDV) 是一个 Python 库,旨在成为您创建表格合成数据的一站式商店。 SDV 使用各种机器学习算法从真实数据中学习模式并在合成数据中模拟它们。
?使用机器学习创建合成数据。 SDV 提供多种模型,从经典统计方法(GaussianCopula)到深度学习方法(CTGAN)。为单个表、多个连接表或顺序表生成数据。
评估和可视化数据。根据各种措施将合成数据与真实数据进行比较。诊断问题并生成质量报告以获得更多见解。
预处理、匿名化和定义约束。控制数据处理以提高合成数据的质量,选择不同类型的匿名化并以逻辑约束的形式定义业务规则。
| 重要链接 | |
|---|---|
 教程 教程 | 获得一些 SDV 的实践经验。启动教程笔记本并自行运行代码。 |
| 文档 | 通过用户指南和 API 参考了解如何使用 SDV 库。 |
| ?博客 | 获取有关使用 SDV、部署模型和我们的合成数据社区的更多见解。 |
 社区 社区 | 加入我们的 Slack 工作区以获取公告和讨论。 |
| 网站 | 请访问 SDV 网站,了解有关该项目的更多信息。 |
SDV 根据商业源许可证公开提供。使用 pip 或 conda 安装 SDV。我们建议使用虚拟环境以避免与设备上的其他软件发生冲突。
pip install sdvconda install -c pytorch -c conda-forge sdv加载演示数据集以开始使用。该数据集是一个描述入住虚构酒店的客人的表。
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )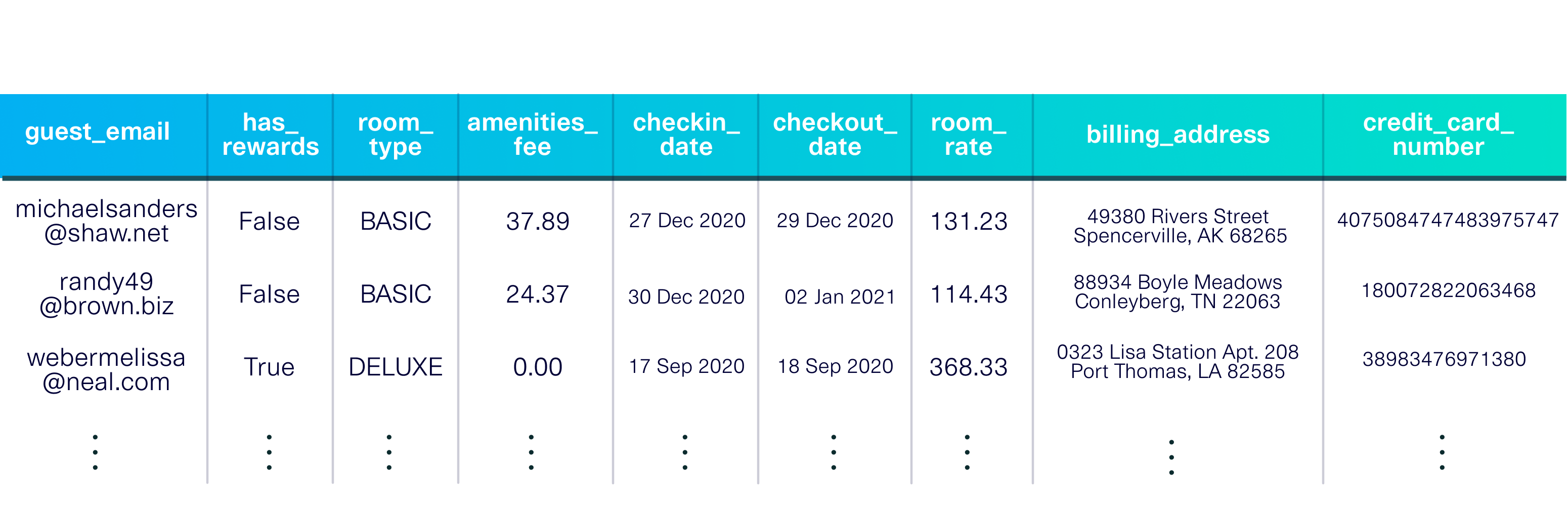
该演示还包括元数据、数据集的描述,包括每列中的数据类型和主键 ( guest_email )。
接下来,我们可以创建一个SDV 合成器,这是一个可用于创建合成数据的对象。它从真实数据中学习模式并复制它们以生成合成数据。让我们使用 GaussianCopulaSynthesizer。
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )现在合成器已准备好创建合成数据!
synthetic_data = synthesizer . sample ( num_rows = 500 )合成数据将具有以下属性:
SDV 库允许您通过将合成数据与真实数据进行比较来评估合成数据。首先生成质量报告。
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
该对象计算 0 到 100% 范围内的总体质量得分(100 为最佳)以及详细的细分。要获得更多见解,您还可以可视化合成数据与真实数据。
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()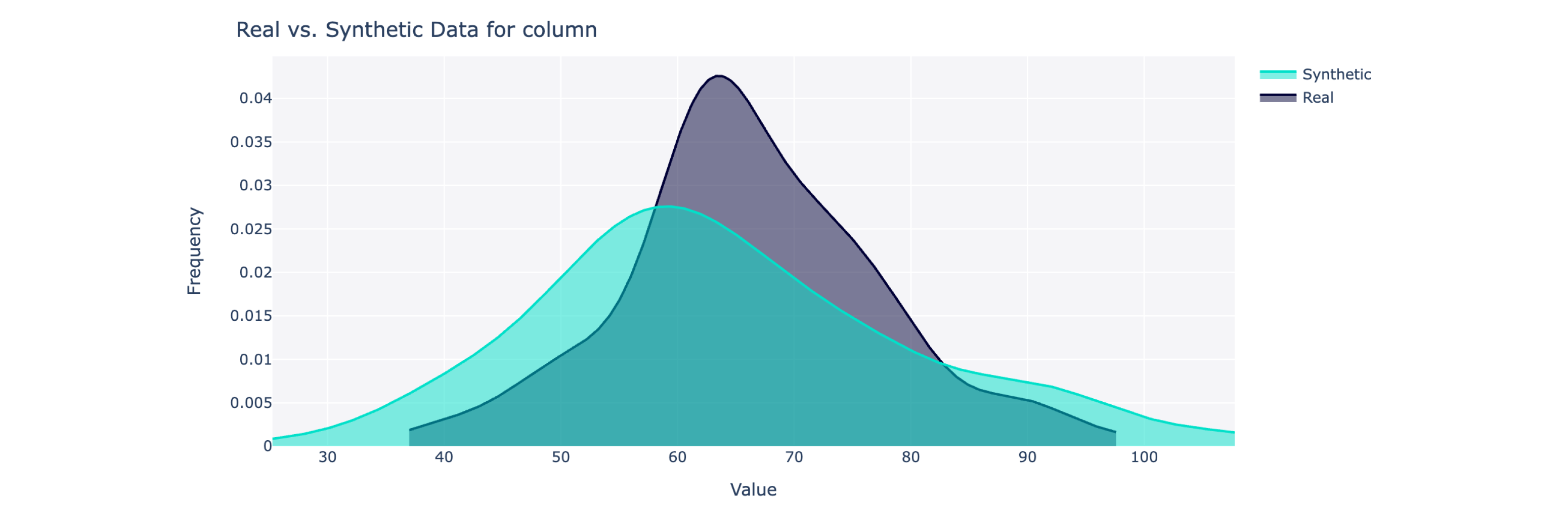
使用SDV库,您可以合成单表、多表和顺序数据。您还可以自定义完整的合成数据工作流程,包括预处理、匿名化和添加约束。
要了解更多信息,请访问 SDV 演示页面。
感谢我们多年来构建和维护 SDV 生态系统的贡献者团队!
查看贡献者
如果您使用 SDV 进行研究,请引用以下论文:
尼哈·帕特基、罗伊·韦奇、卡扬·维拉马查内尼。综合数据库。 IEEE DSAA 2016。
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
综合数据库项目于 2016 年在麻省理工学院的数据到人工智能实验室首次创建。经过 4 年的研究和企业的推动,我们于 2020 年创建了 DataCebo,目标是发展该项目。如今,DataCebo 是 SDV 的自豪开发商,SDV 是最大的合成数据生成和评估生态系统。它是多个支持合成数据的库的所在地,包括:
开始使用 SDV 包——一个完全集成的解决方案和合成数据的一站式商店。或者,使用独立库来满足特定需求。


