细粒度后期交互多模态检索器的 Huggingface-transformers 实现。
官方的实现在这里。
模型和检查点的详细信息可以在此处找到。
论文中复制数据集和评估的详细信息可以在这里找到。
| 模型 | WIT 召回@10 | IGLUE 召回@1 | KVQA 召回@5 | MSMARCO 召回@5 | 烤箱召回@5 | LLaVA 召回@1 | EVQA 召回@5 | EVQA 伪召回@5 | OKVQA 召回@5 | OKVQA 伪召回@5 | Infoseek 召回@5 | Infoseek 伪召回@5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 林伟哲龙/PreFLMR_ViT-G? | 0.619 | 0.718 | 0.419 | 0.783 | 0.643 | 0.726 | 0.625 | 0.721 | 0.302 | 0.674 | 0.392 | 0.577 |
| 林伟哲龙/PreFLMR_ViT-L? | 0.605 | 0.699 | 0.440 | 0.779 | 0.608 | 0.729 | 0.609 | 0.708 | 0.314 | 0.690 | 0.374 | 0.578 |
| 林伟哲龙/PreFLMR_ViT-B? | 0.427 | 0.574 | 0.294 | 0.786 | 0.468 | 0.673 | 0.550 | 0.663 | 0.272 | 0.658 | 0.260 | 0.496 |
注意:我们将检查点从 PyTorch 转换为 Huggingface-transformers,其基准测试结果与原始论文中报告的数字略有不同。您可以参考本文档中的说明重现上述论文中的结果。
创建虚拟环境:
conda create -n FLMR python=3.10 -y
conda activate FLMR
安装 Pytorch:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
安装费斯
conda install -c pytorch -c nvidia faiss-gpu=1.7.4 mkl=2021 blas=1.0=mkl
测试faiss是否产生错误
python -c "import faiss"
安装 FLMR
git clone https://github.com/LinWeizheDragon/FLMR.git
cd FLMR
pip install -e .
安装 ColBERT 引擎
cd third_party/ColBERT
pip install -e .
安装其他依赖项
pip install ujson gitpython easydict ninja datasets transformers
加载预训练模型
import os
import torch
import pandas as pd
import numpy as np
from torchvision . transforms import ToPILImage
from transformers import AutoImageProcessor
from flmr import index_custom_collection
from flmr import FLMRQueryEncoderTokenizer , FLMRContextEncoderTokenizer , FLMRModelForRetrieval
# load models
checkpoint_path = "LinWeizheDragon/PreFLMR_ViT-G"
image_processor_name = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
query_tokenizer = FLMRQueryEncoderTokenizer . from_pretrained ( checkpoint_path , subfolder = "query_tokenizer" )
context_tokenizer = FLMRContextEncoderTokenizer . from_pretrained (
checkpoint_path , subfolder = "context_tokenizer"
)
model = FLMRModelForRetrieval . from_pretrained (
checkpoint_path ,
query_tokenizer = query_tokenizer ,
context_tokenizer = context_tokenizer ,
)
image_processor = AutoImageProcessor . from_pretrained ( image_processor_name )创建文档集合
num_items = 100
feature_dim = 1664
passage_contents = [ f"This is test sentence { i } " for i in range ( num_items )]
# Option 1. text-only documents
custom_collection = passage_contents
# Option 2. multi-modal documents with pre-extracted image features
# passage_image_features = np.random.rand(num_items, feature_dim)
# custom_collection = [
# (passage_content, passage_image_feature, None) for passage_content, passage_image_feature in zip(passage_contents, passage_image_features)
# ]
# Option 3. multi-modal documents with images
# random_images = torch.randn(num_items, 3, 224, 224)
# to_img = ToPILImage()
# if not os.path.exists("./test_images"):
# os.makedirs("./test_images")
# for i, image in enumerate(random_images):
# image = to_img(image)
# image.save(os.path.join("./test_images", "{}.jpg".format(i)))
# image_paths = [os.path.join("./test_images", "{}.jpg".format(i)) for i in range(num_items)]
# custom_collection = [
# (passage_content, None, image_path)
# for passage_content, image_path in zip(passage_contents, image_paths)
# ]对自定义集合运行索引
index_custom_collection (
custom_collection = custom_collection ,
model = model ,
index_root_path = "." ,
index_experiment_name = "test_experiment" ,
index_name = "test_index" ,
nbits = 8 , # number of bits in compression
doc_maxlen = 512 , # maximum allowed document length
overwrite = True , # whether to overwrite existing indices
use_gpu = False , # whether to enable GPU indexing
indexing_batch_size = 64 ,
model_temp_folder = "tmp" ,
nranks = 1 , # number of GPUs used in indexing
)创建玩具查询数据
num_queries = 2
query_instructions = [ f"instruction { i } " for i in range ( num_queries )]
query_texts = [ f" { query_instructions [ i ] } : query { i } " for i in range ( num_queries )]
query_images = torch . zeros ( num_queries , 3 , 224 , 224 )
query_encoding = query_tokenizer ( query_texts )
query_pixel_values = image_processor ( query_images , return_tensors = "pt" )[ 'pixel_values' ]使用模型获取查询嵌入
inputs = dict (
input_ids = query_encoding [ 'input_ids' ],
attention_mask = query_encoding [ 'attention_mask' ],
pixel_values = query_pixel_values ,
)
# Run model query encoding
res = model . query ( ** inputs )
queries = { i : query_texts [ i ] for i in range ( num_queries )}
query_embeddings = res . late_interaction_output搜索集合
from flmr import search_custom_collection , create_searcher
# initiate a searcher
searcher = create_searcher (
index_root_path = "." ,
index_experiment_name = "test_experiment" ,
index_name = "test_index" ,
nbits = 8 , # number of bits in compression
use_gpu = True , # whether to enable GPU searching
)
# Search the custom collection
ranking = search_custom_collection (
searcher = searcher ,
queries = queries ,
query_embeddings = query_embeddings ,
num_document_to_retrieve = 5 , # how many documents to retrieve for each query
)
# Analyse retrieved documents
ranking_dict = ranking . todict ()
for i in range ( num_queries ):
print ( f"Query { i } retrieved documents:" )
retrieved_docs = ranking_dict [ i ]
retrieved_docs_indices = [ doc [ 0 ] for doc in retrieved_docs ]
retrieved_doc_scores = [ doc [ 2 ] for doc in retrieved_docs ]
retrieved_doc_texts = [ passage_contents [ doc_idx ] for doc_idx in retrieved_docs_indices ]
data = {
"Confidence" : retrieved_doc_scores ,
"Content" : retrieved_doc_texts ,
}
df = pd . DataFrame . from_dict ( data )
print ( df ) import torch
from flmr import FLMRQueryEncoderTokenizer , FLMRContextEncoderTokenizer , FLMRModelForRetrieval
checkpoint_path = "LinWeizheDragon/PreFLMR_ViT-L"
image_processor_name = "openai/clip-vit-large-patch14"
query_tokenizer = FLMRQueryEncoderTokenizer . from_pretrained ( checkpoint_path , subfolder = "query_tokenizer" )
context_tokenizer = FLMRContextEncoderTokenizer . from_pretrained ( checkpoint_path , subfolder = "context_tokenizer" )
model = FLMRModelForRetrieval . from_pretrained ( checkpoint_path ,
query_tokenizer = query_tokenizer ,
context_tokenizer = context_tokenizer ,
)
Q_encoding = query_tokenizer ([ "Using the provided image, obtain documents that address the subsequent question: What is the capital of France?" , "Extract documents linked to the question provided in conjunction with the image: What is the capital of China?" ])
D_encoding = context_tokenizer ([ "Paris is the capital of France." , "Beijing is the capital of China." ,
"Paris is the capital of France." , "Beijing is the capital of China." ])
Q_pixel_values = torch . zeros ( 2 , 3 , 224 , 224 )
inputs = dict (
query_input_ids = Q_encoding [ 'input_ids' ],
query_attention_mask = Q_encoding [ 'attention_mask' ],
query_pixel_values = Q_pixel_values ,
context_input_ids = D_encoding [ 'input_ids' ],
context_attention_mask = D_encoding [ 'attention_mask' ],
use_in_batch_negatives = True ,
)
res = model . forward ( ** inputs )
print ( res )请注意,此代码块中的示例仅用于演示目的。他们表明,预先训练的模型可以为正确的文档提供更高的分数。在实际训练中,您总是需要按照“查询1的正文档,查询1的负文档1,查询1的负文档2,...,查询2的正文档,查询2的负文档1,查询2的负文档2”的顺序传入文档, ……”。您可能需要阅读后面的部分,其中提供了示例微调脚本。
pip install transformers
from transformers import AutoConfig , AutoModel , AutoImageProcessor , AutoTokenizer
import torch
checkpoint_path = "LinWeizheDragon/PreFLMR_ViT-L"
image_processor_name = "openai/clip-vit-large-patch14"
query_tokenizer = AutoTokenizer . from_pretrained ( checkpoint_path , subfolder = "query_tokenizer" , trust_remote_code = True )
context_tokenizer = AutoTokenizer . from_pretrained ( checkpoint_path , subfolder = "context_tokenizer" , trust_remote_code = True )
model = AutoModel . from_pretrained ( checkpoint_path ,
query_tokenizer = query_tokenizer ,
context_tokenizer = context_tokenizer ,
trust_remote_code = True ,
)
image_processor = AutoImageProcessor . from_pretrained ( image_processor_name )我们提供两个脚本来展示如何在评估中使用预训练模型:
examples/example_use_flmr.py :在 OK-VQA 上评估 FLMR(具有 10 个 ROI)的示例脚本。examples/example_use_preflmr.py :在 E-VQA 上评估 PreFLMR 的示例脚本。 cd examples/从此处下载KBVQA_data并解压缩图像文件夹。 ROI/字幕/对象检测结果已包含在内。
运行以下命令(如果您已经运行过一次索引,请删除--run_indexing ):
python example_use_flmr.py
--use_gpu --run_indexing
--index_root_path " . "
--index_name OKVQA_GS
--experiment_name OKVQA_GS
--indexing_batch_size 64
--image_root_dir /path/to/KBVQA_data/ok-vqa/
--dataset_path BByrneLab/OKVQA_FLMR_preprocessed_data
--passage_dataset_path BByrneLab/OKVQA_FLMR_preprocessed_GoogleSearch_passages
--use_split test
--nbits 8
--Ks 1 5 10 20 50 100
--checkpoint_path LinWeizheDragon/FLMR
--image_processor_name openai/clip-vit-base-patch32
--query_batch_size 8
--num_ROIs 9 您可以从 https://github.com/google-research/google-research/tree/master/encyclopedic_vqa 下载 E-VQA 图像。我们很快将在此处添加数据集链接。
cd examples/运行以下命令(如果您已经运行过一次索引,请删除--run_indexing ):
python example_use_preflmr.py
--use_gpu --run_indexing
--index_root_path " . "
--index_name EVQA_PreFLMR_ViT-G
--experiment_name EVQA
--indexing_batch_size 64
--image_root_dir /rds/project/rds-hirYTW1FQIw/shared_space/vqa_data/KBVQA_data/EVQA/eval_image/
--dataset_hf_path BByrneLab/multi_task_multi_modal_knowledge_retrieval_benchmark_M2KR
--dataset EVQA
--use_split test
--nbits 8
--Ks 1 5 10 20 50 100 500
--checkpoint_path LinWeizheDragon/PreFLMR_ViT-G
--image_processor_name laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
--query_batch_size 8
--compute_pseudo_recall 在这里,我们将所有 M2KR 数据集上传到一个 HF 数据集BByrneLab/multi_task_multi_modal_knowledge_retrieval_benchmark_M2KR中,并以不同的数据集作为子集。要重现本文中其他数据集的结果,您可以将--dataset更改为OKVQA 、 KVQA 、 LLaVA 、 OVEN 、 Infoseek 、 WIT 、 IGLUE和EVQA 。
更新:
--compute_pseudo_recall来计算 EVQA/OKVQA/Infoseek 等数据集的伪召回率--Ks 1 5 10 20 50 100 500 :max(Ks) 需要为 500 才能匹配 PreFLMR 论文中报告的性能。更改examples/evaluate_all.sh中的镜像根路径并执行:
cd examples
bash evaluate_all.sh通过以下方式获取报告:
python report.py您需要安装 pytorch-lightning:
pip install pytorch-lightning==2.1.0
python example_finetune_preflmr.py
--image_root_dir /path/to/EVQA/images/
--dataset_hf_path BByrneLab/multi_task_multi_modal_knowledge_retrieval_benchmark_M2KR
--dataset EVQA
--freeze_vit
--log_with_wandb
--model_save_path saved_models
--checkpoint_path LinWeizheDragon/PreFLMR_ViT-G
--image_processor_name laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
--batch_size 8
--accumulate_grad_batches 8
--valid_batch_size 16
--test_batch_size 64
--mode train
--max_epochs 99999999
--learning_rate 0.000005
--warmup_steps 100
--accelerator auto
--devices auto
--strategy ddp_find_unused_parameters_true
--num_sanity_val_steps 2
--precision bf16
--val_check_interval 2000
--save_top_k -1 python example_use_preflmr.py
--use_gpu --run_indexing
--index_root_path " . "
--index_name EVQA_PreFLMR_ViT-G_finetuned_model_step_10156
--experiment_name EVQA
--indexing_batch_size 64
--image_root_dir /path/to/EVQA/images/
--dataset_hf_path BByrneLab/multi_task_multi_modal_knowledge_retrieval_benchmark_M2KR
--dataset EVQA
--use_split test
--nbits 8
--num_gpus 1
--Ks 1 5 10 20 50 100 500
--checkpoint_path saved_models/model_step_10156
--image_processor_name laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
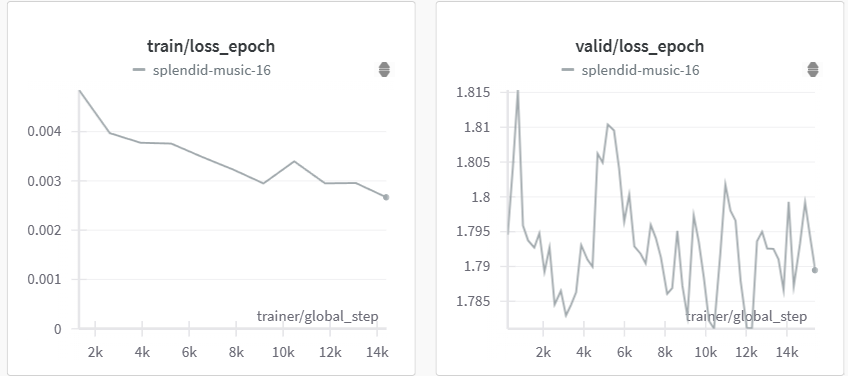
--query_batch_size 8 通过运行上面的脚本,我们可以获得以下微调性能:
| 步 | EVQA 上的伪召回@5 |
|---|---|
| 2500 | 73.6 |
| 10000 | 73.55 |
| 12000 | 74.21 |
| 14000 | 73.73 |
(选择并测试了验证损失较低的检查点,在 2 个 A100 GPU 上运行)
FLMR 模型是按照transformers的文档风格实现的。您可以在建模文件中找到详细的文档。
如果我们的工作对您的研究有帮助,请引用我们关于 FLMR 和 PreFLMR 的论文。
@inproceedings{
lin2023finegrained,
title={Fine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering},
author={Weizhe Lin and Jinghong Chen and Jingbiao Mei and Alexandru Coca and Bill Byrne},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=IWWWulAX7g}
}
@inproceedings{lin-etal-2024-preflmr,
title = "{P}re{FLMR}: Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers",
author = "Lin, Weizhe and
Mei, Jingbiao and
Chen, Jinghong and
Byrne, Bill",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.289",
pages = "5294--5316",
abstract = "Large Multimodal Models (LMMs) excel in natural language and visual understanding but are challenged by exacting tasks such as Knowledge-based Visual Question Answering (KB-VQA) which involve the retrieval of relevant information from document collections to use in shaping answers to questions. We present an extensive training and evaluation framework, M2KR, for KB-VQA. M2KR contains a collection of vision and language tasks which we have incorporated into a single suite of benchmark tasks for training and evaluating general-purpose multi-modal retrievers. We use M2KR to develop PreFLMR, a pre-trained version of the recently developed Fine-grained Late-interaction Multi-modal Retriever (FLMR) approach to KB-VQA, and we report new state-of-the-art results across a range of tasks. We also present investigations into the scaling behaviors of PreFLMR intended to be useful in future developments in general-purpose multi-modal retrievers.",
}


