图像火灾检测
该存储库的目的是演示火灾探测神经网络模型。在使用中,该模型将在图像中的任何火灾周围放置一个边界框。

最好的结果
对象检测:在尝试了各种模型架构之后,我选择了 Yolov5 pytorch 模型(请参阅pytorch/object-detection/yolov5/experiment1/best.pt )。经过几个小时的实验,我生成了一个[email protected]为 0.657、精度为 0.6、召回率为 0.7 的模型,在 1155 个图像(337 个基础图像 + 增强图像)上进行训练。
分类:我还没有训练自己的模型,但使用 ResNet50 的准确率达到 95%
分段:需要注释
动机和挑战
传统的烟雾探测器通过检测烟雾颗粒的物理存在来工作。然而,它们很容易出现错误检测(例如来自烤面包机)并且不能很好地定位火灾。在这些情况下,摄像头解决方案可以补充传统探测器,以缩短响应时间或提供额外的指标,例如火灾的大小和位置。确定火灾的位置和性质后,可以进行自动干预,例如通过喷水灭火系统或无人机。数据还可以发送到消防部门,以提供原本不存在的态势感知。我感兴趣的具体位置是:厨房和客厅、车库和附属建筑,以及可能已经发生火灾但蔓延到所需区域(例如火坑)之外的区域。
有一些重大挑战和悬而未决的问题:
- 对于快速边缘模型,什么是“最佳”架构? Yolo3 在商业应用中非常流行,可以在 keras 或 pytorch 中实现,基线 Yolov5,因为它目前是 SOTA,并且有 Jetson 的部署指南。
- 由于我们只检测单个类,是否可以优化架构?
- 基线对象检测,但是分类器或分割有好处吗? Obj 模型根据 mAP 和 Recall 指标进行训练,但对于我们的应用程序来说,边界框准确性可能不是首要任务?然而,分类模型在仅包含目标对象的漂亮镜头上效果最好,但在现实生活中的火灾场景中,场景不会像这个场景那么简单。
- Tensorflow + 谷歌生态系统还是 Pytorch + NVIDIA/MS? Tensorflow 受到 tf1 遗留问题的影响
- 是单个“超级”模型更可取,还是多个专门模型更可取?典型的火灾类别包括蜡烛火焰、室内/室外火灾、车辆火灾
- 收集或查找全面、有代表性和平衡的训练数据集
- 处理不同的视点、不同的相机制造商和设置以及不同的环境照明条件。
- 由于火焰非常明亮,常常会冲掉图像并造成其他光学干扰,如何对此进行补偿?
- 既然我们预计模型会有局限性,那么我们如何使模型结果具有可解释性呢?
- 火灾的大小范围非常广泛,从蜡烛火焰到吞没整个森林 - 这是一个小物体和大物体的问题吗?按火灾类别和每个类别的训练模型分割数据集可能会给出更好的结果?视为语义分割问题(需要重新注释数据集)?
想法:
- 预处理图像,例如去除背景或应用滤镜
- 对短视频序列进行分类,因为火的运动非常有特征
- 模拟数据,识别任何可以生成真实火灾的软件并添加到现有数据集
- 增强模拟不同相机和曝光设置的效果
- 确定有关火灾探测技术所需准确性的任何相关指南/立法
- 结合 RGB + 热成像来抑制误报?例如使用 https://openmv.io/blogs/news/introducing-the-openmv-cam-pure- Thermal 或更便宜的 grideye 或 melexsis
方法和工具
- 帧将通过神经网络馈送。在积极检测到火灾时提取指标。忽略烟雾以获得 MVP。尝试各种架构和参数来建立“良好”的基线模型。
- 开发针对 RPi 和移动设备的精度较低但速度较快的模型,以及针对 Jetson 等 GPU 设备的高精度模型。 Yolo 提供了两个选项,用于移动设备的 yolo4 lite 和用于 GPU 的 yolo5。或者还有 mobilenet 和 tf-object-detection-api。精度较高的 GPU 模型优先。
- 使用Google Colab进行训练
文章和存储库
- Fire_Detection -> 使用 Jetson nano 和 Yolov5 以及来自 gettyimages 的图像数据集的火灾和烟雾检测系统
- 使用 Roboflow 以及权重和偏差进行 YOLOv5 野火烟雾检测
- Yolov5-Fire-Detection -> 在 Kaggle 数据上训练的记录良好的模型
- 使用 Keras 进行火灾和烟雾检测以及 pyimagesearch 的深度学习 - 通过抓取 Google 图像收集的数据集(提供包含 1315 个火灾图像的数据集的链接),使用 tf2 和 keras 顺序 CNN 进行二进制火灾/非火灾分类,达到 92% 的准确度,得出结论:需要更好的数据集
- 使用 YOLOv3 从头开始进行火灾检测 - 讨论使用 LabelImg 进行注释,使用 Google Drive 和 Colab,通过 Heroku 进行部署,并在此处使用 Streamlit 进行可视化。德夫达尔尚·米什拉的作品
- fire-and-gun-detection -> 在视频和图像中使用 yolov3 进行火灾和枪支检测。提供训练代码、数据集和训练权重文件。
- YOLOv3-Cloud-Based-Fire-Detection -> 在云上使用 YOLOv3 自定义对象检测。它经过训练可以检测给定帧中的火灾。可大量用于野火、火灾事故等。
- fire-detect-yolov4 -> Yolo v4 模型的训练
- midasklr/FireSmokeDetectionByEfficientNet - 使用efficientnet进行火灾和烟雾分类和检测,Python 3.7、PyTorch1.3,可视化激活图,包括训练和推理脚本
- arpit-jadon/FireNet-LightWeight-Network-for-Fire-Detection - 用于实时物联网应用(例如在 RPi 上)的专用轻量级火灾和烟雾检测模型,精度约为。 95%。论文 https://arxiv.org/abs/1905.11922v2
- tobybreckon/fire-detection-cnn - 链接到几个数据集
- EmergencyNet - 通过无人机识别火灾和其他紧急情况
- 使用闭路电视图像进行火灾检测 — Monk 库应用程序 - Kaggle 数据集、mobilenet-v2、densenet121 和 dendensenet201 上的 keras 分类器
- fire-detection-cnn - 在实时范围内自动检测视频(或静态)图像中的火灾像素区域。全图像二值火灾检测 (1) 的最大准确度为 0.93,在我们的超像素定位框架内可实现 0.89 的准确度
- 使用深度学习和 OpenCV 的早期火灾检测系统 - 用于室内和室外火灾检测的定制 InceptionV3 和 CNN 架构。 980 张图像用于训练,239 张图像用于验证,训练准确度为 98.04,验证准确度为 96.43,openCV 用于网络摄像头实时检测 - 代码和数据集(已在此处引用)位于 https://github.com/jackfrost1411/fire-检测
- Smoke-Detection-using-Tensorflow 2.2 - EfficientDet-D0,Roboflow 博客中提到的 733 个带注释的烟雾图像
- 用于火灾探测的航空图像数据集:使用无人机 (UAV) 进行分类和分割 - 二元分类器,测试集的准确度为 76%
- 基于集成学习的森林火灾检测系统 -> 首先,集成两个个体学习器 Yolov5 和 EfficientDet 来完成火灾检测过程。其次,另一个个体学习器EfficientNet负责学习全局信息以避免误报
- GradCAM 解释的具有多标签分类模型的火灾警报系统 -> 使用 CAM 可视化图像的哪个区域负责预测,并使用合成数据来填充缺少的类别以使类别分布平衡
- 训练 fast.ai 模型并通过 gradio 应用程序进行部署
- Deepfire -> 使用ResNet50和EfficientNetB7对无人机进行森林火灾识别
- Wildfire-Smoke-Detection -> 基于 Faster-RCNN 架构的用于野火烟雾检测的卷积神经网络模型
- FireNet-LightWeight-Network-for-Fire-Detection -> 采用 ArXiv 论文的用于实时物联网应用的专用轻量级火灾和烟雾检测模型
- 野火烟雾检测研究 -> 早期野火烟雾检测,带纸质
数据集
- FireNET - 约。 500 张带边界框的火焰图像,采用 pascal voc XML 格式。 Repo 包含使用 imageai 训练的 Yolo3 模型,性能未知。然而,图像很小,平均为 275x183 像素,这意味着网络需要学习的纹理特征较少。
- Kaggle 上的 CCTV 火灾检测 - 图像和视频,图像是从视频中提取的,数据集相对较小,所有图像仅取自 3-4 个视频。与当前任务非常相关,因为有视频可供测试。为正常/烟雾/火灾分类任务组织的数据集,无边界框注释
- cair/Fire-Detection-Image-Dataset - 该数据集包含许多正常图像和 111 张火灾图像。数据集与现实世界的情况高度不平衡。图像大小合适,但没有注释。
- mivia 火灾探测数据集 - 大约。 30 个视频
- USTC 烟雾检测 - 提供烟雾视频的各种来源的链接
- 可以下载 pyimagesearch 文章中的 fire/not-fire 数据集。请注意,有许多火灾场景的图像并不包含实际的火灾,而是例如被烧毁的房屋。
- Kaggle 上的火灾数据集 - 755 个室外火灾图像和 244 个非火灾图像。图像大小合适,但没有注释
- Dunnings 2018 年研究的火灾图像数据集 - PNG 静态图像集
- Samarth 2019 研究的火超像素图像数据集 - PNG 静态图像集
- 野火烟雾数据集 - 737 张带注释(边框)图像
- jackfrost1411 的数据集 -> 将数百张图像分类为火/中性以进行分类任务。无边界框注释
- Kaggle 上的 fire-and-smoke-dataset -> 7000 多张图像,其中包括 691 张仅火焰图像、3721 张仅烟雾图像和 4207 张火灾{火焰和烟雾}图像
- 国内火灾和烟雾数据集 -> 大约。 5000 张独特图像、2 类(火和烟)、边界框注释、COCO、PASCAL VOC 和 YOLO 格式
- Kaggle 火与枪数据集
- Wildfire-Detection -> PerceptiLabs 提供的数据集,描绘正常场景和包含火灾的场景的 250x250 像素图像。与文章。这是来自kaggle的这个数据集
- DFireDataset -> 用于火灾和烟雾检测的图像数据集
消防安全参考
- 查找涵盖家庭中不同类型火灾、常见场景和干预措施的参考资料
- 火灾探测器的安全/准确度标准,包括 ROC 特性
家里发生火灾
- 常见原因包括闷烧香烟、蜡烛、电力故障、炸锅起火
- 有很多因素会影响火灾的性质,主要是燃料和氧气,还有火灾的位置、房间的中间/靠墙、房间的热容量、墙壁、环境温度、湿度、污染物。材料(灰尘、油基产品、润肤剂等)
- 为了扑灭火灾,可以考虑使用多种阻燃剂 - 水(不要使用电气或芯片盘)、泡沫、二氧化碳、干粉
- 发生电气火灾时,首先应隔离电源
- 减少通风(例如关门)将限制火灾
- 烟雾本身就是火灾性质的有力指标
- 阅读 https://en.m.wikipedia.org/wiki/Fire_triangle 和 https://en.m.wikipedia.org/wiki/Combustion
边缘部署
我们部署到边缘设备(RPi、jetson nano、android 或 ios)的最终目标将影响有关架构和其他权衡的决策。
- 以 30 FPS 将 YOLOv5 部署到 Jetson Xavier NX - 以 30 FPS 进行推理
- 如何在自定义数据集上训练 YOLOv5
- 在自定义数据上训练 YOLOv4-tiny - 闪电般快速的物体检测
- 如何训练自定义 TensorFlow Lite 对象检测模型 - colab 笔记本、MobileNetSSDv2、部署到 RPi
- 如何使用 YOLOv4 Tiny 和 TensorFlow Lite 训练自定义移动对象检测模型 - 训练 YOLOv4 tiny Darknet 并转换为 tflite,在 Android 上进行演示,比直接训练 tflite 更多步骤
- AG 人工智能:农业生产机器学习 - 从培训到部署的完整工作流程
- Pytorch 现在正式支持 RPi https://pytorch.org/blog/prototype-features-now-available-apis-for-hardware-accelerated-mobile-and-arm64-builds/
- Hermes 是一种野火检测系统,利用计算机视觉并使用 NVIDIA Deepstream 进行加速
云端部署
我们想要一个也可以部署到云端的解决方案,与边缘部署相比,只需进行最少的更改。有几个选项:
- 作为 lambda 函数部署 - 根据我的经验,响应时间很长,长达 45 秒
- 使用自定义代码在虚拟机上部署以处理请求排队
- 在 sagemaker 上使用 torchserve,在 EC2 实例上运行。有据可查,但 AWS 特定。
- 使用云提供商之一,例如 AWS Rekognition 将识别火灾
图像预处理和增强
除了基本裁剪之外,Roboflow 还允许每个数据集最多进行 3 种类型的增强。如果我们想尝试更多增强功能,可以查看 https://imgaug.readthedocs.io/en/latest/
- 为什么图像预处理和增强很重要
- 模糊作为图像增强技术的重要性
- 何时使用对比度作为预处理步骤
- YOLOv4 中的数据增强
- 为什么要为机器学习的图像添加噪声
- 为什么以及如何实施随机作物数据增强
- 何时使用灰度作为预处理步骤
机器学习指标
Precision是预测的准确性,计算公式为precision = TP/(TP+FP)或“预测正确的百分比是多少?”-
Recall是真阳性率(TPR),计算公式为recall = TP/(TP+FN)或“模型捕获的真阳性百分比是多少?” -
F1 score (也称为 F 分数或 F 度量)是精度和召回率的调和平均值,计算公式为F1 = 2*(precision * recall)/(precision + recall) 。它传达了精确度和召回率之间的平衡。参考号 - 误报率(FPR)(计算公式为
FPR = FP/(FP+TN)通常在 ROC 曲线中针对召回率/TPR 进行绘制,该曲线显示了 TPR/FPR 权衡如何随分类阈值变化。降低分类阈值会返回更多真阳性,但也会返回更多假阳性 - mAP、IoU、精度和召回率在这里和这里都有很好的解释
- IceVision 返回 COCOMetric,特别是
AP at IoU=.50:.05:.95 (primary challenge metric) ,从这里开始,通常称为“平均精度”(mAP) -
[email protected] :考虑到所有标签的每个标签的平均精度或正确性。 @0.5设置预测边界框与原始注释重叠的阈值,即“50%重叠”
评论
- Firenet 是一个非常常见的模型名称,请勿使用
讨论
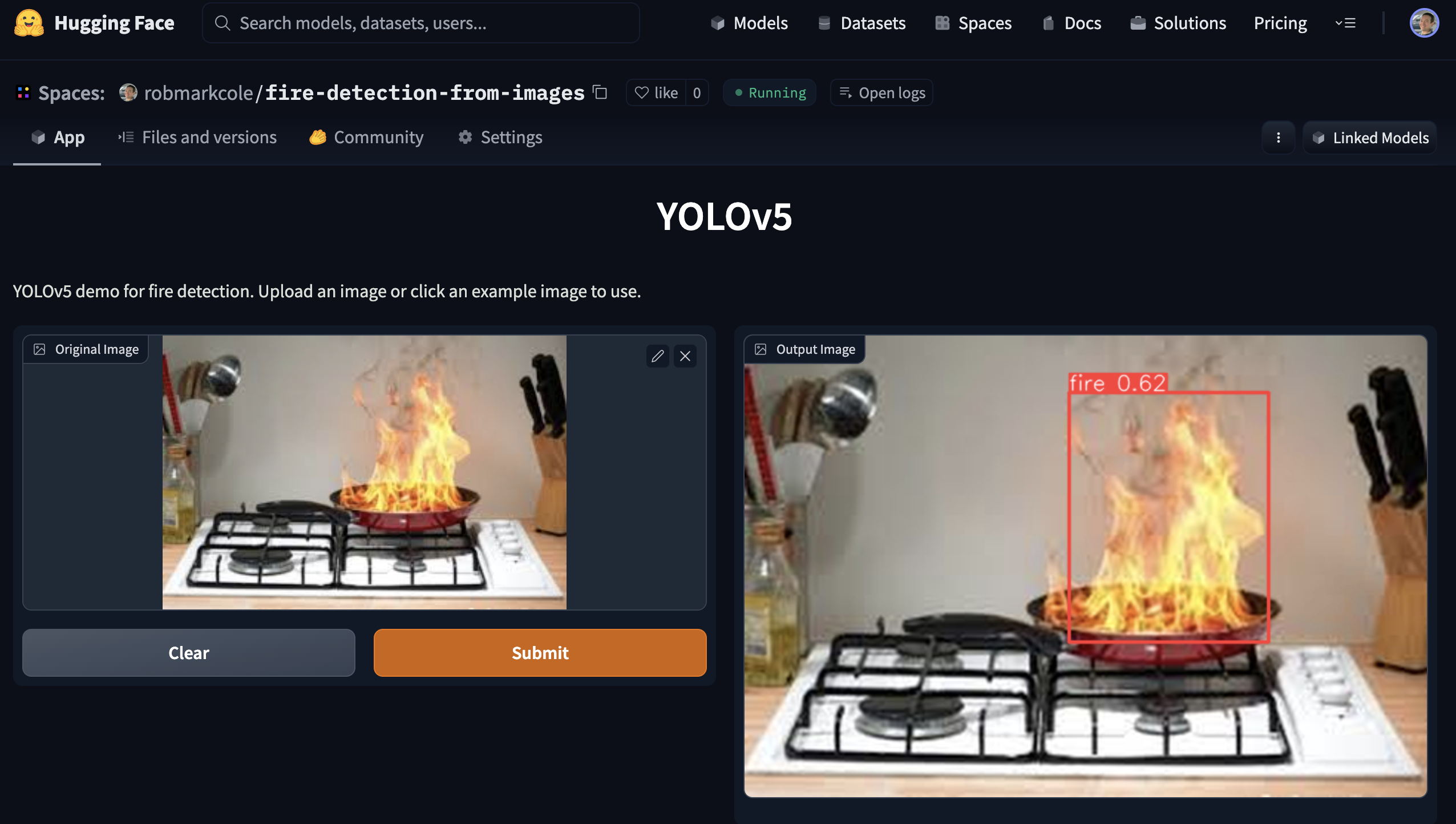
演示
可以通过运行使用 Gradio 创建的演示应用程序来使用性能最佳的模型。查看demo目录