test arranger
v1.6.3
TDD 中有 3 个阶段:安排、行动和断言(BDD 中为given、when、then)。断言阶段有很好的工具支持,您可能熟悉 AssertJ、FEST-Assert 或 Hamcrest。它与排列阶段相反。虽然安排测试数据通常具有挑战性,并且测试的重要部分通常专门用于它,但很难指出支持它的工具。
测试安排器试图通过安排测试所需的类实例来填补这一空白。这些实例填充了伪随机值,简化了测试数据创建的过程。测试人员仅声明所需对象的类型并获取全新的实例。当给定字段的伪随机值不够好时,只需手动设置该字段:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' Arranger 类有几个静态方法用于生成简单类型的伪随机值。它们每个都有一个包装函数,以使 Kotlin 的调用更简单。下面列出了一些可能的调用:
| 爪哇 | 科特林 | 结果 |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | 所有字段都填充了值的 Product 实例 |
Arranger.some(Product.class, "brand") | some<Product>("brand") | 对品牌领域没有价值的产品实例 |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | 类别的实例,集合类型的字段大小减少到 1,对象树的深度限制为 3 |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | Product 实例大小为 7 的流 |
Arranger.someEmail() | someEmail() | 包含电子邮件地址的字符串 |
Arranger.someLong() | someLong() | long 类型的伪随机数 |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | listOfCategories 中的条目 |
Arranger.someText() | someText() | 从马尔可夫链生成的字符串;默认情况下,它是一个非常简单的链,但可以通过将其他“enMarkovChain”文件放在具有替代定义的测试类路径上来重新配置,您可以在这里找到一个在英语语料库上训练的链;请参阅项目“enMarkovChain”文件中包含的文件格式 |
| - | some<Product> {name = "not so random"} | Product 的实例,其所有字段都填充了随机值( name除外,名称设置为“不太随机”),此语法可用于根据需要设置对象的任意多个字段,但每个对象都必须是可变的 |
完全随机的数据可能并不适合每个测试用例。通常至少有一个字段对于测试目标至关重要并且需要一定的值。当排列的类是可变的,或者它是 Kotlin 数据类,或者有一种方法可以创建更改的副本(例如 Lombok 的 @Builder(toBuilder = true))时,则只需使用可用的类。幸运的是,即使它不可调整,您也可以使用测试安排器。 some()和someObjects()方法有专用版本,它们接受Map<String,Supplier>类型的参数。该映射中的键代表字段名称,而相应的供应商提供测试安排器将为您在这些字段上设置的值,例如:
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));默认情况下,根据字段类型生成随机值。随机值并不总是与类不变量很好地对应。当一个实体总是需要根据有关字段值的一些规则进行排列时,您可以提供自定义排列程序:
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
}为了控制实例化Product的过程,我们需要重写instance()方法。在方法内部,我们可以根据需要创建Product实例。具体来说,我们可以生成一些随机值。为了方便起见,我们在CustomArranger类中有一个enhancedRandom字段。在给定的示例中,我们生成一个Product实例,其中所有字段都具有伪随机值,但随后我们将价格更改为我们域中可接受的价格。这不是负数并且小于 10k 数字。
ProductArranger会自动(使用反射)由 Arranger 拾取,并在请求新的Product实例时使用。它不仅考虑像Arranger.some(Product.class)这样的直接调用,而且还考虑间接调用。假设有Shop类,其字段products类型为List<Product> 。当调用Arranger.some(Shop.class)时,排列器将使用ProductArranger创建存储在Shop.products中的所有产品。
测试安排器的行为可以使用属性进行配置。如果您创建arranger.properties文件并将其保存在类路径的根目录中(通常是src/test/resources/目录),它将被拾取并应用以下属性:
arranger.root使用反射来拾取自定义编曲器。所有扩展CustomArranger类都被视为自定义编曲器。反射集中在某个包上,默认情况下是com.ocado 。这不一定对您方便。但是,使用arranger.root=your_package可以将其更改为your_package 。尝试让包尽可能具体,因为有一些通用的东西(例如,只是com ,它是许多库中的根包)将导致扫描数百个类,这将花费大量时间。arranger.randomseed默认情况下,始终使用相同的种子来初始化底层伪随机值生成器。因此,后续执行将生成相同的值。为了实现运行中的随机性,即始终以其他随机值开始,需要设置arranger.randomseed=true 。arranger.cache.enable排列随机实例的过程需要一些时间。如果您创建大量实例并且不需要它们完全随机,则启用缓存可能是一种可行的方法。启用后,缓存会存储对每个随机实例的引用,并且在某个时刻测试安排程序会停止创建新实例,而是重用缓存的实例。默认情况下,缓存是禁用的。arranger.overridedefaults Test-arranger 遵循默认字段初始化,即当存在用空字符串初始化的字段时,test-arranger 返回的实例在该字段中具有空字符串。并不总是您在测试中需要的,特别是当项目中有一个约定用空值初始化字段时。幸运的是,您可以强制测试安排程序用随机值覆盖默认值。将arranger.overridedefaults设置为 true 以覆盖默认初始化。arranger.maxRandomizationDepth一些测试数据结构可以生成任意长度的相互引用的对象链。然而,为了在测试用例中有效地使用它们,控制这些链的长度至关重要。默认情况下,Test-arranger 在嵌套深度的第 4 层停止创建新对象。如果此默认设置不适合您的项目测试用例,可以使用此参数进行调整。当您有一条可用作测试数据的 Java 记录,但需要更改其一两个字段时, Data类及其复制方法提供了一种解决方案。当处理没有明显方法直接更改其字段的不可变记录时,这特别有用。
Data.copy方法允许您创建记录的浅表副本,同时有选择地修改所需字段。通过提供字段覆盖的映射,您可以指定需要更改的字段及其新值。复制方法负责使用更新的字段值创建记录的新实例。
这种方法使您无需手动创建新记录对象并单独设置字段,从而提供了一种便捷的方法来生成与现有记录略有不同的测试数据。
总体而言,Data 类及其复制方法通过启用更改选定字段的记录的浅表副本来解决这种情况,从而在使用不可变记录类型时提供灵活性和便利性:
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));当对一个软件项目进行测试时,人们很少会有这样的印象:它不能做得更好。在安排测试数据的范围内,我们正在尝试使用 Test Arranger 改进两个方面。
当了解创建者的意图时,测试就更容易理解,即为什么编写测试以及应该检测什么类型的问题。不幸的是,在安排(给定)部分中看到测试具有如下所示的语句并不奇怪:
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();在查看此类代码时,很难说哪些值与测试相关,哪些值只是为了满足某些非空要求而提供的。如果测试是关于品牌的,为什么不这样写:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );现在很明显品牌的重要性。让我们尝试更进一步。整个测试可能如下所示:
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) 我们现在正在测试该报告是否是为“Some Brand”品牌创建的。但这是目标吗?期望为指定产品所分配的同一品牌生成报告更有意义。所以我们要测试的是:
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) 如果品牌字段是可变的,并且我们担心sut可能会修改它,我们可以在进入行动阶段之前将其值存储在变量中,然后将其用于断言。测试时间会更长,但意图仍然明确。
值得注意的是,我们刚刚所做的是生成值的应用,并且在某种程度上是 Gerard Meszaros 的xUnit 测试模式:重构测试代码中描述的创建方法模式。
您是否曾经更改过生产代码中的一小部分并最终在数十次测试中出现错误?其中一些报告断言失败,有些甚至可能拒绝编译。这是一种猎枪手术代码的味道,只是向你无辜的测试射击。好吧,也许并不那么无辜,因为它们可以进行不同的设计,以限制微小变化造成的附带损害。我们用一个例子来分析一下。假设我们的域中有以下类:
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
...并且它被用在很多地方。特别是在没有 Test Arranger 的测试中,使用如下语句: new TimeRange(LocalDateTime.now(), 3600_000L);如果由于某些重要原因我们被迫将课程更改为:
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
...在不破坏所有相关测试的情况下提出一系列将旧版本转换为新版本的重构是相当具有挑战性的。更有可能的情况是测试被一一调整到类的新API。这意味着很多并不令人兴奋的工作,涉及许多关于所需持续时间值的问题(我是否应该小心地将其转换为 LocalDateTime 类型的end ,或者它只是一个方便的随机值)。有了 Test Arranger,生活会变得更加轻松。当在所有需要不为 null TimeRange地方时,我们都有Arranger.some(TimeRange.class) ,它对于新版本的TimeRange和旧版本的一样好。这给我们留下了少数不需要随机TimeRange情况,但由于我们已经使用 Test Arranger 来揭示测试意图,因此在每种情况下我们都确切地知道TimeRange应该使用什么值。
但是,这并不是我们为改进测试所能做的一切。据推测,我们可以识别TimeRange实例的某些类别,例如过去的范围、未来的范围和当前活动的范围。 TimeRangeArranger是安排以下内容的好地方:
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
}这样的创建方法不应该预先创建,而应该与现有的测试用例相对应。尽管如此, TimeRangeArranger有可能涵盖为测试创建TimeRange实例的所有情况。因此,我们用一个命名良好的方法来代替带有几个神秘参数的构造函数调用,该方法解释了所创建对象的域含义并帮助理解测试意图。
在讨论测试安排器解决的挑战时,我们确定了两个级别的测试数据创建者。为了使图片更加完整,我们至少还需要提及一个,那就是灯具。为了便于讨论,我们可以假设 Fixture 是一个旨在创建复杂的测试数据结构的类。自定义编排器始终专注于一个类,但有时您可以在测试用例中观察到两个或多个类的重复出现。这可能是用户和他或她的银行帐户。他们每个人可能都有一个 CustomArranger,但为什么要忽略他们经常聚集在一起的事实呢?这是我们应该开始考虑夹具的时候。它将负责创建用户和银行帐户(可能使用专用的自定义安排程序)并将它们链接在一起。详细描述了这些 Fixtures,包括 Gerard Meszaros 的xUnit 测试模式:重构测试代码中的几个实现变体。
因此,我们在测试类中拥有三种类型的构建块。它们中的每一个都可以被认为是生产代码中的概念(领域驱动设计构建块)的对应部分: 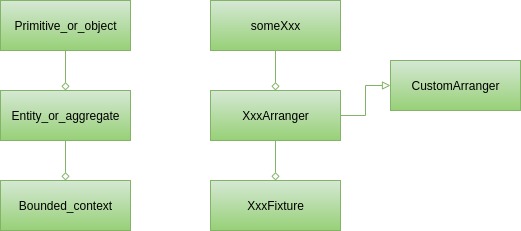
从表面上看,有原始的和简单的对象。即使在最简单的单元测试中也会出现这种情况。您可以使用Arranger类中的someXxx方法来排列此类测试数据。
因此,您可能有需要仅对User实例或User和User类中包含的其他类(如地址列表)进行测试的服务。为了涵盖这种情况,通常需要一个自定义编排器,即UserArranger 。它将创建尊重所有约束和类不变量的User实例。此外,它会选取AddressArranger (如果存在),用有效数据填充地址列表。当多个测试用例需要某种类型的用户时,例如地址列表为空的无家可归的用户,可以在 UserArranger 中创建一个附加方法。因此,每当需要为测试创建User实例时,只需查看UserArranger并选择适当的工厂方法或仅调用Arranger.some(User.class)就足够了。
最具挑战性的情况是依赖于大型数据结构的测试。在电子商务中,这可能是包含许多产品的商店,也可能是具有购物历史记录的用户帐户。为此类测试用例安排数据通常并不简单,重复这样的事情并不明智。最好将其存储在名称良好的方法下的专用类中,例如shopWithNineProductsAndFourCustomers ,并在每个测试中重用。我们强烈建议对此类类使用命名约定,为了使它们易于查找,我们的建议是使用Fixture postfix。最终,我们可能会得到这样的结果:
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}最新的测试安排器版本是使用 Java 17 编译的,应该在 Java 17+ 运行时中使用。然而,还有一个用于向后兼容的 Java 8 分支,包含在 1.4.x 版本中。


