self instruct
1.0.0
该存储库包含 Self-Instruct 论文的代码和数据,这是一种将预训练语言模型与指令对齐的方法。
Self-Instruct 是一个帮助语言模型提高遵循自然语言指令的能力的框架。它通过使用模型自己的一代来创建大量教学数据来实现这一点。通过自指令,可以提高语言模型的指令跟踪能力,而无需依赖大量的手动注释。
近年来,人们对构建能够遵循自然语言指令来执行各种任务的模型越来越感兴趣。这些模型被称为“指令调整”语言模型,已经证明了泛化到新任务的能力。然而,它们的性能在很大程度上取决于用于训练它们的人工编写的指令数据的质量和数量,而这些数据的多样性和创造力可能受到限制。为了克服这些限制,开发替代方法来监督指令调整模型并提高其指令跟踪能力非常重要。
自指令过程是一种迭代引导算法,它从手动编写的指令种子集开始,并使用它们提示语言模型生成新指令和相应的输入输出实例。然后对这些生成进行过滤,以删除低质量或相似的生成,并将生成的数据添加回任务池。这个过程可以重复多次,从而产生大量的教学数据,可用于微调语言模型以更有效地遵循指令。
以下是自我指导的概述:
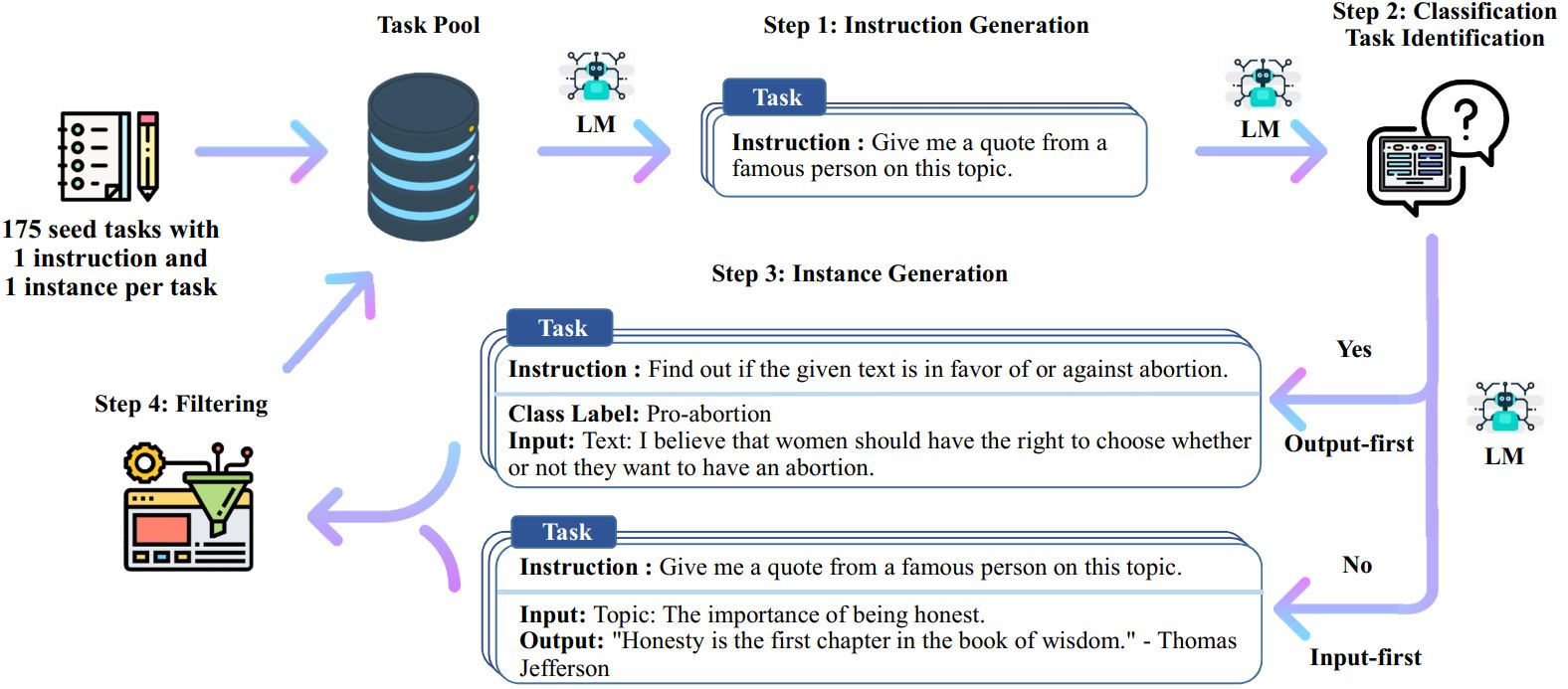
*这项工作仍在进行中。随着进展,我们可能会更新代码和数据。请谨慎对待版本控制。
我们发布了一个包含 52k 条指令的数据集,与 82K 实例输入和输出配对。这些指令数据可以用来对语言模型进行指令调优,使语言模型更好地遵循指令。整个模型生成的数据可以在data/gpt3-generations/batch_221203/all_instances_82K.jsonl中访问。以干净的 GPT3-finetuning 格式(提示 + 完成)重新格式化的数据(+ 175 个种子任务)放入data/finetuning/self_instruct_221203中。您可以使用./scripts/finetune_gpt3.sh中的脚本对此数据微调 GPT3。
注意:该数据由语言模型(GPT3)生成,不可避免地包含一些错误或偏差。我们分析了论文中 200 个随机指令的数据质量,发现 46% 的数据点可能存在问题。我们鼓励用户谨慎使用这些数据,并提出新的方法来过滤或改进缺陷。
我们还发布了一组新的 252 个专家编写的任务及其由面向用户的应用程序(而不是经过充分研究的 NLP 任务)驱动的指令。该数据用于自学论文的人类评估部分。有关更多详细信息,请参阅人工评估自述文件。
为了使用您自己的种子任务或其他模型生成自指导数据,我们在此处开源了整个管道的脚本。我们当前的代码仅在可通过 OpenAI API 访问的 GPT3 模型上进行了测试。
以下是生成数据的脚本:
# 1. 从种子任务生成指令。/scripts/generate_instructions.sh# 2. 识别该指令是否代表分类任务。/scripts/is_clf_or_not.sh# 3. 为每个指令生成实例。/scripts/generate_instances。 sh# 4. 过滤、处理和重新格式化./scripts/prepare_for_finetuning.sh
如果您使用自学框架或数据,请随时引用我们。
@misc{selfinstruct, title={Self-Instruct: 将语言模型与自生成指令对齐},作者={Wang、Yizhong 和 Kordi、Yeganeh 和 Mishra、Swaroop 和 Liu、Alisa 和 Smith、Noah A. 和 Khashabi、Daniel 和Hajishirzi, Hannaneh}, 期刊={arXiv 预印本 arXiv:2212.10560},年={2022}} 

