该代码基于现有的 Image to BEV 深度学习模型而构建,该模型基于论文《将图像翻译成地图》。该代码是使用 python 3.7 编写的。并接受了 nuScenes 数据集的训练。请参阅存储库的自述文件以获取要安装的依赖项和数据集。
第一步是创建一个名为“translation-images-into-maps-main”的文件夹并将所有文件下载到其中。然后,由于文件较大,我们训练的最新检查点和用于验证的迷你 nuScenes 数据集可以从此 Google Drive 下载。这些文件夹应直接添加到“translated-images-into-maps-main”目录中。
以下是此存储库所需的库的列表:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
要使用此存储库的功能,可能需要更改以下命令行参数:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
至于训练模型,可以修改这些命令行参数:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
NuScenes Mini 和 Full 数据集可以在以下位置找到:
NuScene 迷你:
NuScenes 完整美国版:
由于 NuScene 迷你数据集和完整数据集不具有相同的图像输入格式(lmdb 或 png),因此需要对代码进行一些修改才能使用其中一种:
mini参数更改为 false 以使用迷你数据集以及train.py 、 validation.py和inference.py文件中的 args 路径和分割。 data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py函数的第 151-153 或 146-149 行: # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')预训练的检查点可以在这里找到:
检查点需要保存在该存储库根目录的/pretrained_models/27_04_23_11_08中。如果您想从另一个目录加载它们,请更改以下参数:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"要训练 scitas,您需要从根目录启动以下脚本:
sbatch job.script.sh
在 cpu 上进行本地训练:
python3 train.py
确保使用命令行参数调整脚本。
要验证 scitas 上的模型性能:
sbatch job.validate.sh
在 cpu 上进行本地训练:
python3 validate.py
确保使用命令行参数调整脚本。
要推断有关 scitas 的视频:
sbatch job.evaluate.sh
在 cpu 上进行本地训练:
python3 inference.py
确保使用命令行参数调整脚本,尤其是:
--batch-size // 1 for the test videos
--video-name
--video-root
该项目是在自动驾驶汽车深度学习课程 CIVIL-459 的背景下完成的,该课程由 EPFL 的 Alexandre Alahi 教授教授。指导老师是博士生刘跃江。该课程项目的主要目标是开发可在特斯拉自动驾驶系统上使用的深度学习模型。对于我们组来说,我们一直在研究从单目相机图像到鸟瞰图的转变。这可以通过使用语义分割对汽车、人行道、行人和地平线等元素进行分类来完成。
在我们对单目图像到 BEV 深度学习模型的研究过程中,我们注意到在分割过程中行人的信息丢失,导致分类效果不佳。如下图所示,在评估时,我们选择的模型在 nuScenes 数据集上的 14 类对象上达到了 25.7% IoU(并集交集)的平均值。可驾驶车辆的预测准确度良好 (74.5%),但自行车、障碍物和拖车的预测准确度相当差。然而,对行人的预测准确度(9.5%)太低了。如果有人在没有到达十字路口的情况下过马路,如此低的准确度可能会导致事故。

有关我们研究的更多信息可以在 Drive 上找到。
由于对行人的检测不佳似乎是当前训练模型最直接的问题,因此我们的目标是通过研究更适合的损失函数并在 nuScenes 数据集上训练新模型来提高准确性。
我们建立的模型是使用
另一个问题是
这
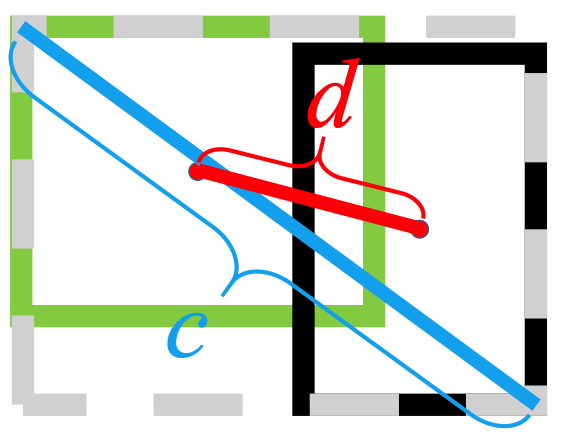
它使用 L2 范数来最小化预测框和目标框之间的距离,并且收敛速度比

水平拉伸

垂直拉伸
此外,DIoU 损失引入了一个正则化项,可以促进平滑收敛。
如下图所示,
研究阶段结束后,我们实施了/src/utils.py文件中的bbox_overlaps_diou函数中的损失,通过使用
然后使用该函数来计算多尺度compute_multiscale_iou函数中。对于每个班级, iou输入参数的函数中)是根据批量大小计算的。该函数的输出是一个字典iou_dict其中包含多尺度
然后我们在train.py中使用这些值,其中val-interval epoch 运行一次的评估中使用。这些值也用在validation.py中,用于显示损失和
我们从提供的检查点checkpoint-008.pth.gz开始在 NuScenes 数据集上训练模型,一次使用
另一个贡献是新的可视化格式,可以更好地区分类别与所有相应的标签和 IoU 值。这是在visualization.py文件中实现的。
最后,我们致力于实现一种模式,该模式将.mp4视频作为输入并将它们分解为单独的图像帧。然后模型将对其进行评估,我们可以在inference.py文件中可视化分割结果。
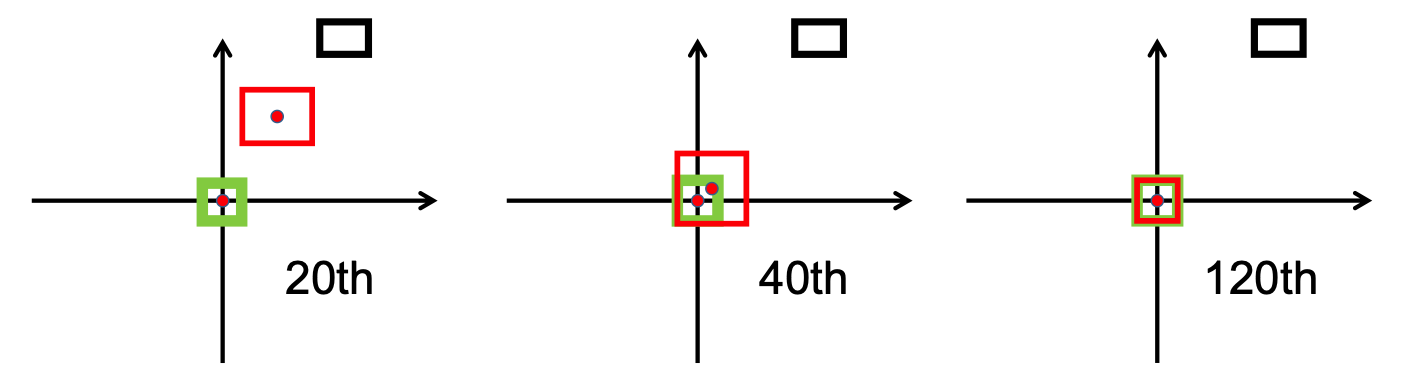
为了初步了解该模型的训练策略,我们首先决定在 NuScenes 迷你数据集上对其进行训练。从checkpoint-008.pth.gz开始,我们能够训练两个使用 IoU 指标不同的模型(一个是 IoU,另一个是 DIoU)。下表列出了经过 10 个 epoch 训练后在 NuScenes 小批量上获得的结果。

查看这些结果后,我们发现我们的假设所依据的行人类别根本没有提供结论性的结果。因此,我们得出结论,迷你数据集不足以满足我们的需求,并决定将我们的训练转移到 Scitas 的完整数据集。
在从checkpoint-008.pth.gz训练我们的新模型(使用 DIoU 或 IoU)8 个新时期后,我们观察到了有希望的结果。为了比较这些新训练的模型的性能,我们对迷你数据集执行了验证步骤。下面提供了该数据集图像结果的可视化。
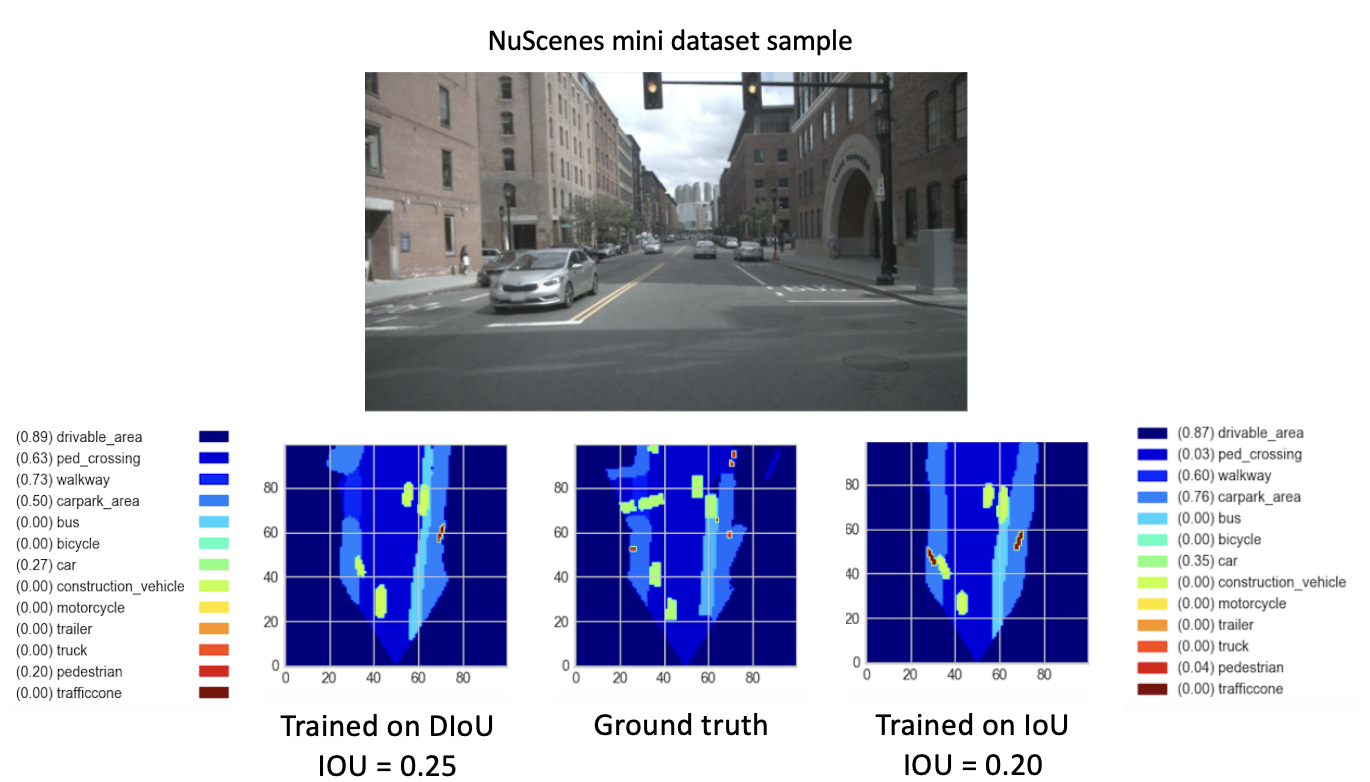
在这里,

这些结果最终显示出更好的性能
现在我们有了经过训练的模型,我们可以用它来使用任何输入图像或视频来预测 BEV。虽然我们的目标是在课程的最终演示中实施我们的方法,但不幸的是,推断的鸟瞰图性能不够。下图显示了所提供的测试视频之一的推理结果(参见测试视频)。

我们认为推理性能的缺乏是由于以下参数造成的:
虽然这段经文来自
一种选择是实施
这
此外,根据本文 [2] 所做的研究,CIoU 的回归误差比其他模型退化得更快,并且将收敛于
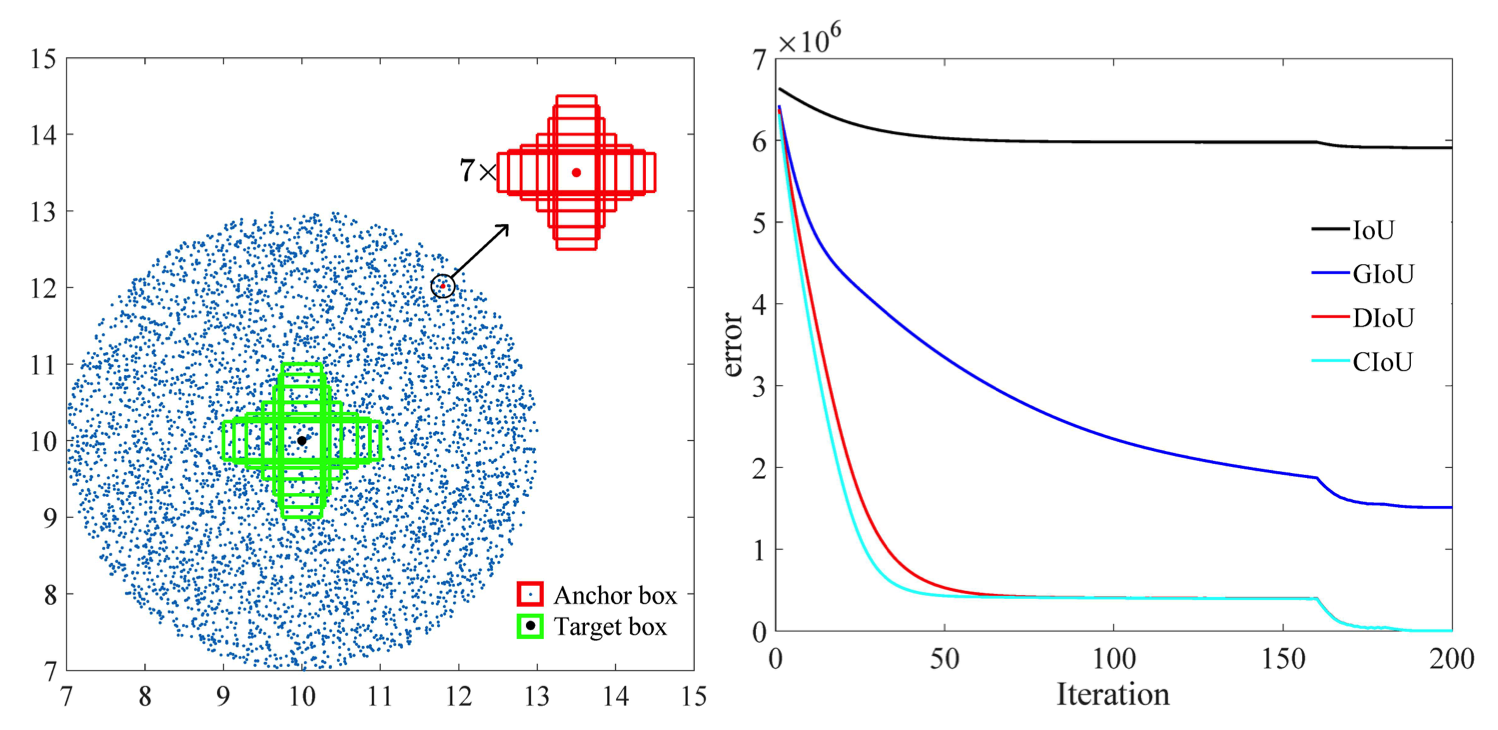
另一种选择是在拥挤环境中丰富的数据集上进行训练,以更好地表示行人和自行车。
最后,为了真正验证我们的假设,可以在完整的 NuScenes 数据集上进行验证运行,并比较两个模型的行人 IoU。
[1]郑朝晖,王平,刘伟,李金泽,叶荣光,任东伟(2020)。距离 IoU 损失:更快更好地学习边界框回归 https://arxiv.org/pdf/1911.08287.pdf
[2] 郑朝晖,王平,任东伟,刘伟,叶荣光,胡清华,左王猛(2021)。增强对象检测和实例分割的模型学习和推理中的几何因素 https://arxiv.org/pdf/2005.03572.pdf


