tiny cuda nn
Version 1.6
这是一个小型的、独立的框架,用于训练和查询神经网络。最值得注意的是,它包含闪电般快速的“完全融合”多层感知器(技术论文)、多功能多分辨率哈希编码(技术论文),以及对各种其他输入编码、损失和优化器的支持。
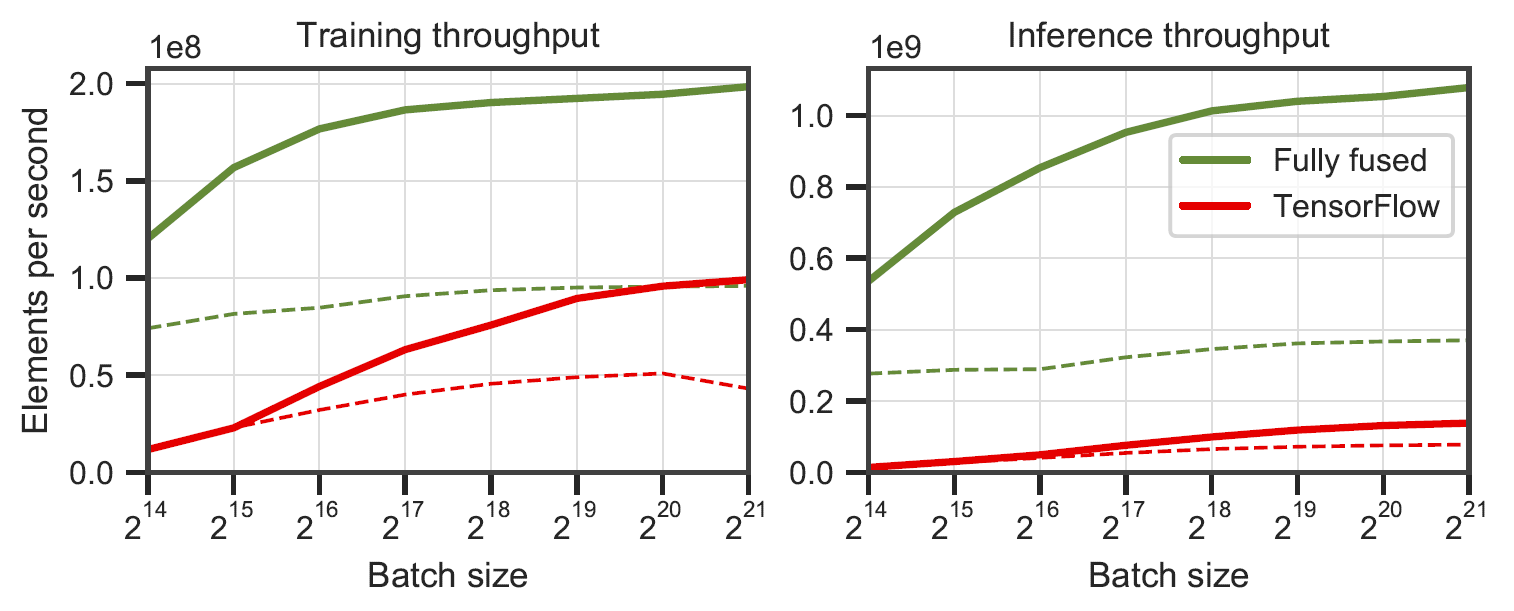 完全融合的网络与带有 XLA 的 TensorFlow v2.5.0。在 RTX 3090 上的 64 个(实线)和 128 个(虚线)神经元宽多层感知器上测量。由
完全融合的网络与带有 XLA 的 TensorFlow v2.5.0。在 RTX 3090 上的 64 个(实线)和 128 个(虚线)神经元宽多层感知器上测量。由benchmarks/bench_ours.cu和benchmarks/bench_tensorflow.py使用data/config_oneblob.json生成。
微型 CUDA 神经网络有一个简单的 C++/CUDA API:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);我们提供了一个示例应用程序,其中学习了图像函数(x,y) -> (R,G,B) 。它可以通过运行
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.json每几个训练步骤生成一个图像。在 RTX 4090 的默认配置下,每 1000 步应该花费 1 秒多一点的时间。
| 10步 | 100步 | 1000 步 | 参考图片 |
|---|---|---|---|
 |  |  |  |
n_neurons参数或使用CutlassMLP (兼容性更好但速度较慢)。如果您使用的是 Linux,请安装以下软件包
sudo apt-get install build-essential git我们还建议将 CUDA 安装在/usr/local/中,并将 CUDA 安装添加到您的 PATH 中。例如,如果您有 CUDA 11.4,请将以下内容添加到~/.bashrc
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " 首先使用以下命令克隆此存储库及其所有子模块:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nn然后,使用 CMake 构建项目:(在 Windows 上,这必须在开发人员命令提示符中)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j如果编译莫名其妙地失败或花费超过一个小时,则可能会耗尽内存。在这种情况下,请尝试在不带-j的情况下运行上述命令。
tiny-cuda-nn附带 PyTorch 扩展,允许在 Python 上下文中使用快速 MLP 和输入编码。这些绑定比完整的 Python 实现要快得多;特别是对于多分辨率哈希编码。
如果批量大小很小,Python/PyTorch 的开销仍然会很大。例如,批量大小为 64k 时,通过 PyTorch 捆绑的
mlp_learning_an_image示例比原生 CUDA慢约 2 倍。当批量大小为 256k 或更高(默认)时,性能更加接近。
首先使用最新的、支持 CUDA 的 PyTorch 版本设置 Python 3.X 环境。然后,调用
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torch或者,如果您想从tiny-cuda-nn的本地克隆进行安装,请调用
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py install成功后,您可以使用tiny-cuda-nn模型,如下例所示:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network )有关示例,请参阅samples/mlp_learning_an_image_pytorch.py 。
以下是该框架的组成部分的摘要。 JSON 文档列出了配置选项。
| 网络 | ||
|---|---|---|
| 完全融合MLP | src/fully_fused_mlp.cu | 快速实现小型多层感知器 (MLP)。 |
| 弯刀MLP | src/cutlass_mlp.cu | 基于 CUTLASS 的 GEMM 例程的 MLP。比完全融合慢,但处理更大的网络并且仍然相当快。 |
| 输入编码 | ||
|---|---|---|
| 合成的 | include/tiny-cuda-nn/encodings/composite.h | 允许组合多种编码。例如,可以用于组装神经辐射缓存编码 [Müller 等人。 2021]。 |
| 频率 | include/tiny-cuda-nn/encodings/frequency.h | NeRF 的 [Mildenhall 等人。 2020]位置编码同样适用于所有维度。 |
| 网格 | include/tiny-cuda-nn/encodings/grid.h | 基于可训练的多分辨率网格的编码。用于即时神经图形基元 [Müller 等人。 2022年]。网格可以由哈希表、密集存储或平铺存储支持。 |
| 身份 | include/tiny-cuda-nn/encodings/identity.h | 保持价值观不变。 |
| 一个斑点 | include/tiny-cuda-nn/encodings/oneblob.h | 来自神经重要性采样 [Müller 等人。 2019] 和神经控制变量 [Müller 等人。 2020]。 |
| 球谐函数 | include/tiny-cuda-nn/encodings/spherical_harmonics.h | 一种频率空间编码,比分量方式更适合方向向量。 |
| 三角波 | include/tiny-cuda-nn/encodings/triangle_wave.h | NeRF 编码的低成本替代方案。用于神经辐射缓存 [Müller 等人。 2021]。 |
| 损失 | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | 标准 L1 损耗。 |
| 相对L1 | include/tiny-cuda-nn/losses/l1.h | 通过网络预测标准化的相对 L1 损失。 |
| MAPE | include/tiny-cuda-nn/losses/mape.h | 平均绝对百分比误差 (MAPE)。与相对 L1 相同,但由目标标准化。 |
| SMAPE | include/tiny-cuda-nn/losses/smape.h | 对称平均绝对百分比误差 (SMAPE)。与相对 L1 相同,但通过预测和目标的平均值进行归一化。 |
| L2 | include/tiny-cuda-nn/losses/l2.h | 标准 L2 损耗。 |
| 相对L2 | include/tiny-cuda-nn/losses/relative_l2.h | 通过网络预测标准化相对 L2 损失 [Lehtinen 等人。 2018]。 |
| 相对 L2 亮度 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | 与上面相同,但通过网络预测的亮度进行归一化。仅当网络预测为 RGB 时适用。用于神经辐射缓存 [Müller 等人。 2021]。 |
| 交叉熵 | include/tiny-cuda-nn/losses/cross_entropy.h | 标准交叉熵损失。仅当网络预测为 PDF 时适用。 |
| 方差 | include/tiny-cuda-nn/losses/variance_is.h | 标准方差损失。仅当网络预测为 PDF 时适用。 |
| 优化器 | ||
|---|---|---|
| 亚当 | include/tiny-cuda-nn/optimizers/adam.h | Adam 的实现 [Kingma 和 Ba 2014],推广到 AdaBound [Luo 等人。 2019]。 |
| 诺沃格勒 | include/tiny-cuda-nn/optimizers/lookahead.h | Novograd 的实施 [Ginsburg 等人。 2019]。 |
| 新加坡元 | include/tiny-cuda-nn/optimizers/sgd.h | 标准随机梯度下降 (SGD)。 |
| 洗发水 | include/tiny-cuda-nn/optimizers/shampoo.h | 二阶洗发水优化器的实现 [Gupta 等人。 2018] 进行了本土优化以及 Anil 等人的优化。 [2020]。 |
| 平均的 | include/tiny-cuda-nn/optimizers/average.h | 包装另一个优化器并计算最后 N 次迭代中权重的线性平均值。平均值仅用于推理(不会反馈到训练中)。 |
| 批量 | include/tiny-cuda-nn/optimizers/batched.h | 包装另一个优化器,在平均梯度上每 N 步调用一次嵌套优化器。与增加批量大小具有相同的效果,但仅需要恒定的内存量。 |
| 合成的 | include/tiny-cuda-nn/optimizers/composite.h | 允许对不同参数使用多个优化器。 |
| EMA | include/tiny-cuda-nn/optimizers/average.h | 包装另一个优化器并计算权重的指数移动平均值。平均值仅用于推理(不会反馈到训练中)。 |
| 指数衰减 | include/tiny-cuda-nn/optimizers/exponential_decay.h | 包装另一个优化器并执行分段恒定指数学习率衰减。 |
| 前瞻 | include/tiny-cuda-nn/optimizers/lookahead.h | 包装另一个优化器,实现前瞻算法 [Zhang 等人。 2019]。 |
该框架根据 BSD 3-clause 许可证获得许可。详细信息请参阅LICENSE.txt 。
如果您在研究中使用它,我们将不胜感激
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}如需业务咨询,请访问我们的网站并提交表格:NVIDIA 研究许可
除其他外,该框架为以下出版物提供支持:
具有多分辨率哈希编码的即时神经图形基元
托马斯·穆勒、亚历克斯·埃文斯、克里斯托夫·席德、亚历山大·凯勒
ACM 图形交易 ( SIGGRAPH ),2022 年 7 月
网站/论文/代码/视频/BibTeX
从图像中提取三角形 3D 模型、材质和光照
雅各布·芒克伯格、乔恩·哈塞尔格伦、沉天长、高军、陈文正、亚历克斯·埃文斯、托马斯·穆勒、Sanja Fidler
CVPR(口头) ,2022 年 6 月
网站/论文/视频/BibTeX
用于路径追踪的实时神经辐射缓存
托马斯·穆勒、法布里斯·鲁塞尔、扬·诺瓦克、亚历山大·凯勒
ACM 图形交易 ( SIGGRAPH ),2021 年 8 月
论文 / GTC 演讲 / 视频 / 交互式结果查看器 / BibTeX
以及以下软件:
NerfAcc:通用 NeRF 加速工具箱
李瑞龙、Matthew Tancik、Angjoo Kanazawa
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio:神经辐射场开发框架
Matthew Tancik*、Ethan Weber*、Evonne Ng*、李瑞龙、Brent Yi、Terrance Wang、Alexander Kristoffersen、Jake Austin、Kamyar Salahi、Abhik Ahuja、David McAllister、Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
如果您的出版物或软件未列出,请随时提出拉取请求。
特别感谢 NRC 作者的有益讨论,感谢 Nikolaus Binder 提供该框架的部分基础设施,以及在使用 CUDA 内的 TensorCore 方面提供的帮助。


