

镇上的新机器人:SO-100

我们刚刚添加了一个关于如何构建更实惠的机器人的新教程,每只手臂的价格为 110 美元!
只需使用笔记本电脑向其展示一些动作即可教它新技能。
然后观看你自制的机器人自主行动?
点击链接查看 SO-100 的完整教程。
LeRobot:用于现实世界机器人的最先进的人工智能
? LeRobot 旨在为 PyTorch 中的现实世界机器人提供模型、数据集和工具。目标是降低进入机器人技术的门槛,以便每个人都可以做出贡献并从共享数据集和预训练模型中受益。
? LeRobot包含最先进的方法,这些方法已被证明可以转移到现实世界,重点是模仿学习和强化学习。
?乐机器人已经提供了一组预训练模型、包含人类收集演示的数据集以及无需组装机器人即可开始使用的模拟环境。在未来几周内,该计划将在最实惠、功能最强大的机器人上增加对现实世界机器人技术的越来越多的支持。
? LeRobot 在这个 Hugging Face 社区页面上托管预训练的模型和数据集:huggingface.co/lerobot
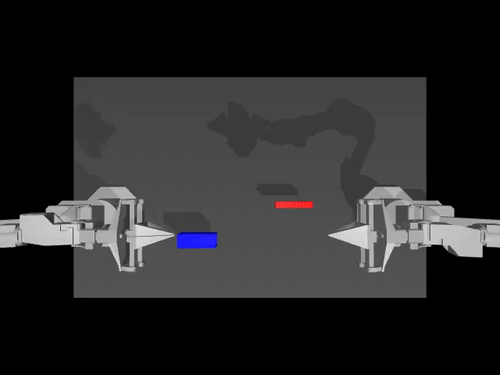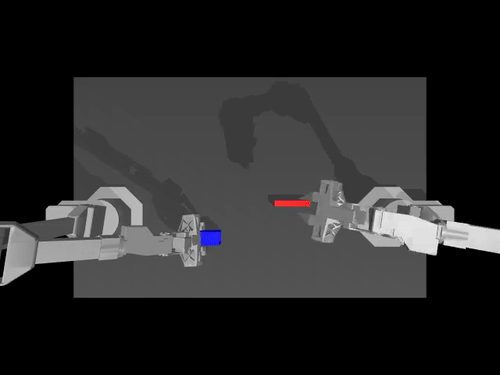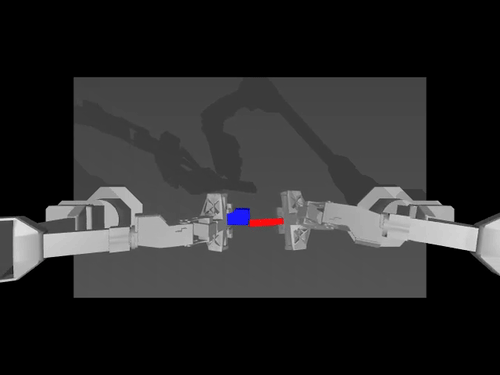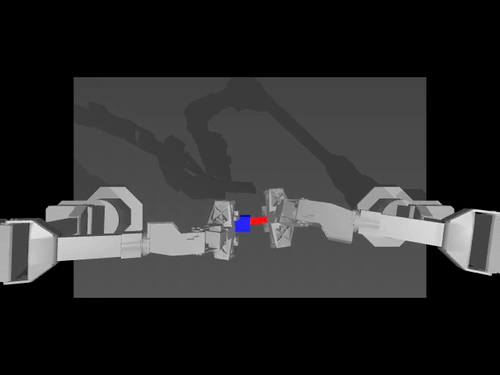 |  |  |
| ACT 关于 ALOHA env 的政策 | SimXArm 环境上的 TDMPC 策略 | PushT 环境上的扩散策略 |
下载我们的源代码:
git clone https://github.com/huggingface/lerobot.git
cd lerobot使用 Python 3.10 创建虚拟环境并激活它,例如使用miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobot安装 ?乐机器人:
pip install -e .注意:根据您的平台,如果在此步骤中遇到任何构建错误,您可能需要安装
cmake和build-essential来构建我们的一些依赖项。在 Linux 上:sudo apt-get install cmake build-essential
对于模拟, ?乐机器人配有健身房环境,可以作为额外安装:
例如,要安装? LeRobot 与 Aloha 和 Pusht,使用:
pip install -e " .[aloha, pusht] "要使用权重和偏差进行实验跟踪,请使用以下身份登录
wandb login(注意:您还需要在配置中启用 WandB。请参见下文。)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
查看示例 1,它说明了如何使用我们的数据集类自动从 Hugging Face 中心下载数据。
您还可以通过从命令行执行我们的脚本来本地可视化集线器上数据集的剧集:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0或来自具有根DATA_DIR环境变量的本地文件夹中的数据集(在以下情况下,将在./my_local_data_dir/lerobot/pusht中搜索数据集)
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0它将打开rerun.io并显示相机流、机器人状态和动作,如下所示:
我们的脚本还可以可视化存储在远程服务器上的数据集。有关更多说明,请参阅python lerobot/scripts/visualize_dataset.py --help 。
LeRobotDataset格式LeRobotDataset格式的数据集使用起来非常简单。它可以从 Hugging Face hub 上的存储库或本地文件夹中加载,例如dataset = LeRobotDataset("lerobot/aloha_static_coffee")并且可以像任何 Hugging Face 和 PyTorch 数据集一样进行索引。例如, dataset[0]将从数据集中检索单个时间帧,其中包含观察结果和一个动作,作为准备输入模型的 PyTorch 张量。
LeRobotDataset的特殊性在于,我们不是通过索引检索单个帧,而是可以通过将delta_timestamps设置为相对于索引帧的相对时间列表,根据它们与索引帧的时间关系来检索多个帧。例如,使用delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]}对于给定索引,可以检索 4 帧:3 个“前一”帧 1 秒、0.5 秒,以及索引帧之前 0.2 秒以及索引帧本身(对应于 0 条目)。有关delta_timestamps的更多详细信息,请参阅示例 1_load_lerobot_dataset.py 。
在幕后, LeRobotDataset格式使用多种方法来序列化数据,如果您打算更密切地使用此格式,这对于理解数据很有用。我们试图制作一种灵活而简单的数据集格式,涵盖强化学习和机器人技术、模拟和现实世界中存在的大多数类型的特征和特性,重点关注相机和机器人状态,但很容易扩展到其他类型的感官只要输入可以用张量表示即可。
以下是使用dataset = LeRobotDataset("lerobot/aloha_static_coffee")实例化的典型LeRobotDataset的重要细节和内部结构组织。确切的特征会随着数据集的不同而改变,但主要方面不会改变:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
LeRobotDataset的每个部分使用几种广泛使用的文件格式进行序列化,即:
safetensor张量序列化格式保存safetensor张量序列化格式保存的统计信息数据集可以从 HuggingFace 中心无缝上传/下载。要处理本地数据集,您可以将DATA_DIR环境变量设置为根数据集文件夹,如上面有关数据集可视化的部分所示。
查看示例 2,该示例演示了如何从 Hugging Face 中心下载预训练策略,并在其相应的环境中运行评估。
我们还提供了一个功能更强大的脚本,可以在同一部署过程中并行评估多个环境。以下是 lerobot/diffusion_pusht 上托管的预训练模型的示例:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10注意:训练您自己的策略后,您可以使用以下方法重新评估检查点:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model有关更多说明,请参阅python lerobot/scripts/eval.py --help 。
查看示例 3,它演示了如何使用我们的 Python 核心库来训练模型,示例 4 演示了如何从命令行使用我们的训练脚本。
一般来说,您可以使用我们的训练脚本轻松训练任何策略。下面是一个在 Aloha 模拟环境中根据人类收集的轨迹训练 ACT 策略以执行插入任务的示例:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human 实验目录是自动生成的,并将在您的终端中显示为黄色。它看起来像outputs/train/2024-05-05/20-21-12_aloha_act_default 。您可以通过将此参数添加到train.py python 命令来手动指定实验目录:
hydra.run.dir=your/new/experiment/dir在实验目录中会有一个名为checkpoints的文件夹,其结构如下:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step要从检查点恢复训练,您可以将这些添加到train.py python 命令中:
hydra.run.dir=your/original/experiment/dir resume=true它将加载预训练模型、优化器和调度器状态进行训练。有关更多信息,请参阅此处有关恢复训练的教程。
要使用 wandb 记录训练和评估曲线,请确保您已将wandb login作为一次性设置步骤运行。然后,在运行上面的训练命令时,通过添加以下内容在配置中启用 WandB:
wandb.enable=true运行的 wandb 日志的链接也会在终端中以黄色显示。以下是它们在浏览器中的外观示例。另请查看此处了解日志中一些常用指标的说明。

注意:为了提高效率,在训练期间,每个检查点都会在少量的剧集上进行评估。您可以使用eval.n_episodes=500来评估比默认值更多的剧集。或者,训练后,您可能想要重新评估更多剧集的最佳检查点或更改评估设置。有关更多说明,请参阅python lerobot/scripts/eval.py --help 。
我们组织了我们的配置文件(在lerobot/configs下找到),以便它们在各自的原始作品中重现给定模型变体的 SOTA 结果。只需运行:
python lerobot/scripts/train.py policy=diffusion env=pusht重现 PushT 任务上扩散策略的 SOTA 结果。
预训练策略以及复制详细信息可以在 https://huggingface.co/lerobot 的“模型”部分找到。
如果您愿意为 ?乐机器人,请查看我们的贡献指南。
要将数据集添加到中心,您需要使用写入访问令牌登录,该令牌可以从 Hugging Face 设置生成:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential然后指向您的原始数据集文件夹(例如data/aloha_static_pingpong_test_raw ),并使用以下命令将数据集推送到集线器:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5有关更多说明,请参阅python lerobot/scripts/push_dataset_to_hub.py --help 。
如果您的数据集格式不受支持,请通过复制诸如 Pusht_zarr、umi_zarr、aloha_hdf5 或 xarm_pkl 之类的示例,在lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py中实现您自己的数据集格式。
训练完策略后,您可以使用类似于${hf_user}/${repo_name} (例如 lerobot/diffusion_pusht)的集线器 ID 将其上传到 Hugging Face 中心。
您首先需要找到位于实验目录中的检查点文件夹(例如outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 )。其中有一个pretrained_model目录,其中应包含:
config.json :策略配置的序列化版本(遵循策略的数据类配置)。model.safetensors :一组torch.nn.Module参数,以 Hugging Face Safetensors 格式保存。config.yaml :包含策略、环境和数据集配置的整合 Hydra 训练配置。策略配置应与config.json完全匹配。环境配置对于任何想要评估您的策略的人都很有用。数据集配置只是作为可重复性的书面记录。要将这些上传到中心,请运行以下命令:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_model有关其他人如何使用您的策略的示例,请参阅 eval.py。
用于分析策略评估的代码片段示例:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function 如果您愿意,您可以通过以下方式引用这项工作:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}此外,如果您正在使用任何特定的策略架构、预训练模型或数据集,建议引用该作品的原始作者,如下所示:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

