EasyOCR
v1.7.2
即用型 OCR,支持 80 多种语言和所有流行的书写脚本,包括:拉丁文、中文、阿拉伯文、梵文、西里尔文等。
在我们的网站上尝试演示
融入 Huggingface 空间?使用Gradio。尝试一下网络演示:
2024 年 9 月 24 日 - 版本 1.7.2
阅读所有发行说明



使用pip安装
对于最新的稳定版本:
pip install easyocr对于最新的开发版本:
pip install git+https://github.com/JaidedAI/EasyOCR.git注 1:对于 Windows,请先按照官方说明安装 torch 和 torchvision https://pytorch.org。在 pytorch 网站上,请务必选择您拥有的正确的 CUDA 版本。如果您打算仅在 CPU 模式下运行,请选择CUDA = None 。
注2:我们在这里还提供了一个Dockerfile。
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )输出将采用列表格式,每个项目分别代表一个边界框、检测到的文本和置信度。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)]注1: ['ch_sim','en']是您要阅读的语言列表。您可以同时传递多种语言,但并非所有语言都可以一起使用。英语与所有语言兼容,并且具有共同字符的语言通常彼此兼容。
注 2:除了文件路径chinese.jpg之外,您还可以传递 OpenCV 图像对象(numpy 数组)或图像文件作为字节。原始图像的 URL 也是可以接受的。
注3:行reader = easyocr.Reader(['ch_sim','en'])用于将模型加载到内存中。这需要一些时间,但只需运行一次。
您还可以设置detail=0以获得更简单的输出。
reader . readtext ( 'chinese.jpg' , detail = 0 )结果:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]所选语言的模型权重将自动下载,或者您可以从模型中心手动下载它们并将其放入“~/.EasyOCR/model”文件夹中
如果您没有 GPU,或者您的 GPU 内存不足,您可以通过添加gpu=False以仅 CPU 模式运行模型。
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )有关更多信息,请阅读教程和 API 文档。
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True对于识别模型,请阅读此处。
对于检测模型 (CRAFT),请阅读此处。
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )我们的想法是能够将任何最先进的模型插入 EasyOCR。有很多天才试图做出更好的检测/识别模型,但我们并不是想成为天才。我们只是想让公众能够快速免费地接触到他们的作品。 (好吧,我们相信大多数天才都希望他们的工作尽可能快/尽可能大地产生积极影响)管道应该如下图所示。灰色插槽是可更换浅蓝色模块的占位符。
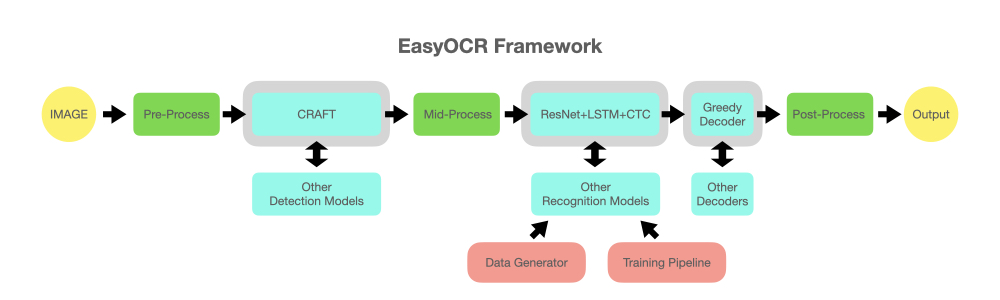
该项目基于多篇论文和开源存储库的研究和代码。
所有深度学习执行均基于 Pytorch。 ❤️
检测执行使用此官方存储库及其论文中的 CRAFT 算法(感谢来自 @clovaai 的 @YoungminBaek)。我们还使用他们的预训练模型。训练脚本由@gmuffiness 提供。
识别模型是CRNN(论文)。它由 3 个主要组件组成:特征提取(我们目前使用 Resnet)和 VGG、序列标记(LSTM)和解码(CTC)。用于识别执行的训练管道是深度文本识别基准框架的修改版本。 (感谢@clovaai 的@ku21fan)这个存储库是一个值得更多认可的宝石。
Beam 搜索代码基于此存储库和他的博客。 (感谢@githubharald)
数据合成基于TextRecognitionDataGenerator。 (感谢@Belval)
在这里,您可以从 distill.pub 阅读有关 CTC 的精彩内容。
让我们共同进步人类,让人工智能为每个人所用!
3 种贡献方式:
编码员:请发送 PR 以了解小错误/改进。对于更大的问题,请先打开问题与我们讨论。有一个可能的错误/改进问题的列表,标记为“PR WELCOME”。
用户:告诉我们 EasyOCR 如何使您/您的组织受益,以鼓励进一步发展。还在问题部分发布失败案例以帮助改进未来的模型。
技术负责人/大师:如果您发现这个库有用,请传播! (参见 Yann Lecun 关于 EasyOCR 的帖子)
要请求新语言,我们需要您发送包含以下 2 个文件的 PR:
如果您的语言有独特的元素(例如 1. 阿拉伯语:字符相互连接时会改变形式 + 从右向左书写 2. 泰语:有些字符需要位于行上方,有些位于行下方),请教育我们最好您的能力和/或提供有用的链接。为了实现真正有效的系统,关注细节非常重要。
最后,请理解,我们的优先级必须是流行语言或彼此共享大部分字符的语言集(也请告诉我们您的语言是否属于这种情况)。我们至少需要一周的时间来开发新型号,因此您可能需要等待一段时间才能发布新型号。
请参阅正在开发的语言列表
由于资源有限,超过 6 个月的问题将自动关闭。如果问题很关键,请再次提出问题。
对于企业支持,Jaided AI 为定制 OCR/AI 系统提供从实施、培训/微调到部署的全方位服务。单击此处联系我们。


