nmt
1.0.0
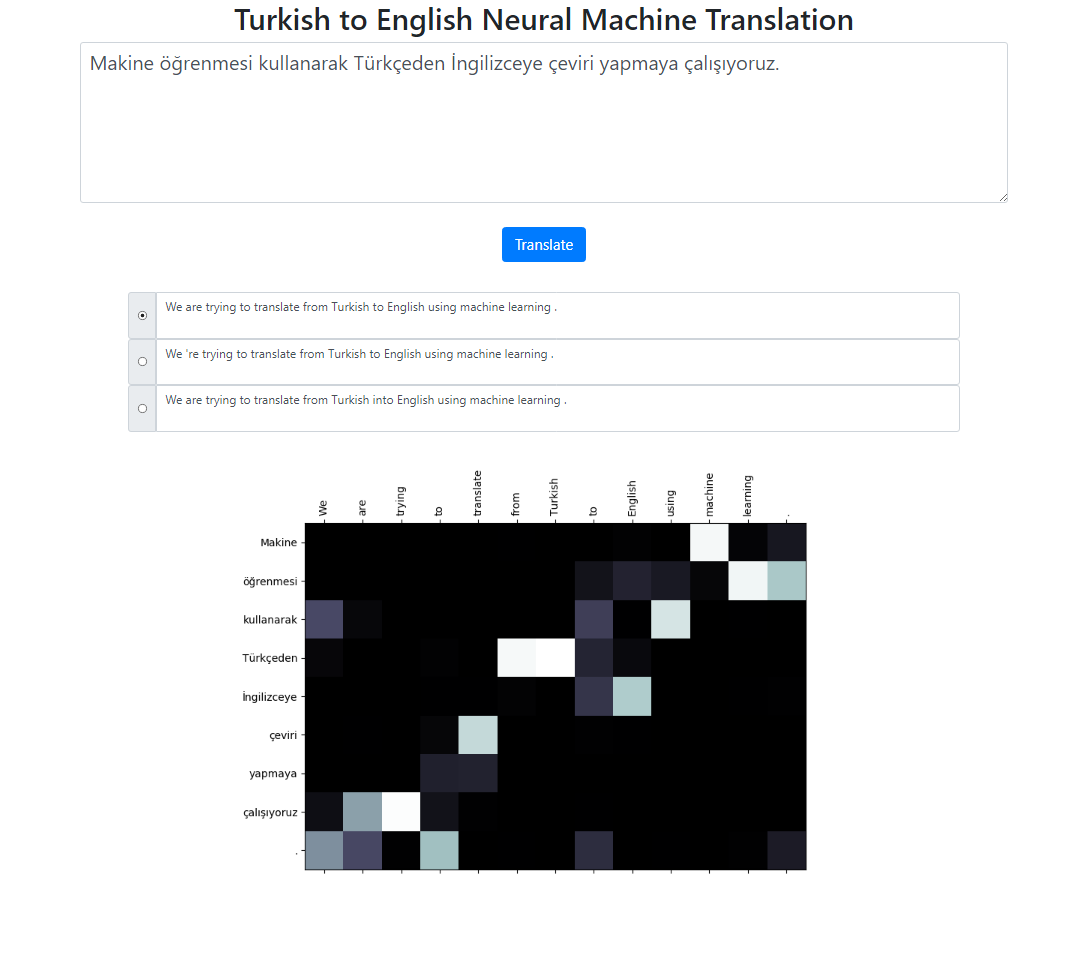
该存储库使用 Seq2Seq + Global Attention 模型实现土耳其语到英语的神经机器翻译系统。还有一个可以在本地运行的 Flask 应用程序。您可以输入文本、翻译并检查结果以及注意力可视化。我们在后台运行波束大小为 3 的波束搜索,并返回按相对分数排序的最可能的序列。
该项目的数据集取自此处。我使用了 Tatoeba 语料库。我删除了数据中发现的一些重复项。我还对数据集进行了预标记。最终版本可以在数据文件夹中找到。
为了标记土耳其语句子,我使用了 nltk 的 RegexpTokenizer。
puncts_ except_apostrope = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_ except_apostrope}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "泰坦尼克号 15 尼散月pazartesi saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# 输出:泰坦尼克号 15 Nisan pazartesi saat 02 : 20 'de battı .# “02 上的此分割属性: 20" 与英语分词器不同。# 我们可以处理这些情况。但我想要为了简单起见,看看 # 这些单词的注意力分布是否与英语标记一致。# 类似的情况主要集中在日期上,如本例所示:02/09/2019为了标记英语句子,我使用了 spacy 的英语模型。
en_nlp = spacy.load('en_core_web_sm')text = "泰坦尼克号于 4 月 15 日星期一 02:20 沉没。"tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))# 输出:泰坦尼克号于 4 月 15 日星期一 02:20 沉没。土耳其语和英语句子预计位于两个不同的文件中。
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
请运行python train.py -h以获取完整的参数列表。
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
计算语料库级别的蓝色分数。
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
要在本地运行应用程序,请运行:
python app.py
确保config.py文件中的模型路径已正确定义。
模型文件
词汇文件
使用子词单位(土耳其语和英语)
不同的注意力机制(学习不同的注意力参数)
该项目的骨架代码取自斯坦福大学的 NLP 课程:CS224n


