LVBench
1.0.0
[项目页面] [ arXiv 论文] [ 数据集][?排行榜][?拥抱排行榜]
LVBench 是一个基准测试,旨在评估和增强多模态模型从长达两小时的长视频中理解和提取信息的能力。
2024.08.2我们在 Huggingface Spaces 上设置了 LVBench 排行榜!查看排行榜。
2024.06.11我们发布了长视频理解新基准LVBench!
LVBench 是一个旨在评估模型理解长视频能力的基准。我们从公共来源收集了大量的长视频数据,并通过手动操作和模型辅助进行注释。我们的基准测试为在扩展时间上下文中测试模型提供了坚实的基础,通过细致的人工注释和多阶段质量控制确保高质量的评估。
核心能力:长视频理解的六大核心能力,能够创建复杂且具有挑战性的问题以进行全面的模型评估。
多样化数据:多样化的长视频数据,平均比现有最长数据集长五倍,涵盖各个类别。
高质量注释:可靠的基准,具有细致的人工注释和多阶段质量控制流程。

我们的数据集采用 CC-BY-NC-SA-4.0 许可。
LVBench 仅用于学术研究。禁止任何形式的商业用途。我们不拥有任何原始视频文件的版权。
如果LVBench有侵权行为,请联系[email protected]或直接提出issue,我们将立即删除。
首先安装video2dataset:
pip 安装 video2dataset pip 卸载变压器引擎
然后你应该从 Huggingface 下载video_info.meta.jsonl并将其放在data目录中。
video_info.meta.jsonl文件中的每个条目都有一个与 YouTube 视频 ID 相对应的关键字段。用户可以使用该ID下载对应的视频。或者,用户可以使用我们提供的下载脚本download.sh进行下载:
光盘脚本 bash下载.sh
执行后,视频文件将存放在script/videos目录下。
pip install -e 。
(注:如果您想快速尝试评估,可以使用scripts/construct_random_answers.py准备随机答案文件。)
光盘脚本 python test_acc.py
执行完成后,会在scripts目录下得到一个评估结果文件result.json 。您可以将结果提交到排行榜。
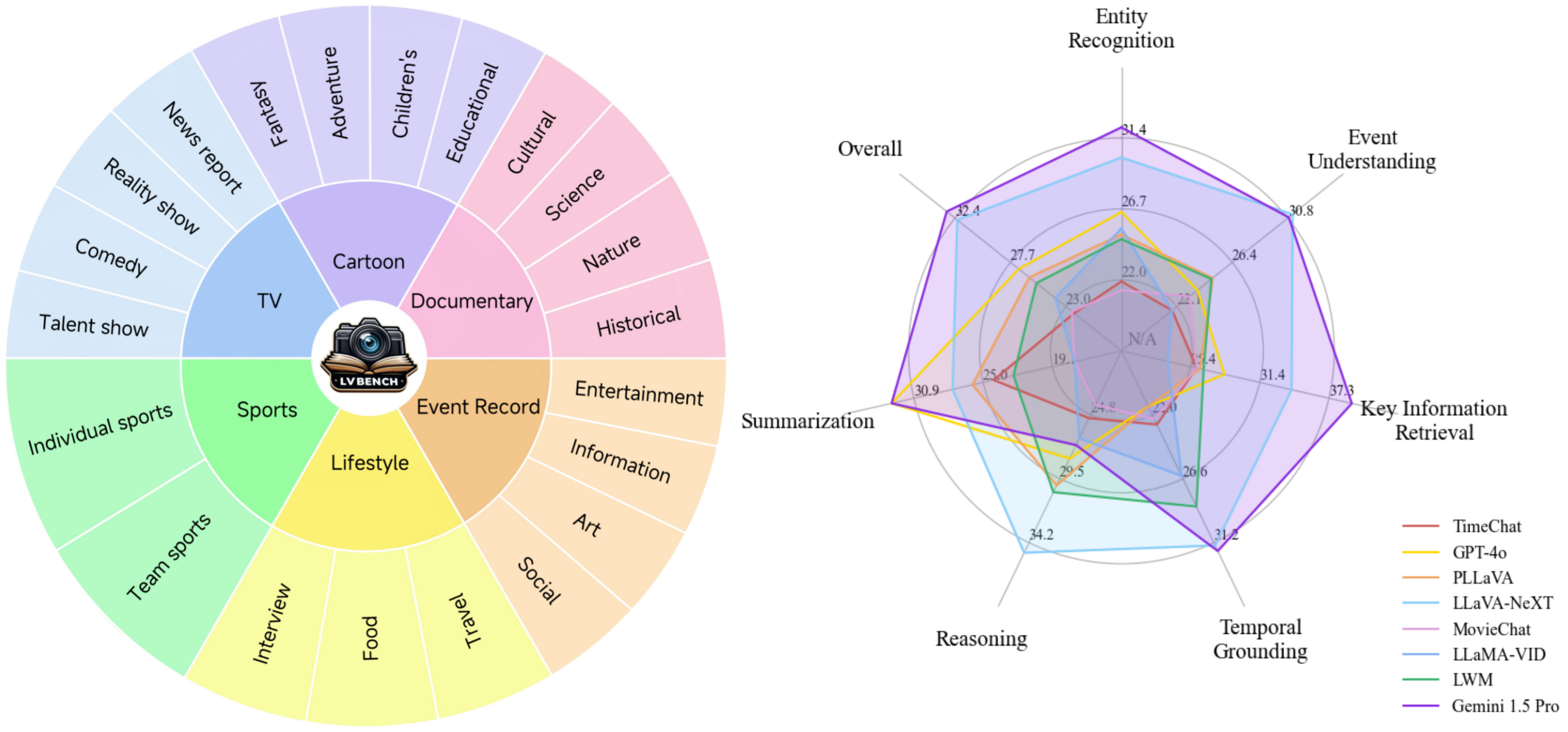
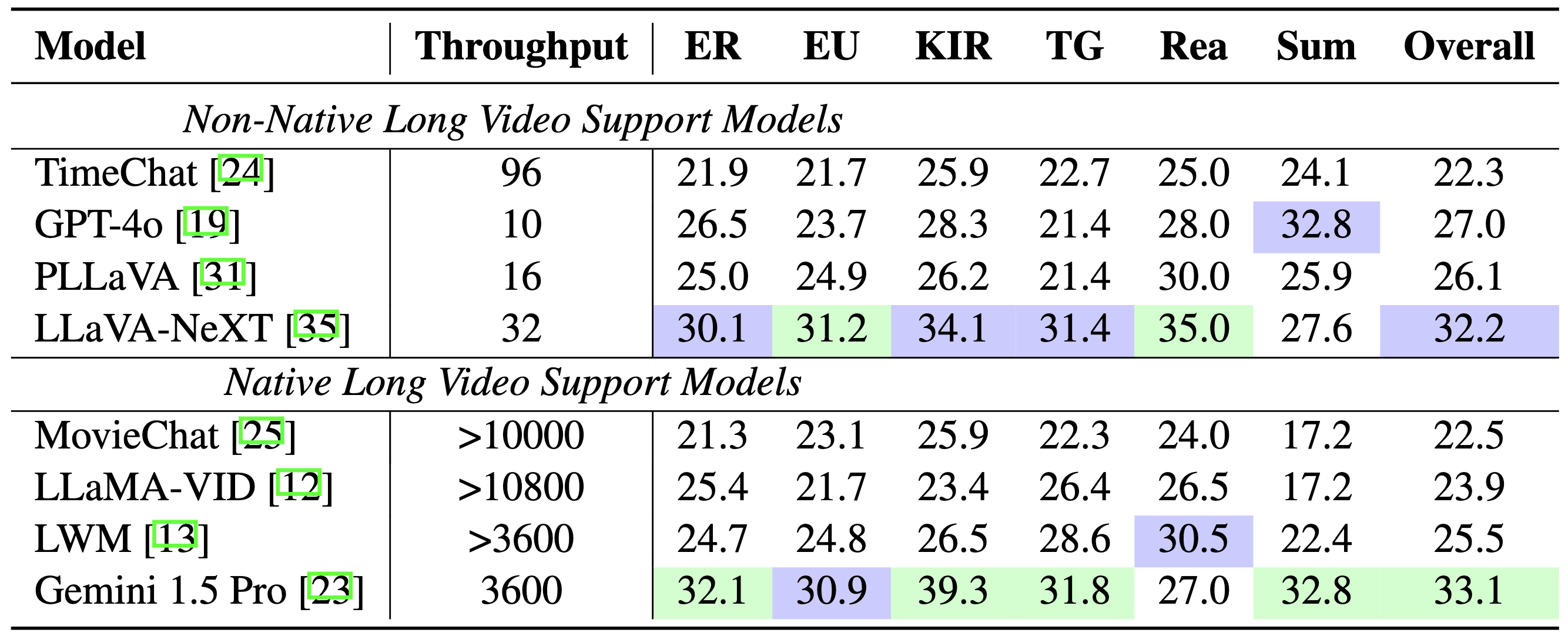
型号对比:
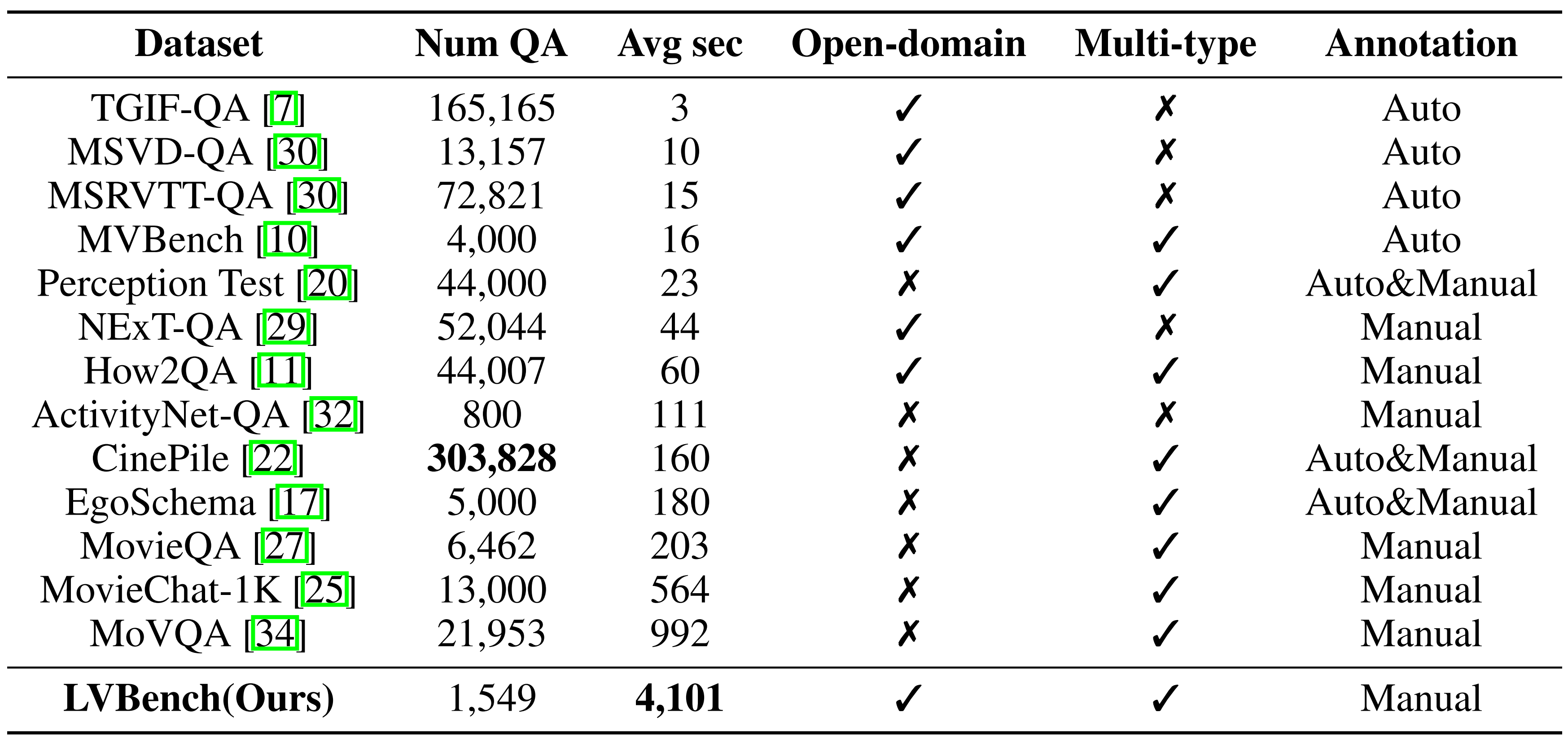
基准比较:
模型与人类:

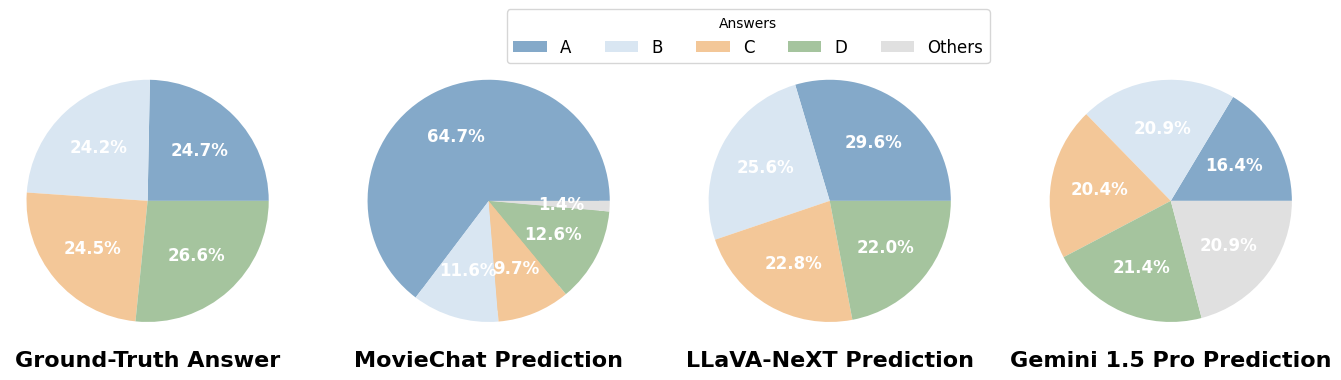
答案分布:
如果您发现我们的工作对您的研究有帮助,请考虑引用我们的工作。
@misc{wang2024lvbench, title={LVBench:超长视频理解基准},
作者={Weihan Wang、Zehai He、Wenyi Hong、Yan Cheng、Xiaohan Zhang、Ji Qi、Shiyu Huang、Bin Xu、Yuxia Dong、Ming Ding、Jie Tang},year={2024},eprint={2406.08035},archivePrefix ={arXiv},primaryClass={cs.CV}} 

