图书推荐系统是一种根据用户的兴趣和阅读历史向用户推荐图书的工具。图书馆、书店或在线零售商可以使用这些系统来帮助用户发现他们可能喜欢的新书。
构建图书推荐系统有多种方法,包括协作过滤、基于内容的过滤以及结合这两种方法的混合系统。
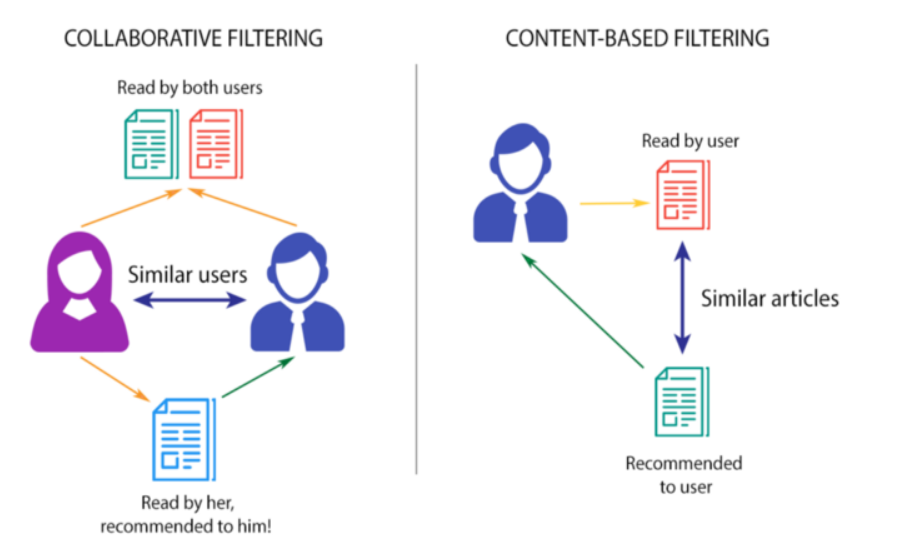
协同过滤基于这样的想法:具有相似阅读历史的用户可能有相似的兴趣,因此一个用户喜欢的一本书很可能被具有相似阅读历史的另一个用户喜欢。这种方法通常用于电影、音乐和其他产品的推荐系统。
而基于内容的过滤则侧重于书籍本身的特征,例如类型、主题、作者等,来进行推荐。当没有足够的关于用户使用协同过滤的偏好的数据时,此方法非常有用。
混合系统结合协作过滤和基于内容的过滤来提出推荐。他们可以兼顾图书的特点和用户的喜好,提供更加个性化的推荐。
构建有效的图书推荐系统面临一些挑战,包括需要大量数据来训练系统、自然语言处理的复杂性以及需要平衡推荐的个性化与推荐图书的多样性。
Book-Crossing 数据集包含 3 个文件。
用户:包含用户。请注意,用户 ID (User-ID) 已被匿名化并映射为整数。如果有的话,提供人口统计数据(位置、年龄)。否则,这些字段包含 NULL 值。
书籍:书籍由各自的 ISBN 标识。无效的 ISBN 已从数据集中删除。此外,还给出了从 Amazon Web Services 获取的一些基于内容的信息(书名、书作者、出版年份、出版商)。请注意,如果有多个作者,则仅提供第一个作者。还给出了链接到封面图像的 URL,以三种不同的形式出现(Image-URL-S、Image-URL-M、Image-URL-L),即小、中、大。这些 URL 指向亚马逊网站。
评级:包含书籍评级信息。评级(图书评级)可以是显式的,以 1-10 的范围表示(较高的值表示较高的欣赏度),也可以是隐式的,以 0 表示。
数据集链接:- https://drive.google.com/drive/folders/1Gi0wMWCTigA_rJSi9huyT51lKduBSv43?usp=share_link


