hercules
v10.7.2
快速、富有洞察力且高度可定制的 Git 历史分析。
概述 • 如何使用 • 安装 • 贡献 • 许可证
Hercules 是一个用 Go 编写的速度极快且高度可定制的 Git 存储库分析引擎。包含电池。由 go-git 提供支持。
通知(2020年11月):主要作者已从冷漠中回归,正在逐步恢复开发。请参阅路线图。
有两个命令行工具: hercules和labours 。第一个是用 Go 编写的程序,它采用 Git 存储库并在完整提交历史记录上执行分析任务的有向无环图 (DAG)。第二个是一个 Python 脚本,它显示了收集到的数据的一些预定义图。这两个工具通常通过管道一起使用。可以使用插件系统编写自定义分析。还可以将多个分析结果合并在一起 - 与组织相关。分析的提交历史包括分支、合并等。
Hercules 已成功用于来源{d} 的多个内部项目。有博客文章:1、2 和演示文稿。请通过测试、修复错误、添加新分析或编码来做出贡献!
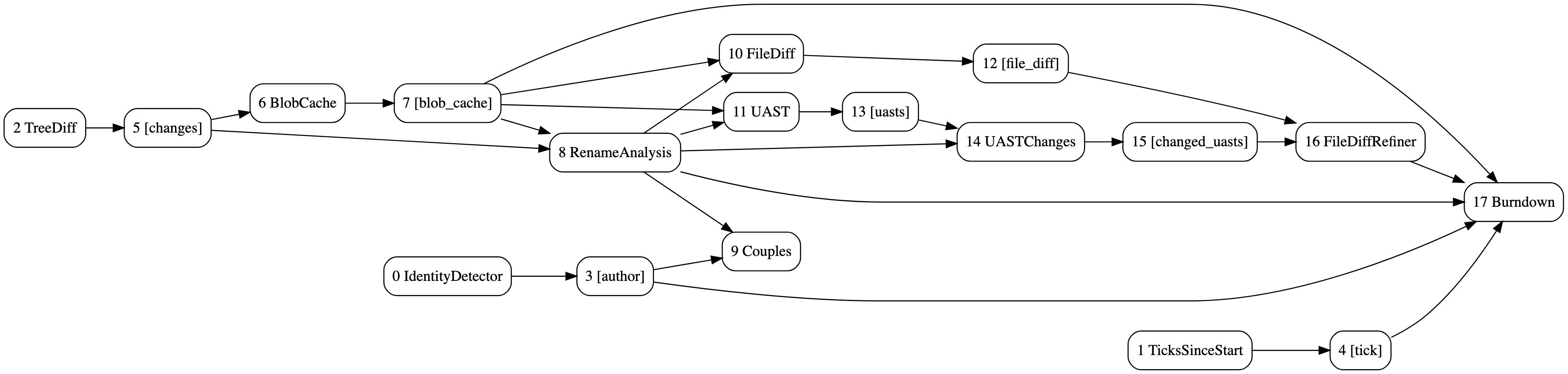
燃尽图的 DAG 以及与 UAST diff 细化的耦合分析。使用hercules --burndown --burndown-people --couples --feature=uast --dry-run --dump-dag doc/dag.dot https://github.com/src-d/hercules
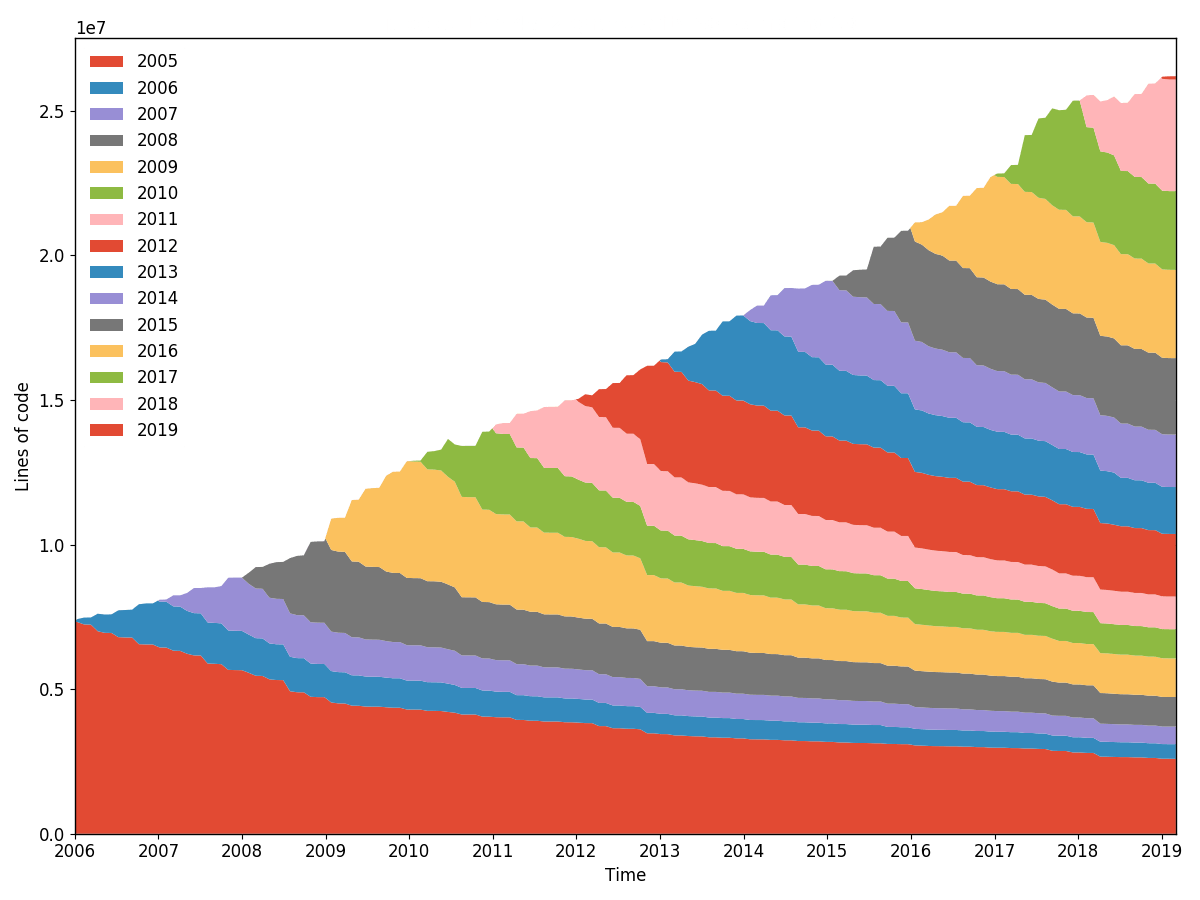
torvalds/linux 线路燃尽图(粒度 30,采样 30,按年份重新采样)。使用hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project生成1 小时 40 分钟内hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project 。
从发布页面获取hercules二进制文件。 labours可以从 PyPi 安装:
pip3 install labours
pip3是 Python 包管理器。
Numpy 和 Scipy 可以使用 http://www.lfd.uci.edu/~gohlke/pythonlibs/ 安装在 Windows 上
您将需要 Go (>= v1.11) 和protoc 。
git clone https://github.com/src-d/hercules && cd hercules
make
pip3 install -e ./python
可以将 Hercules 作为 GitHub Action 运行:GitHub Marketplace 上的 Hercules。请参阅演示如何设置的示例工作流程。
...欢迎光临!请参阅贡献和行为准则。
阿帕奇2.0
最有用且可靠的最新命令行参考:
hercules --help
一些例子:
# Use "memory" go-git backend and display the burndown plot. "memory" is the fastest but the repository's git data must fit into RAM.
hercules --burndown https://github.com/go-git/go-git | labours -m burndown-project --resample month
# Use "file system" go-git backend and print some basic information about the repository.
hercules /path/to/cloned/go-git
# Use "file system" go-git backend, cache the cloned repository to /tmp/repo-cache, use Protocol Buffers and display the burndown plot without resampling.
hercules --burndown --pb https://github.com/git/git /tmp/repo-cache | labours -m burndown-project -f pb --resample raw
# Now something fun
# Get the linear history from git rev-list, reverse it
# Pipe to hercules, produce burndown snapshots for every 30 days grouped by 30 days
# Save the raw data to cache.yaml, so that later is possible to labours -i cache.yaml
# Pipe the raw data to labours, set text font size to 16pt, use Agg matplotlib backend and save the plot to output.png
git rev-list HEAD | tac | hercules --commits - --burndown https://github.com/git/git | tee cache.yaml | labours -m burndown-project --font-size 16 --backend Agg --output git.png
labours -i /path/to/yaml允许读取保存在磁盘上的hercules的输出。
可以将克隆的存储库存储在磁盘上。后续的分析可以在对应的目录上运行,而不用从头克隆:
# First time - cache
hercules https://github.com/git/git /tmp/repo-cache
# Second time - use the cache
hercules --some-analysis /tmp/repo-cache
该操作会生成名为hercules_charts的工件。由于目前不可能将多个文件打包到一个工件中,因此所有图表和 Tensorflow Projector 文件都打包在内部 tar 存档中。要查看嵌入,请访问projector.tensorflow.org,单击“加载”并选择两个 TSV。然后使用 UMAP 或 T-SNE。
docker run --rm srcd/hercules hercules --burndown --pb https://github.com/git/git | docker run --rm -i -v $(pwd):/io srcd/hercules labours -f pb -m burndown-project -o /io/git_git.png
hercules --burndown
labours -m burndown-project
整个存储库的线路燃尽统计。与 git-of-theseus 的做法完全相同,但速度更快。使用自定义 RB 树跟踪算法高效且增量地执行责备,并且在运行分析时仅记录最后的修改日期。
所有燃尽分析都取决于粒度和采样的值。粒度是堆栈中每个带组成的天数。采样是对倦怠状态进行快照的频率。值越小,绘图越平滑,但完成的工作量也越多。
有一个选项可以对labours内的波段进行重新采样,以便您可以定义非常精确的分布并以不同的方式将其可视化。此外,重采样可以跨周期边界(例如月或年)对齐频带。未重新采样的频段显然没有对齐,并且从项目的诞生日期开始。
hercules --burndown --burndown-files
labours -m burndown-file
存储库中最新版本中有效的每个文件的燃尽统计信息。
注意:它将为每个文件生成单独的图表。您不想在包含许多文件的存储库上运行它。
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m burndown-person
存储库贡献者的燃尽统计。如果未指定--people-dict ,则通过以下算法发现身份:
如果指定了--people-dict ,它应该指向具有自定义身份的文本文件。格式为:每一行都是一个开发人员,包含所有匹配的电子邮件和姓名,以|分隔。 。该案被忽略。
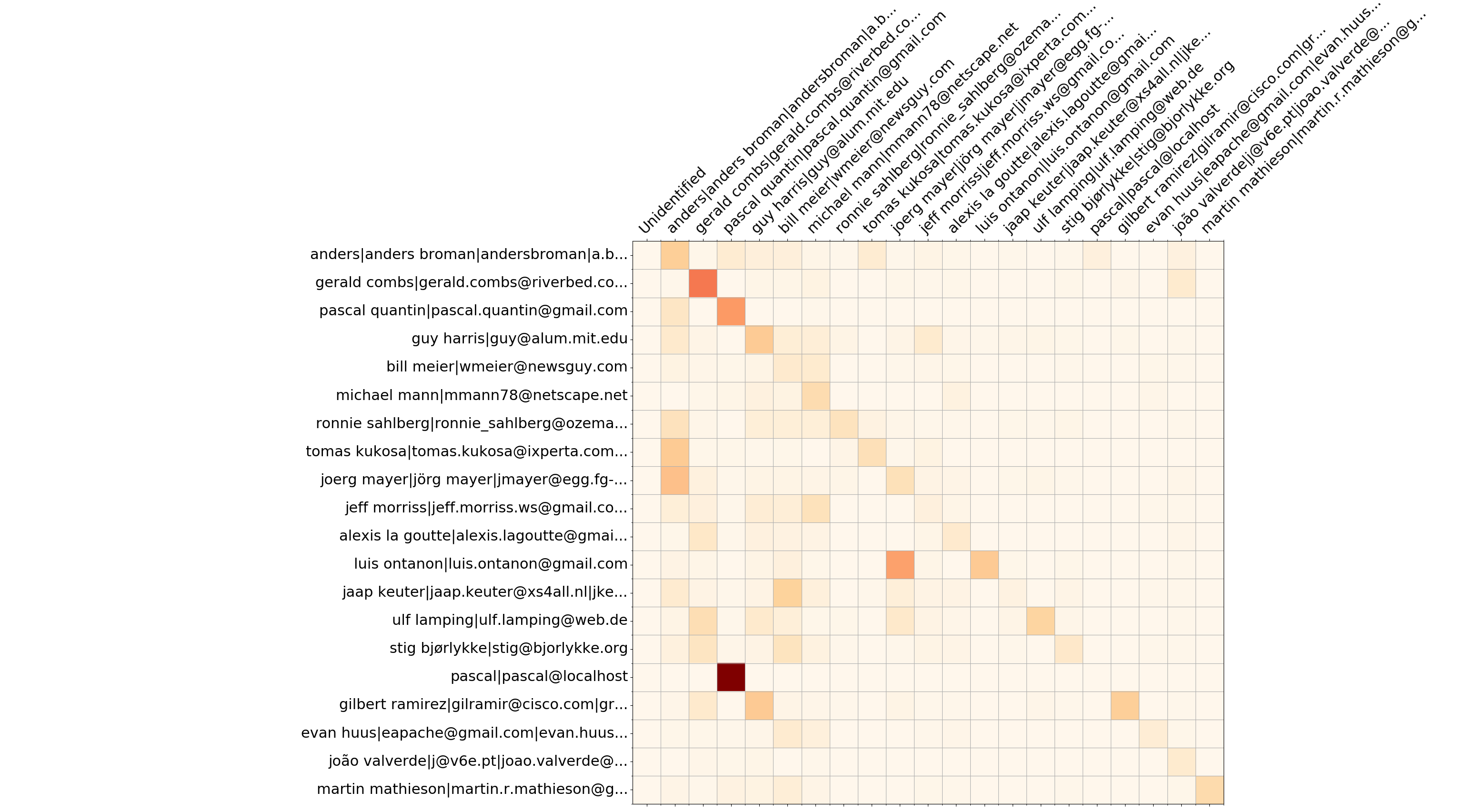
Wireshark 前 20 名开发者 - 覆盖矩阵
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m overwrites-matrix
除了燃尽信息之外, --burndown-people还收集每个开发人员添加和删除的行统计信息。因此可以直观地看到开发人员 A 编写的代码被开发人员 B 删除了多少行。这表明了人员之间的协作并定义了专业团队。
格式是 N 行 (N+2) 列的矩阵,其中 N 是开发人员的数量。
--people-dict ,则始终为 0)。开发人员的序列存储在people_sequence YAML 节点中。
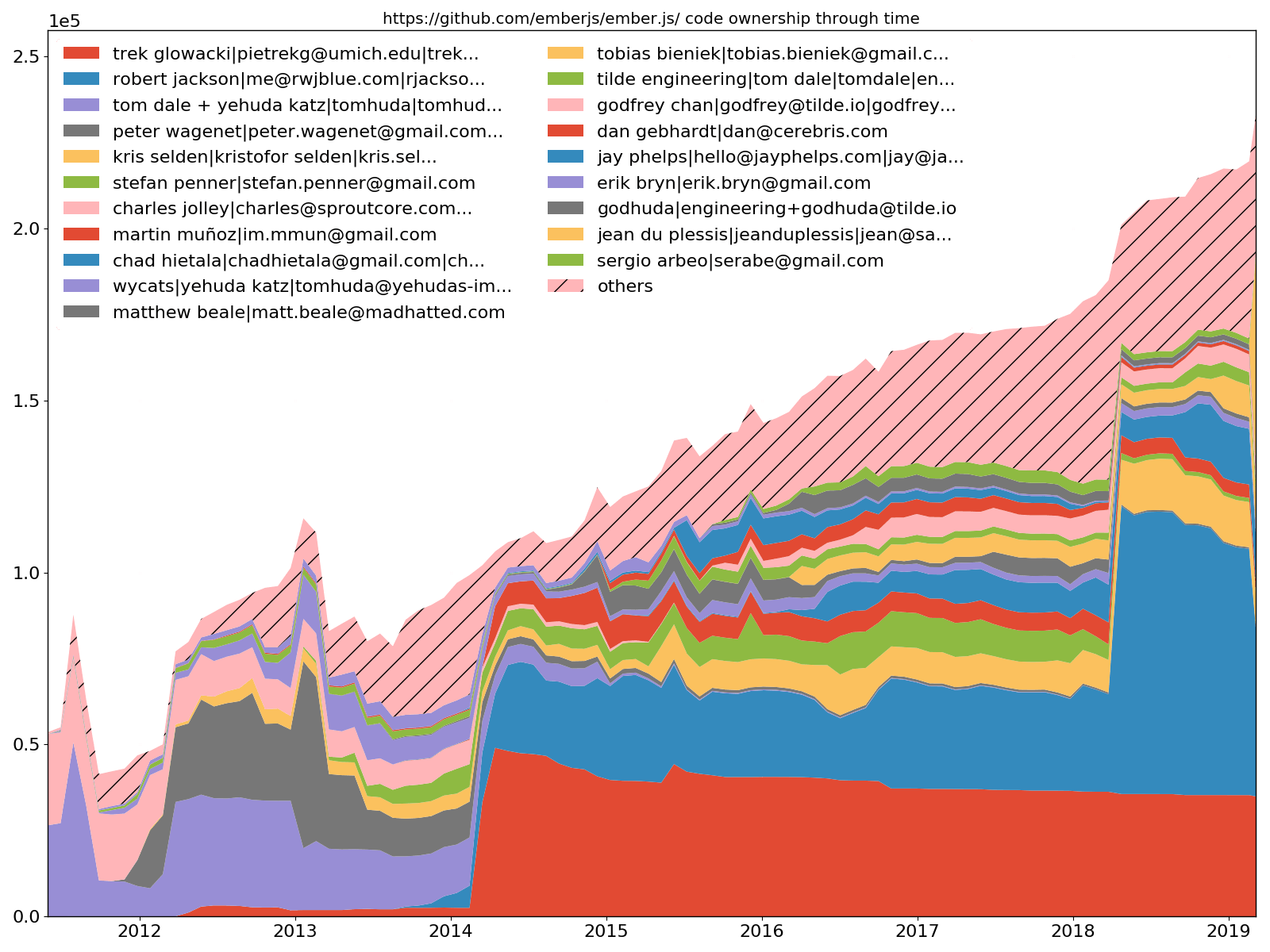
Ember.js 前 20 名开发者 - 代码所有权
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m ownership
--burndown-people还允许通过时间堆积面积图绘制代码共享。也就是说,对于每个已识别的开发人员,在采样时刻有多少行处于活动状态。
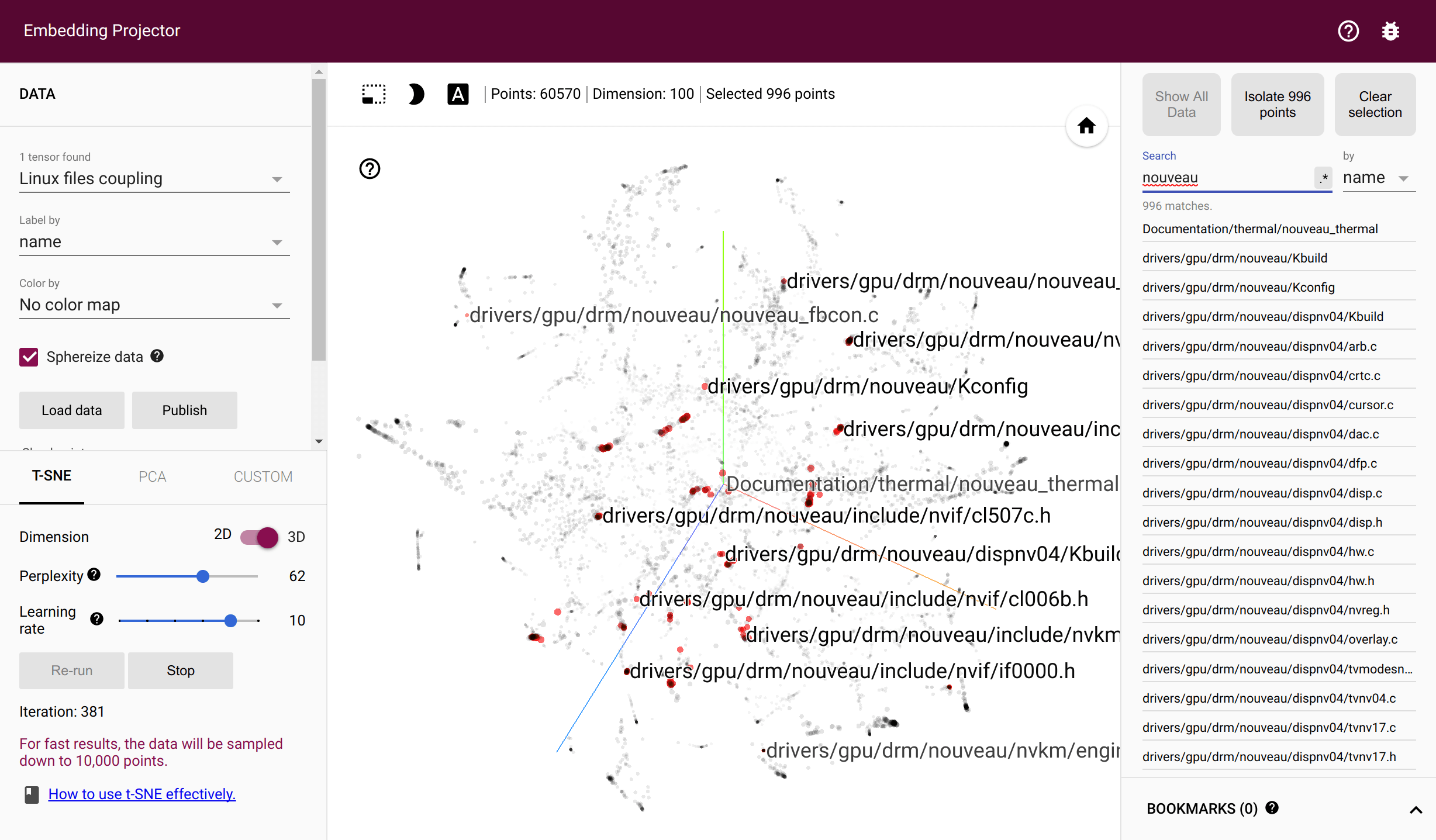
Torvalds/linux 文件在 Tensorflow Projector 中的耦合
hercules --couples [--people-dict=/path/to/identities]
labours -m couples -o <name> [--couples-tmp-dir=/tmp]
重要提示:需要安装 Tensorflow,请遵循官方说明。
如果文件在同一提交中发生更改,则这些文件是耦合的。如果开发人员更改同一个文件,那么他们就是耦合的。 hercules记录整个提交历史中的对数,并输出两个相应的共现矩阵。然后labours旋转嵌入——通过欧几里德距离反映共现概率的密集向量。培训需要安装有效的 Tensorflow。中间文件存储在系统临时目录或--couples-tmp-dir (如果指定)中。训练后的嵌入将写入当前工作目录,名称取决于-o 。输出格式为 TSV,并与 Tensorflow Projector 匹配,以便可以使用 TF Projector 中实现的 t-SNE 来可视化文件和人员。
46 jinja2/compiler.py:visit_Template [FunctionDef]
42 jinja2/compiler.py:visit_For [FunctionDef]
34 jinja2/compiler.py:visit_Output [FunctionDef]
29 jinja2/environment.py:compile [FunctionDef]
27 jinja2/compiler.py:visit_Include [FunctionDef]
22 jinja2/compiler.py:visit_Macro [FunctionDef]
22 jinja2/compiler.py:visit_FromImport [FunctionDef]
21 jinja2/compiler.py:visit_Filter [FunctionDef]
21 jinja2/runtime.py:__call__ [FunctionDef]
20 jinja2/compiler.py:visit_Block [FunctionDef]
借助 Babelfish,Hercules 能够测量每个结构单元被修改的次数。默认情况下,它查看函数;请参阅语义 UAST XPath 手册以切换到其他内容。
hercules --shotness [--shotness-xpath-*]
labours -m shotness
耦合分析会自动加载“shotness”数据(如果可用)。
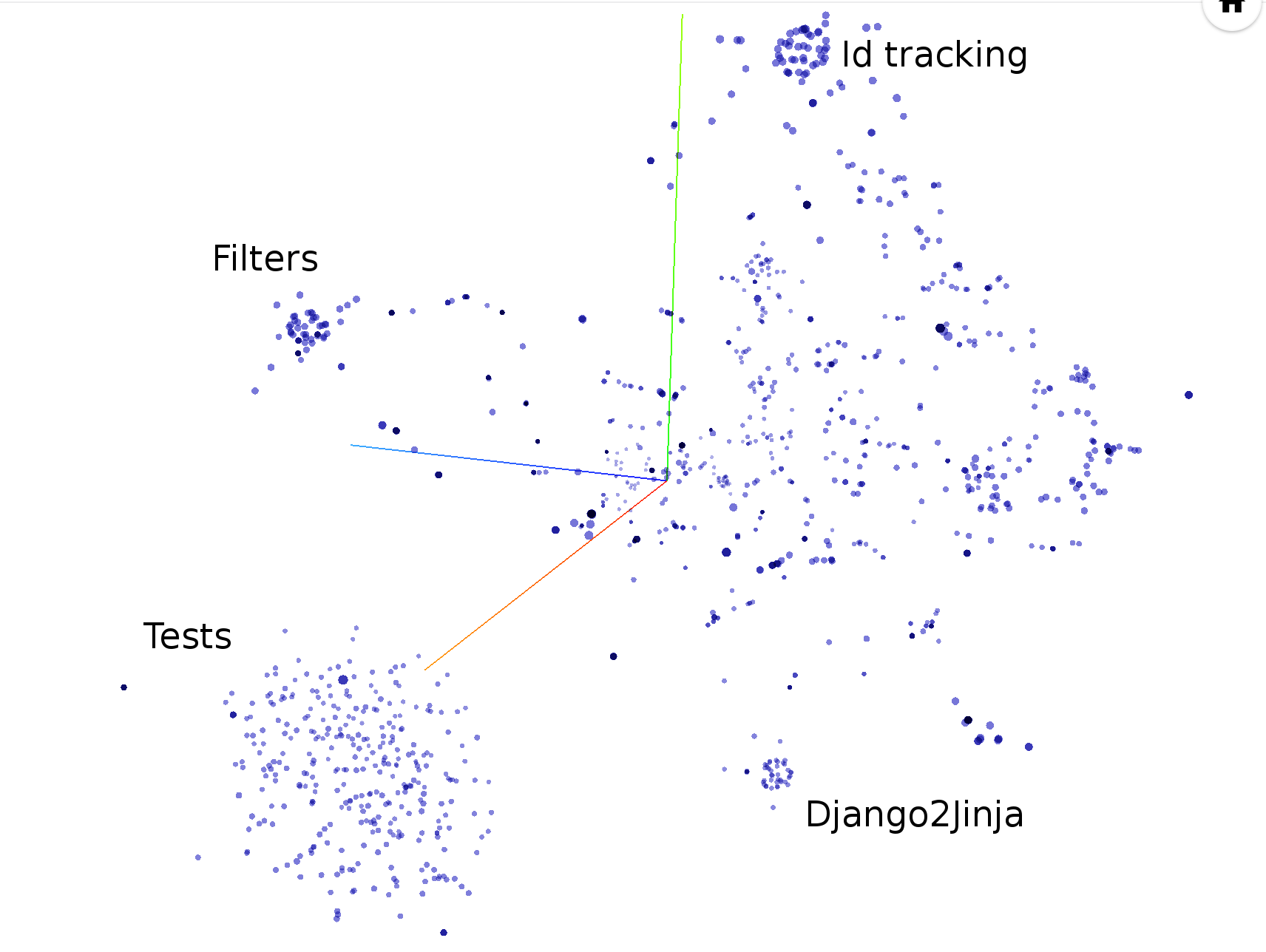
hercules --shotness --pb https://github.com/pallets/jinja | labours -m couples -f pb
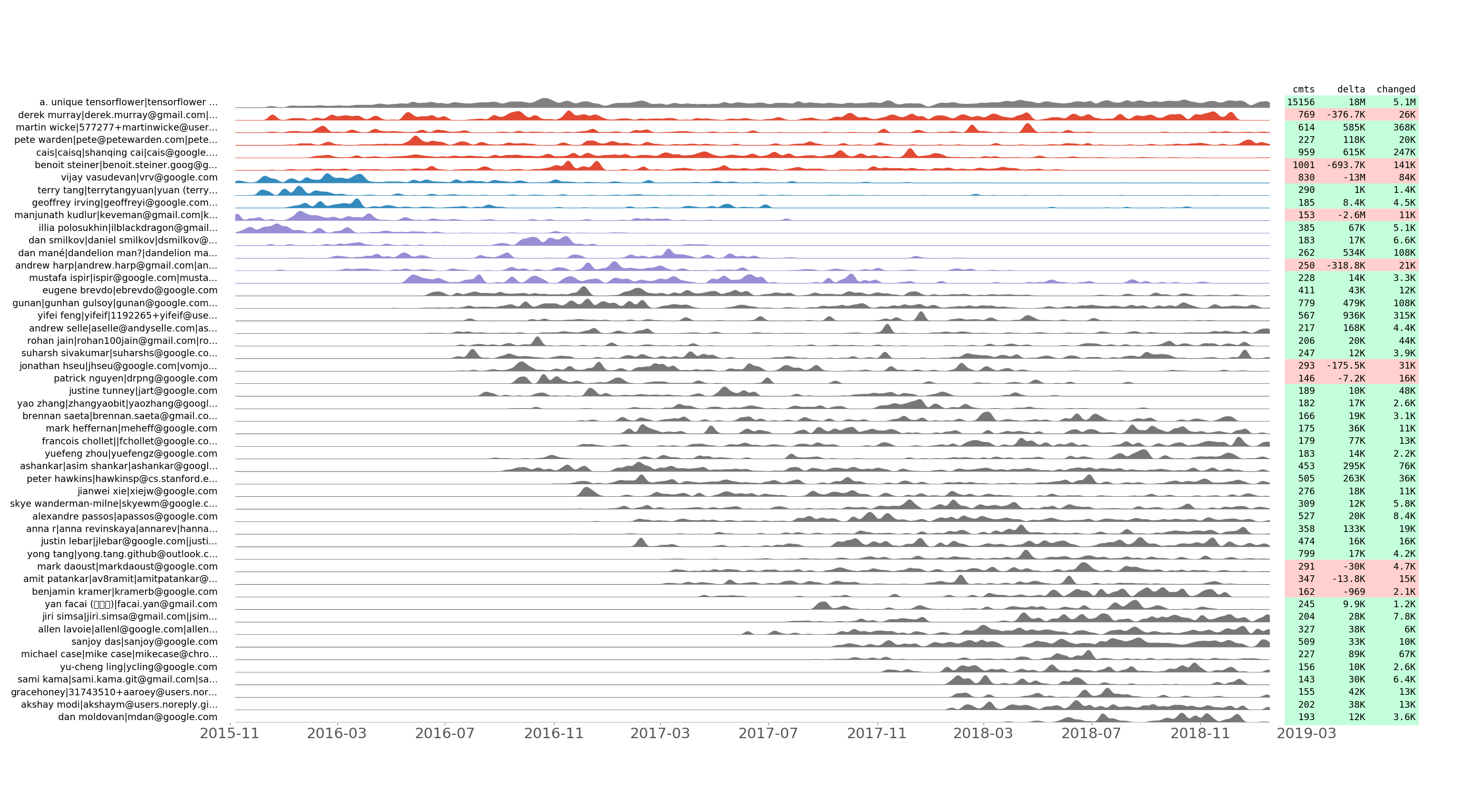
tensorflow/tensorflow 按提交编号排列了前 50 位开发人员的提交系列。
hercules --devs [--people-dict=/path/to/identities]
labours -m devs -o <name>
我们记录每个开发人员每天进行的提交数量以及添加、删除和更改的行数。我们使用一些技巧来绘制生成的提交时间序列来显示时间分组。换句话说,两个相邻的提交系列在标准化后应该看起来相似。
这个情节可以让我们发现开发团队是如何随着时间的推移而演变的。它还展示了“commit flashmobs”,例如 Hacktoberfest。例如,以下是从上面的tensorflow/tensorflow图中揭示的见解:
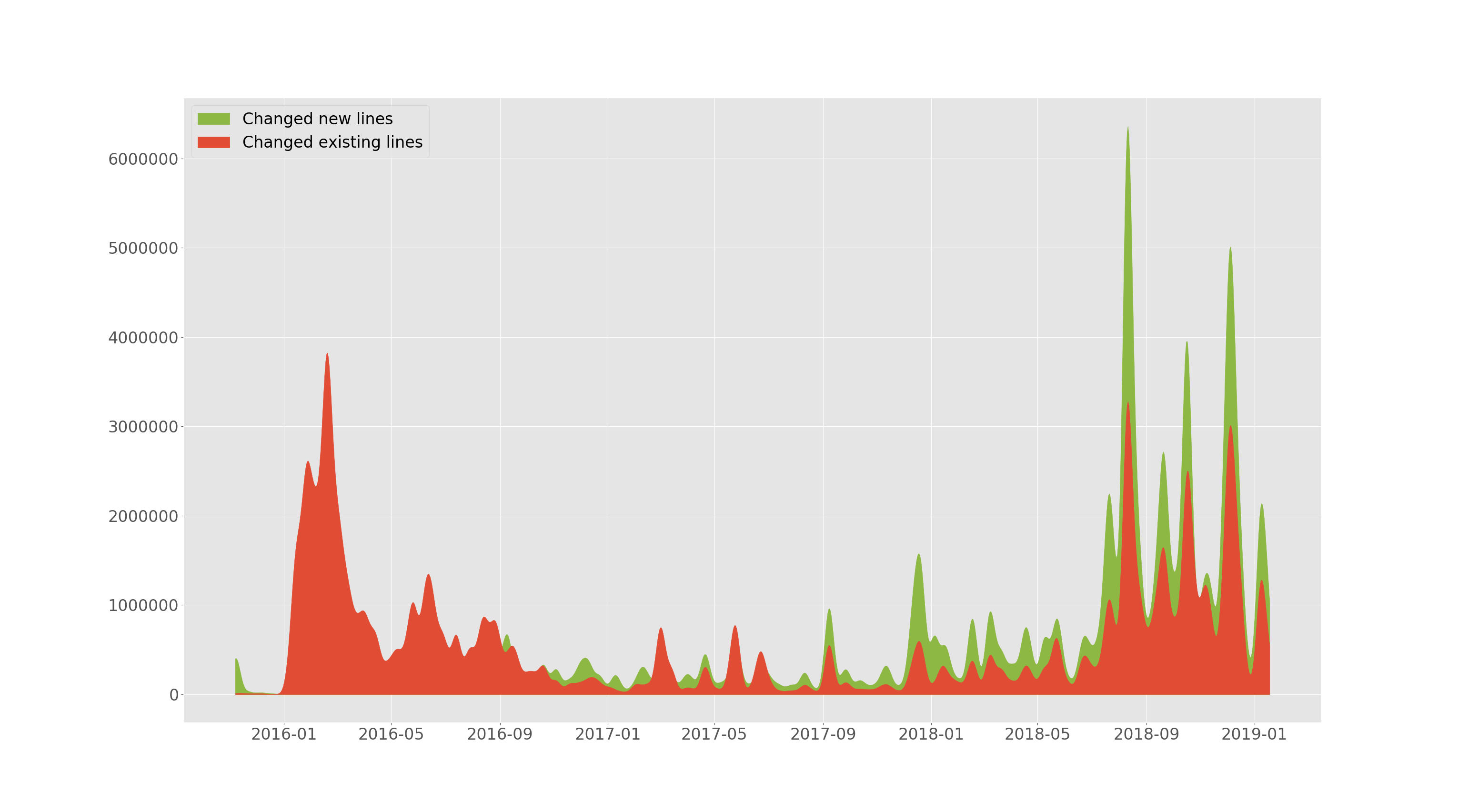
张量流/张量流随着时间的推移添加和更改了行。
hercules --devs [--people-dict=/path/to/identities]
labours -m old-vs-new -o <name>
上一节中的--devs允许绘制随着时间的推移添加了多少行以及有多少现有更改(删除或替换)。该图已平滑。
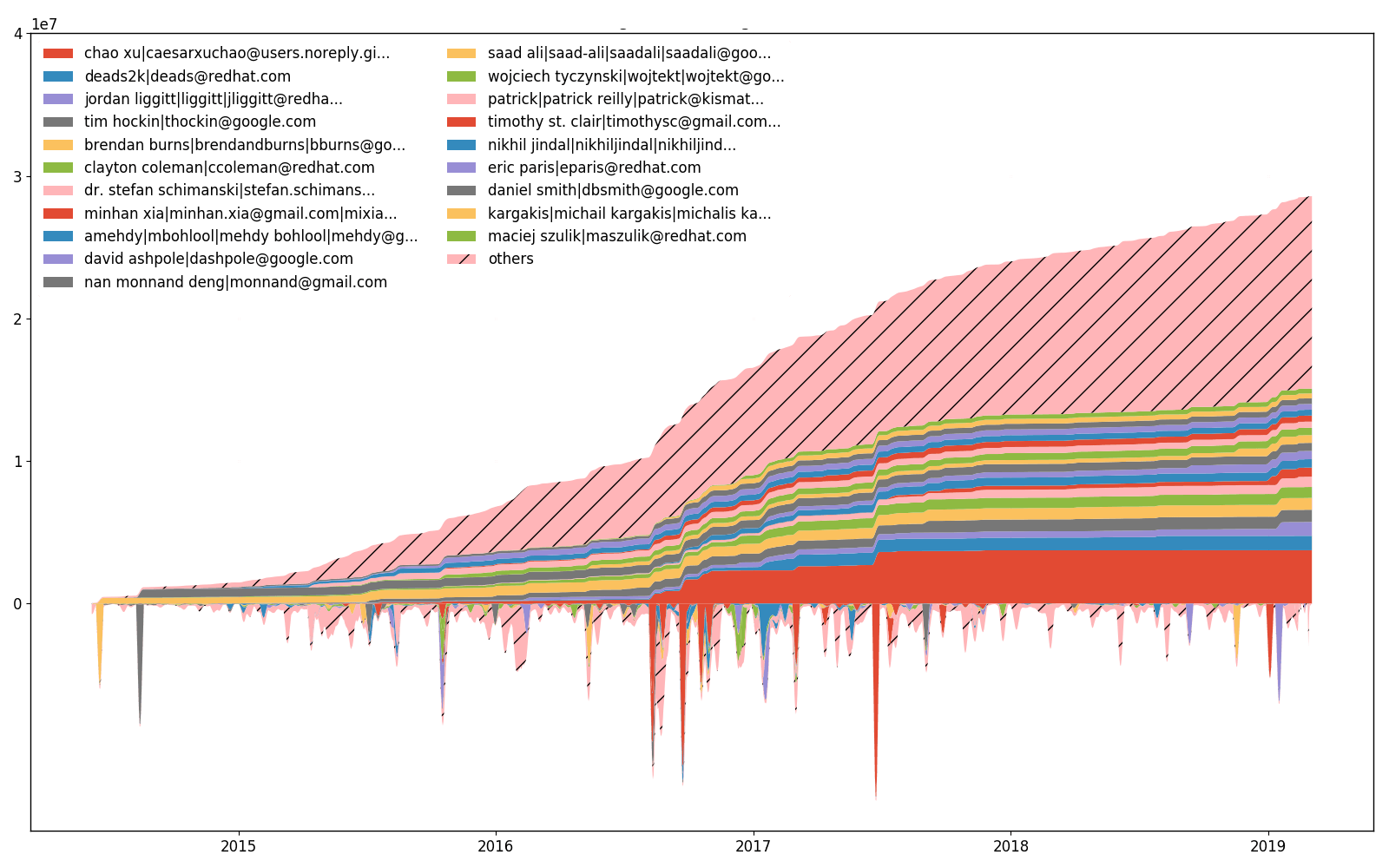
kubernetes/kubernetes 随着时间的推移所做的努力。
hercules --devs [--people-dict=/path/to/identities]
labours -m devs-efforts -o <name>
此外, --devs允许绘制每个开发人员更改(添加或删除)的行数。该图的上半部分是累积(整合)的下半部分。两个部分不可能具有相同的比例,因此对较低的值进行缩放,因此不存在较低的 Y 轴刻度。尽管变化线与拥有线相关,但努力图和所有权图之间存在差异。
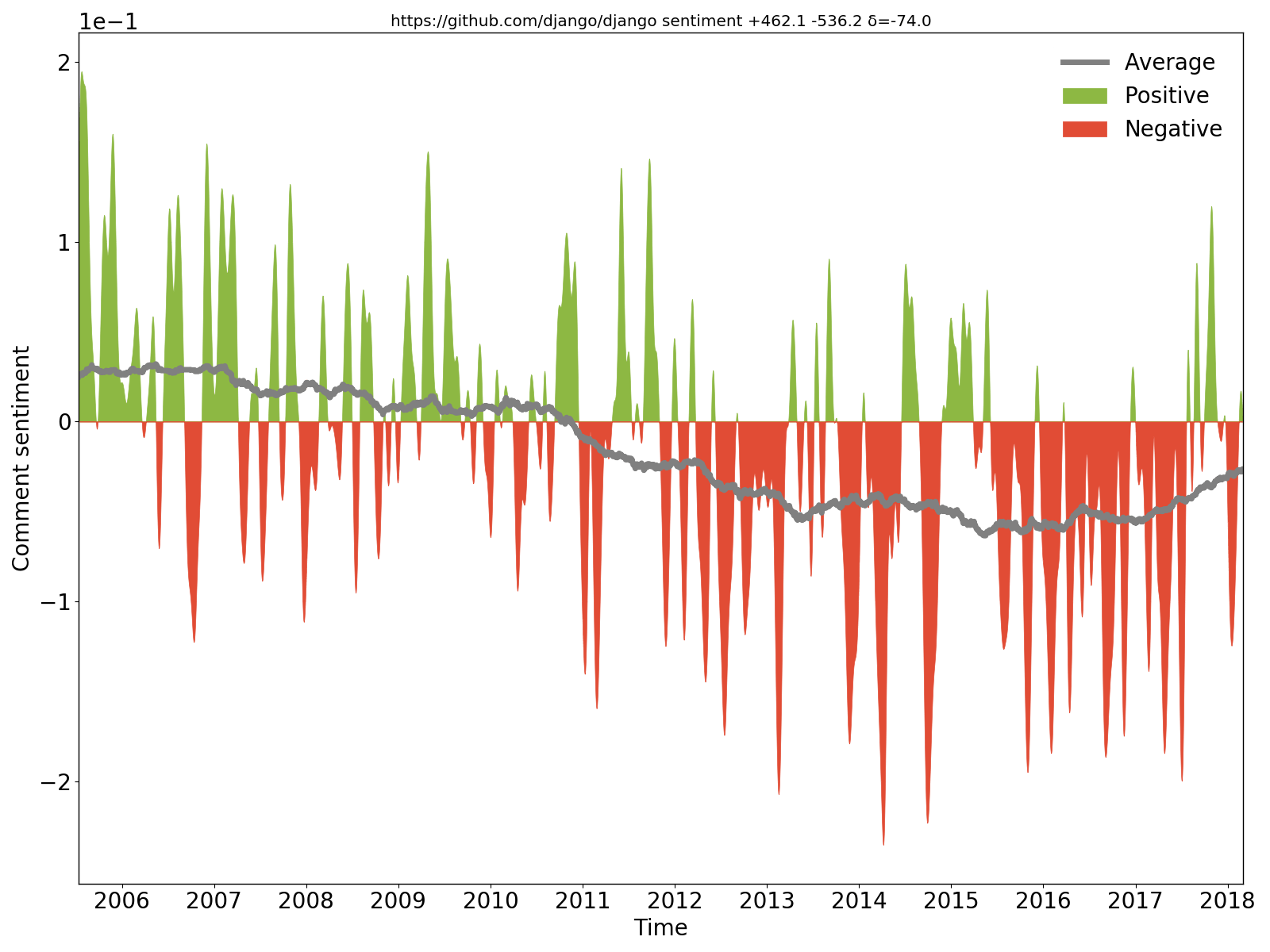
可以清楚地看到,Django 的评论一开始是积极/乐观的,但后来变得消极/悲观。
hercules --sentiment --pb https://github.com/django/django | labours -m sentiment -f pb
我们在每次提交时从源代码中提取新的和更改的注释,应用 BiDiSentiment 通用情感循环神经网络并绘制结果。需要 libtensorflow。例如sadly, we need to hide the rect from the documentation finder for now为负数,而Theano has a built-in optimization for logsumexp (...) so we can just write the expression directly为正数。不过,不要期望太多 - 正如所写的,情感模型是通用目的,代码注释具有不同的性质,因此(目前)没有魔法。
Hercules 必须使用“tensorflow”标签构建 - 默认情况下不是:
make TAGS=tensorflow
这样的构建需要libtensorflow 。
hercules --burndown --burndown-files --burndown-people --couples --shotness --devs [--people-dict=/path/to/identities]
labours -m all
Hercules 有一个插件系统,允许运行自定义分析。请参阅 PLUGINS.md。
hercules combine是将多个Protocol Buffers格式的分析结果连接在一起的命令。
hercules --burndown --pb https://github.com/go-git/go-git > go-git.pb
hercules --burndown --pb https://github.com/src-d/hercules > hercules.pb
hercules combine go-git.pb hercules.pb | labours -f pb -m burndown-project --resample M
YAML 不支持整个 Unicode 字符范围,并且labours端的解析器可能会引发异常。通过fix_yaml_unicode.py过滤hercules的输出以丢弃此类违规字符。
hercules --burndown --burndown-people https://github.com/... | python3 fix_yaml_unicode.py | labours -m people
这些选项影响所有绘图:
labours [--style=white|black] [--backend=] [--size=Y,X]
--style设置情节的总体风格(请参阅labours --help )。 --background将绘图背景更改为白色或黑色。 --backend选择 Matplotlib 后端。 --size设置图形的大小(以英寸为单位)。默认值为12,9 。
(macOS 中必需)您可以使用以下命令固定默认的 Matplotlib 后端
echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
这些选项仅在燃尽图中有效:
labours [--text-size] [--relative]
--text-size更改字体大小, --relative激活拉伸的燃尽布局。
可以以 JSON 格式输出绘制绘图所需的所有信息。只需将.json附加到输出 ( -o ) 即可完成。数据格式未完全指定,取决于生成它的 Python 代码。每个 JSON 文件应包含反映绘图类型的"type" 。
--first-parent作为解决方法。hercules在“夫妇”模式下的 Linux 内核输出为 1.5 GB,需要一个多小时/180GB RAM 才能解析。然而,大多数存储库都会在一分钟内解析完毕。尝试使用 Protocol Buffers( hercules --pb和labours -f pb )。 # Debian, Ubuntu
apt install libyaml-dev
# macOS
brew install yaml-cpp libyaml
# you might need to re-install pyyaml for changes to make effect
pip uninstall pyyaml
pip --no-cache-dir install pyyaml
如果分析的存储库很大并且广泛使用分支,则燃尽统计信息收集可能会失败并出现 OOM。您应该尝试以下操作:
--skip-blacklist避免分析不需要的文件。也可以限制--language 。--hibernation-distance 10 --burndown-hibernation-threshold=1000 。使用这两个数字在 OOM 之前开始休眠。--burndown-hibernation-disk --burndown-hibernation-dir /path 。--first-parent ,你赢了。 src-d/go-git切换到go-git/go-git 。升级代码库以兼容最新的 Go 版本。 

