使用标签传播方法进行同义词库扩展的工具。它根据文本语料库和现有同义词库生成扩展现有同义词集的建议。该工具是在慕尼黑工业大学 (TUM) 的“商业信息系统软件工程 (sebis)”主席的硕士论文“税法同义词库扩展的标签传播”期间开发的。
论文摘要。随着数字化的兴起,信息检索必须应对越来越多的数字化内容。法律内容提供商投入大量资金来构建特定领域的本体(例如同义词库),以检索数量显着增加的相关文档。自 2002 年以来,已经开发了许多标签传播方法,例如用于识别图中相似节点的组。标签传播是一系列基于图的半监督机器学习算法。在本文中,我们将测试标签传播方法从税法领域扩展同义词库的适用性。标签传播操作的图是由词嵌入构建的相似图。我们从头到尾涵盖了整个过程,并进行了多项参数研究,以了解某些超参数对整体性能的影响。然后在手动研究中评估结果并与基线方法进行比较。
该工具是使用以下管道和过滤器架构实现的:
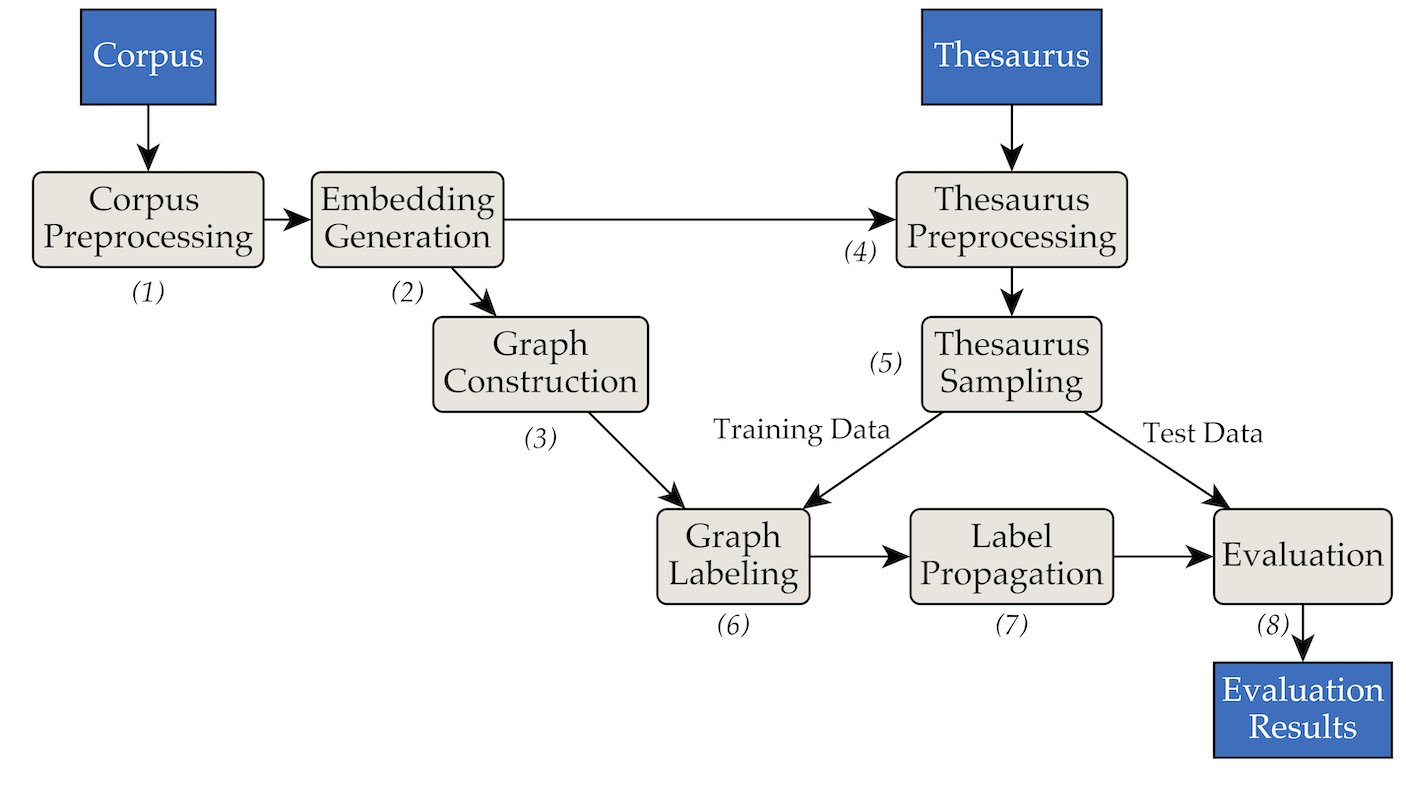
pipenv (安装指南)。pipenv install安装项目的要求。 data/RW40jsons中的一组文本语料库文件和data/german_relat_pretty-20180605.json中的同义词库。有关预期文件格式的信息,请参阅phase1.py 和phase4.py。output/<PHASE_FOLDER>/<DATE>中。最重要的是08_propagation_evaluation和XX_runs 。在08_propagation_evaluation中,评估统计数据存储为stats.json以及包含预测、训练和测试集的表( main.txt ,在其他脚本中最常称为df_evaluation )。在XX_runs中,存储了运行的日志。如果通过 multi_runs.py 触发多次运行(每次都有不同的训练/测试集),则所有单独运行的组合统计数据也会存储为all_stats.json 。 通过purew2v_parameter_studies.py,我们在论文中引入的synset向量基线可以被执行。它需要一组词嵌入和一个或多个同义词库训练/测试分割。有关示例,请参阅sample_commands.md。
在ipynbs中,我们提供了一些示例性的 Jupyter 笔记本,用于生成 (a) 统计数据、(b) 图表和 (c) 用于手动评估的 Excel 文件。您可以通过运行pipenv shell然后使用jupyter notebook启动 Jupyter 来探索它们。
main.py或multi_run.py时将构建路径指定为参数。

