邹阳、Jongheon Jeong、Latha Pemula、张冬青、Onkar Dabeer。
该存储库包含我们的 ECCV-2022 论文“SPot-the-Difference Self-Supervised Pre-training for Anomaly Inspection and Segmentation”的资源。目前我们发布了视觉异常(VisA)数据集。
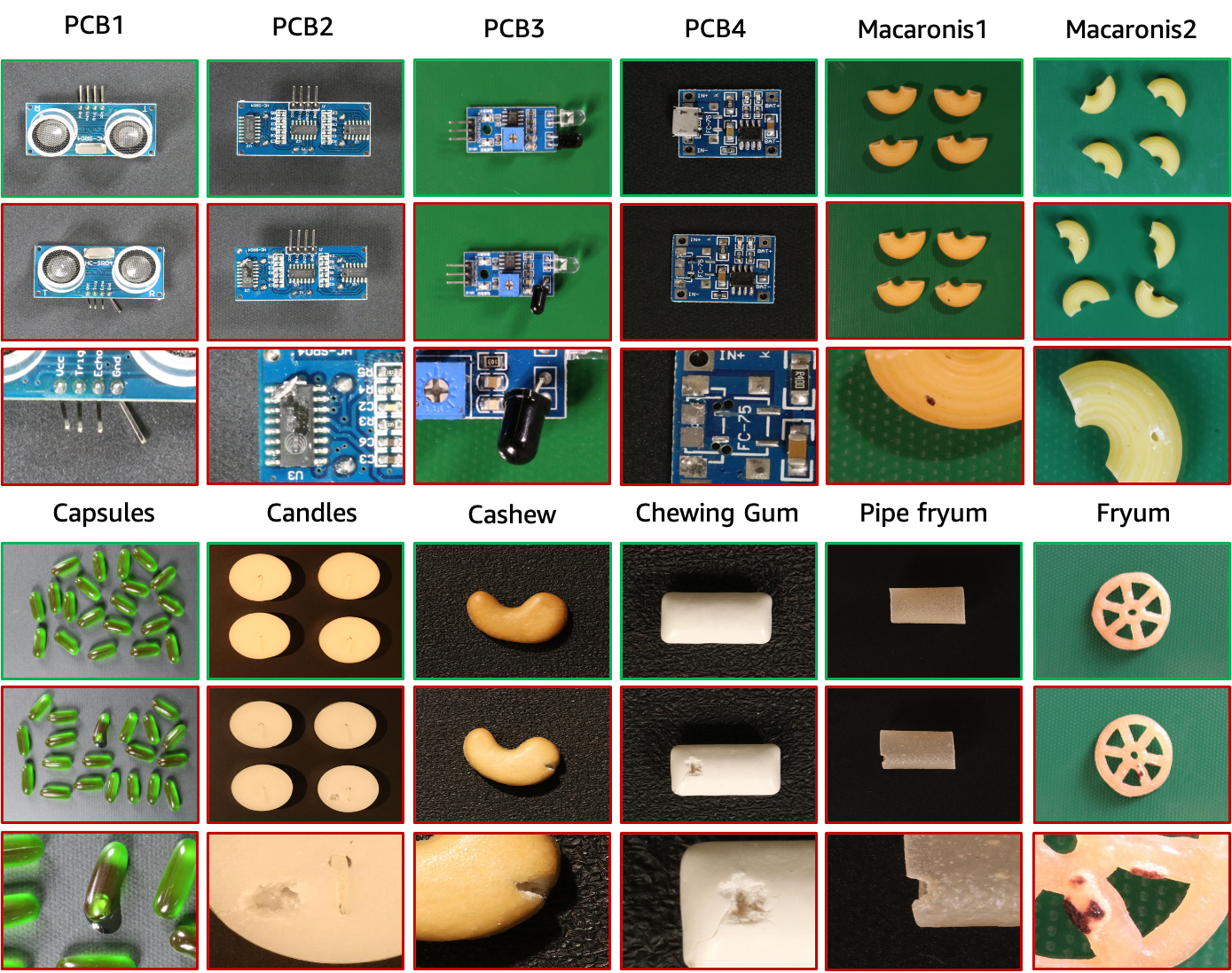
VisA数据集包含12个子集,对应12个不同的对象,如上图所示。有 10,821 张图像,其中 9,621 个正常样本和 1,200 个异常样本。四个子集是不同类型的印刷电路板(PCB),其结构相对复杂,包含晶体管、电容器、芯片等。对于视图中多个实例的情况,我们收集四个子集:Capsules、Candles、Macaroni1 和 Macaroni2。 Capsules 和 Macaroni2 中的实例在位置和姿势上有很大不同。此外,我们收集了四个子集,包括腰果、口香糖、炸薯条和管道炸薯条,其中对象大致对齐。异常图像包含各种缺陷,包括划痕、凹痕、色斑或裂纹等表面缺陷,以及错位或缺失部件等结构缺陷。
| 目的 | # 正常样本 | # 异常样本 | # 异常类 | 对象类型 |
|---|---|---|---|---|
| 印刷电路板1 | 1,004 | 100 | 4 | 结构复杂 |
| PCB2 | 1,001 | 100 | 4 | 结构复杂 |
| PCB3 | 1,006 | 100 | 4 | 结构复杂 |
| PCB4 | 1,005 | 100 | 7 | 结构复杂 |
| 胶囊 | 602 | 100 | 5 | 多个实例 |
| 蜡烛 | 1,000 | 100 | 8 | 多个实例 |
| 通心粉1 | 1,000 | 100 | 7 | 多个实例 |
| 通心粉2 | 1,000 | 100 | 7 | 多个实例 |
| 腰果 | 500 | 100 | 9 | 单实例 |
| 口香糖 | 503 | 100 | 6 | 单实例 |
| 弗留姆 | 500 | 100 | 8 | 单实例 |
| 管道弗里姆 | 500 | 100 | 9 | 单实例 |
我们将 VisA 数据集托管在 AWS S3 中,您可以通过此 URL 下载它。
下载数据的数据树如下。
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv 为每个图像提供图像级标签和像素级注释掩码。多类掩码的 id2class 映射函数可以在 ./utils/id2class.py 中找到,这里不存储普通图像的掩码以节省空间。
为了准备原始论文中描述的 1-class、2-class-highshot、2-class-fewshot 设置,我们使用 ./utils/prepare_data.py 按照“./split_csv/”中的数据分割文件重新组织数据。我们给出了用于 1 级设置准备的示例命令行,如下所示。
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
重组后的1级设置的数据树如下。
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...具体来说,1 级设置的重组数据遵循 MVTec-AD 的数据树。对于每个对象,数据具有三个文件夹:
请注意,原始数据集中的多类真实分割掩码被重新索引为二进制掩码,其中 0 表示正常,255 表示异常。
此外,可以通过更改prepare_data.py 的参数以类似的方式准备2 类设置。
要计算分类和分段指标,请参阅./utils/metrics.py。请注意,我们在计算本地化指标时考虑了正常样本。这与其他一些忽略本地化正常样本的作品不同。
如果该数据集对您的项目有帮助,请引用以下论文:
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}数据在 CC BY 4.0 许可下发布。


