该存储库包含 Motif 的 PyTorch 代码,使用源自法学硕士偏好的奖励函数在 NetHack 上训练 AI 代理。
主题:人工智能反馈的内在动机
作者:Martin Klissarov* 和 Pierluca D'Oro*、Shagun Sodhani、Roberta Raileanu、Pierre-Luc Bacon、Pascal Vincent、Amy Zhang 和 Mikael Henaff
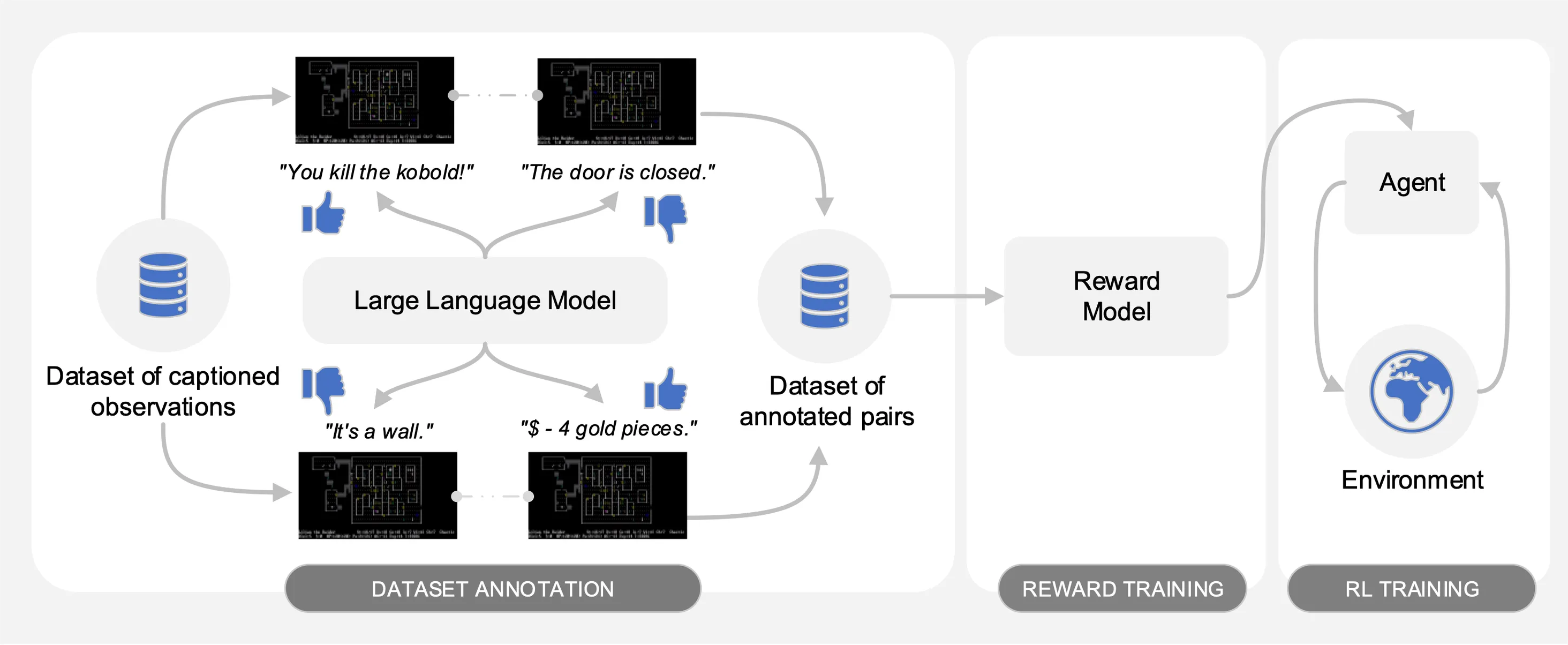
Motif 引出了大型语言模型 (LLM) 对来自 NetHack 上收集的交互数据集的带标题观察对的偏好。它会自动将法学硕士的常识提炼为奖励函数,用于通过强化学习来训练代理。
为了便于比较,我们在pickle文件motif_results.pkl中提供训练曲线,其中包含以任务为键的字典。对于每个任务,我们为多个种子提供了 Motif 和基线的时间步长和平均回报列表。
如下图所示,Motif 具有三个阶段:
我们通过提供必要的数据集、命令和原始结果来重现论文中的实验来详细介绍每个阶段。
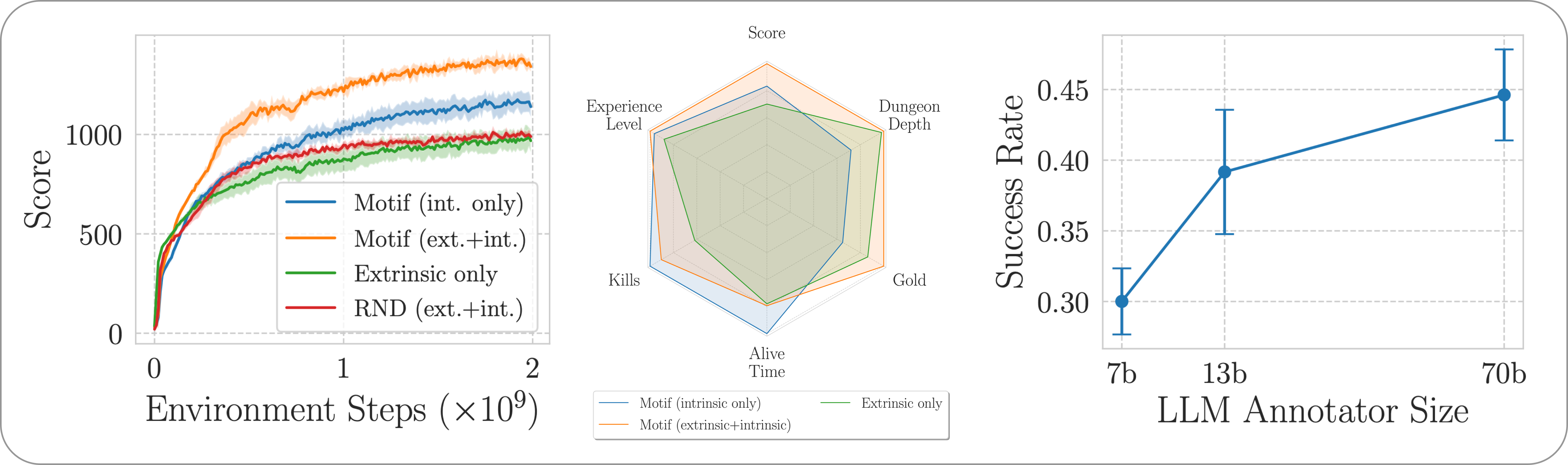
我们通过 NetHack 学习环境评估 Motif 在具有挑战性、开放式和程序生成的 NetHack 游戏中的表现。我们研究了 Motif 如何主要生成直观的人类行为(可以通过及时修改轻松控制)及其扩展属性。

要安装整个管道所需的依赖项,只需运行pip install -r requirements.txt 。
在第一阶段,我们使用由经过强化学习训练的代理收集的带标题(即来自游戏的消息)的观察对数据集,以最大化游戏分数。我们在此存储库中提供数据集。我们将不同的部分存储到motif_dataset_zipped目录中,可以使用以下命令解压缩。
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
我们提供的数据集包含 Llama 2 模型给出的一组偏好,包含在preference/目录中,使用论文中描述的不同提示。包含注释的.npy文件的名称遵循模板llama{size}b_msg_{instruction}_{version} ,其中size是集合{7,13,70}中的 LLM 大小, instruction是引入到从集合{defaultgoal, zeroknowledge, combat, gold, stairs}给 LLM 的提示, version是集合{default, reworded}中要使用的提示模板的版本。在这里,我们提供了可用注释的摘要:
| 注解 | 论文中的用例 |
|---|---|
llama70b_msg_defaultgoal_default | 主要实验 |
llama70b_msg_combat_default | 转向怪物杀手的行为 |
llama70b_msg_gold_default | 引导黄金收藏家的行为 |
llama70b_msg_stairs_default | 转向下降行为 |
llama7b_msg_defaultgoal_default | 缩放实验 |
llama13b_msg_defaultgoal_default | 缩放实验 |
llama70b_msg_zeroknowledge_default | 零知识提示实验 |
llama70b_msg_defaultgoal_reworded | 及时改写实验 |
为了创建注释,我们使用 vLLM 和 Llama 2 的聊天版本。如果您想使用 Llama 2 生成自己的注释或重现我们的注释过程,请确保能够按照官方说明下载模型(可以需要几天时间才能访问模型权重)。
注释脚本假设数据集将使用n-annotation-chunks参数以不同的块进行注释。这使得进程可以根据资源的可用性进行并行化,并且对于重新启动/抢占具有鲁棒性。要使用单个块运行(即处理整个数据集)并使用默认提示模板和任务规范进行注释,请运行以下命令。
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
请注意,默认行为通过将注释附加到指定配置的文件来恢复注释过程,除非使用--ignore-existing标志另有指示。还可以使用--custom-annotator-string标志手动选择为注释创建的“.npy”文件的名称。可以使用具有 32GB 内存的单个 GPU 使用--llm-size 7和--llm-size 13进行注释。您可以使用--llm-size 70和 8-GPU 节点进行注释。我们在这里提供了 NVIDIA V100s 32G GPU 对 10 万对数据集注释时间的粗略估计,这应该能够粗略地重现我们的大部分结果(使用 50 万对获得)。
| 模型 | 要注释的资源 |
|---|---|
| 骆驼 2 7b | 约 32 个 GPU 小时 |
| 骆驼 2 13b | 约 40 个 GPU 小时 |
| 骆驼 2 70b | 约 72 个 GPU 小时 |
在第二阶段,我们通过交叉熵将LLM的偏好提炼成奖励函数。要使用默认超参数启动奖励训练,请使用以下命令。
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
奖励函数将通过位于--dataset_dir中的annotator的注释进行训练。生成的函数将保存在子文件夹--experiment下的train_dir中。
最后,我们通过强化学习使用由此产生的奖励函数来训练代理。要在NetHackScore-v1任务上训练代理,并使用用于结合内在和外在奖励的实验的默认超参数,您可以使用以下命令。
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
要更改任务,只需修改--root_env参数即可。下表明确说明了与本文中提出的实验相匹配所需的值。 NetHackScore-v1任务的extrinsic_reward值为0.1 ,而所有其他任务的值为10.0 ,以激励智能体实现目标。
| 环境 | root_env |
|---|---|
| 分数 | NetHackScore-v1 |
| 楼梯 | NetHackStaircase-v1 |
| 楼梯(3层) | NetHackStaircaseLvl3-v1 |
| 楼梯(4层) | NetHackStaircaseLvl4-v1 |
| 甲骨文 | NetHackOracle-v1 |
| 神谕清醒 | NetHackOracleSober-v1 |
此外,如果您想仅使用来自 LLM 的内在奖励而不是来自环境的奖励来训练代理,只需设置--extrinsic_reward 0.0 。在仅内在奖励实验中,我们仅在智能体死亡时终止该情节,而不是在智能体达到目标时终止。下表列出了这些修改的环境。
| 环境 | root_env |
|---|---|
| 楼梯(第 3 层)- 仅内在 | NetHackStaircaseLvl3Continual-v1 |
| 楼梯(4 层)- 仅内在 | NetHackStaircaseLvl4Continual-v1 |
我们还提供了一个脚本,用于可视化经过训练的 RL 代理。这可以提供对其行为的重要见解,而且还将生成每个情节的重要消息,这可以帮助理解它正在尝试优化的内容。您只需运行以下命令即可。
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
如果您以我们的工作为基础或发现它有用,请使用以下 bibtex 引用它。
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Motif 的大部分内容均根据 CC-BY-NC 获得许可,但该项目的部分内容可根据单独的许可条款获得:sample-factory 根据 MIT 许可获得许可。


