
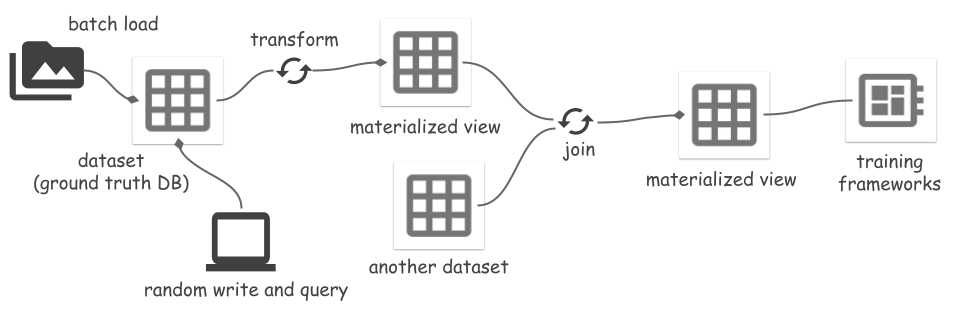
使用Space统一整个机器学习生命周期中的数据,Space 是一种全面的存储解决方案,可无缝处理从摄取到训练的数据。
主要特点:
space.core.schema.types.files )。space.TfFeatures是一种内置字段类型,基于 TFDS FeaturesDict,为 numpy 数组的嵌套字典提供序列化器。安装:
pip install space-datasets或者从代码安装:
cd python
pip install .[dev]请参阅设置和性能文档。
创建一个包含两个索引字段( id 、 image_name )(存储在 Parquet 中)和一个记录字段( feature )(存储在 ArrayRecord 中)的 Space 数据集。
此示例对记录字段使用纯binary类型。 Space 支持与 TFDS 特征序列化器集成的类型space.TfFeatures 。请参阅 TFDS 示例了解更多详细信息。
import pyarrow as pa
from space import Dataset
schema = pa . schema ([
( "id" , pa . int64 ()),
( "image_name" , pa . string ()),
( "feature" , pa . binary ())])
ds = Dataset . create (
"/path/to/<mybucket>/example_ds" ,
schema ,
primary_keys = [ "id" ],
record_fields = [ "feature" ]) # Store this field in ArrayRecord files
# Load the dataset from files later:
ds = Dataset . load ( "/path/to/<mybucket>/example_ds" )或者,您可以使用catalogs按名称而不是位置来管理数据集:
from space import DirCatalog
# DirCatalog manages datasets in a directory.
catalog = DirCatalog ( "/path/to/<mybucket>" )
# Same as the creation above.
ds = catalog . create_dataset ( "example_ds" , schema ,
primary_keys = [ "id" ], record_fields = [ "feature" ])
# Same as the load above.
ds = catalog . dataset ( "example_ds" )
# List all datasets and materialized views.
print ( catalog . datasets ())追加、删除一些数据。每个突变都会生成一个新版本的数据,由递增的整数 ID 表示。用户可以将标签添加到版本 ID 作为别名。
import pyarrow . compute as pc
from space import RayOptions
# Create a local runner:
runner = ds . local ()
# Or create a Ray runner:
runner = ds . ray ( ray_options = RayOptions ( max_parallelism = 8 ))
# To avoid https://github.com/ray-project/ray/issues/41333, wrap the runner
# with @ray.remote when running in a remote Ray cluster.
#
# @ray.remote
# def run():
# return runner.read_all()
#
# Appending data generates a new dataset version `snapshot_id=1`
# Write methods:
# - append(...): no primary key check.
# - insert(...): fail if primary key exists.
# - upsert(...): overwrite if primary key exists.
ids = range ( 100 )
runner . append ({
"id" : ids ,
"image_name" : [ f" { i } .jpg" for i in ids ],
"feature" : [ f"somedata { i } " . encode ( "utf-8" ) for i in ids ]
})
ds . add_tag ( "after_append" ) # Version management: add tag to snapshot
# Deletion generates a new version `snapshot_id=2`
runner . delete ( pc . field ( "id" ) == 1 )
ds . add_tag ( "after_delete" )
# Show all versions
ds . versions (). to_pandas ()
# >>>
# snapshot_id create_time tag_or_branch
# 0 2 2024-01-12 20:23:57+00:00 after_delete
# 1 1 2024-01-12 20:23:38+00:00 after_append
# 2 0 2024-01-12 20:22:51+00:00 None
# Read options:
# - filter_: optional, apply a filter (push down to reader).
# - fields: optional, field selection.
# - version: optional, snapshot_id or tag, time travel back to an old version.
# - batch_size: optional, output size.
runner . read_all (
filter_ = pc . field ( "image_name" ) == "2.jpg" ,
fields = [ "feature" ],
version = "after_add" # or snapshot ID `1`
)
# Read the changes between version 0 and 2.
for change in runner . diff ( 0 , "after_delete" ):
print ( change . change_type )
print ( change . data )
print ( "===============" )创建一个新分支并在新分支中进行更改:
# The default branch is "main"
ds . add_branch ( "dev" )
ds . set_current_branch ( "dev" )
# Make changes in the new branch, the main branch is not updated.
# Switch back to the main branch.
ds . set_current_branch ( "main" )Space 支持将数据集转换为视图,并将视图具体化为文件。变换包括:
当源数据集发生修改时,刷新物化视图会增量同步更改,从而节省计算和 IO 成本。请参阅“Segment Anything”示例中的更多详细信息。读取或刷新视图必须是Ray runner,因为它们是基于Ray变换实现的。
物化视图mv可以用作视图mv.view或数据集mv.dataset 。前者始终从源数据集的文件中读取数据并即时处理所有数据。后者直接从MV文件中读取处理后的数据,跳过处理数据。
# A sample transform UDF.
# Input is {"field_name": [values, ...], ...}
def modify_feature_udf ( batch ):
batch [ "feature" ] = [ d + b"123" for d in batch [ "feature" ]]
return batch
# Create a view and materialize it.
view = ds . map_batches (
fn = modify_feature_udf ,
output_schema = ds . schema ,
output_record_fields = [ "feature" ]
)
view_runner = view . ray ()
# Reading a view will read the source dataset and apply transforms on it.
# It processes all data using `modify_feature_udf` on the fly.
for d in view_runner . read ():
print ( d )
mv = view . materialize ( "/path/to/<mybucket>/example_mv" )
# Or use a catalog:
# mv = catalog.materialize("example_mv", view)
mv_runner = mv . ray ()
# Refresh the MV up to version tag `after_add` of the source.
mv_runner . refresh ( "after_add" , batch_size = 64 ) # Reading batch size
# Or, mv_runner.refresh() refresh to the latest version
# Use the MV runner instead of view runner to directly read from materialized
# view files, no data processing any more.
mv_runner . read_all ()请参阅“Segment Anything”示例中的完整示例。尚不支持创建连接结果的物化视图。
# If input is a materialized view, using `mv.dataset` instead of `mv.view`
# Only support 1 join key, it must be primary key of both left and right.
joined_view = mv_left . dataset . join ( mv_right . dataset , keys = [ "id" ])将 Space 存储与 ML 框架集成的方法有多种。 Space 提供了随机访问数据源用于读取 ArrayRecord 文件中的数据:
from space import RandomAccessDataSource
datasource = RandomAccessDataSource (
# <field-name>: <storage-location>, for reading data from ArrayRecord files.
{
"feature" : "/path/to/<mybucket>/example_mv" ,
},
# Don't auto deserialize data, because we store them as plain bytes.
deserialize = False )
len ( datasource )
datasource [ 2 ]数据集或视图也可以读取为 Ray 数据集:
ray_ds = ds . ray_dataset ()
ray_ds . take ( 2 )Parquet 文件中的数据可以作为 HuggingFace 数据集读取:
from datasets import load_dataset
huggingface_ds = load_dataset ( "parquet" , data_files = { "train" : ds . index_files ()})列出所有索引(Parquet)文件的文件路径:
ds . index_files ()
# Or show more statistics information of Parquet files.
ds . storage . index_manifest () # Accept filter and snapshot_id显示所有ArrayRecord文件的统计信息:
ds . storage . record_manifest () # Accept filter and snapshot_id 太空是一个正在积极开发的新项目。
?正在进行的任务:
这不是 Google 官方支持的产品。


