我经常使用同义词库,无论是在编写文档和自述文件的副本时,还是在编写命名变量和函数的代码时。
我曾经使用在线同义词库,尤其是 thesaurus.com,但我讨厌这种体验。尽管结果很有用并且组织得很好,但它们对键盘不友好并且导航速度很慢,尤其是当结果扩展到许多页面时。
所以我制作了自己的同义词库。我使用它的次数比使用 thesaurus.com 的次数还要多。它的功能较少,但访问速度要快得多,并且对创作过程的干扰较小。
在终端窗口中,键入th后跟一个单词。例如,要查找单词“注意力” :
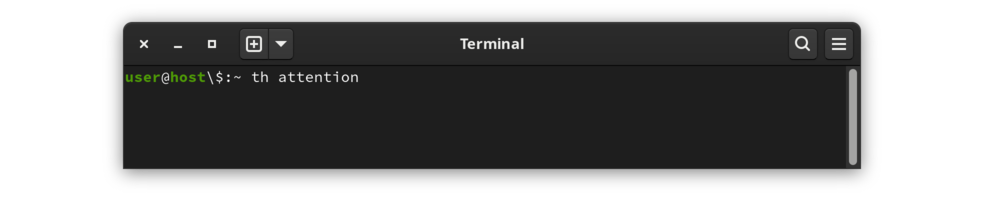 |
|---|
调用th来引起注意 |
输出是相关单词和短语的列表,组织成列,上面和下面有上下文行,底部有导航选项列表。
 |
|---|
| 关注搜索结果 |
结果显示的底行显示可用操作的列表。通过键入操作的第一个字母来启动操作(在屏幕上突出显示以进行强调)。
数据被组织为同义词库条目,每个词库条目都有相关单词和短语的集合。词条是主干,相关的词、短语是枝。
默认视图处于分支模式。显示的单词是源同义词库中条目后列出的单词和短语。切换到中继模式将显示包含该单词的条目。没有任何分支的示例最清楚地证明了这一点:
 |
|---|
| 触发器是一个没有条目的单词 |
没有单词trigger的同义词库条目。然而, “触发器”一词在同义词库中作为其他条目的分支。切换到中继模式以查看包含触发器的条目:
 |
|---|
| 触发器是相关词的词列表 |
该程序不作为软件包提供;必须下载源代码并构建项目。以下步骤将生成一个工作同义词库:
git clone https://www.github.com/cjungmann/th.gitcd thmakemake thesaurus.db尝试一下该程序,看看您是否喜欢它。如果您想将其安装为在构建目录之外可用,请调用以下命令:
sudo make install
如果您决定不需要该程序,则可以轻松删除该程序。
如果您已经安装了该程序,请先使用sudo make uninstall卸载
这将删除程序、支持文件以及安装支持文件的目录。
如果未安装该程序,您可以安全地删除克隆的目录。
以下材料主要会让开发人员(如果有的话)感兴趣。
该项目很容易构建,但依赖于其他软件。以下是依赖项列表,其中只有第一个(伯克利数据库)可能需要一些干预。下面的第 3 项和第 4 项被下载到构建目录下的子目录中,并且在那里找到的代码静态链接到可执行文件,因此它们不会影响您的环境。
db 版本 5 (伯克利数据库)对于项目中的 B 树数据库是必需的。如果你使用git ,你应该已经有了这个,即使在FreeBSD上,否则它只包含旧版本的db 。如果 Make 找不到合适的db ,它会立即终止并显示一条消息,在这种情况下,您可以使用包管理器来安装db或从源构建它。
git用于下载一些依赖项。虽然可以在不使用git 的情况下直接下载项目依赖项,但这样做需要有关源文件的未记录的知识,而当make可以使用git下载依赖项时,可以避免这个问题。
readargs 是我处理命令行参数的项目之一。虽然th仍在使用此项目,但th不再需要安装此库即可工作。现在,第一个Makefile 将readargs项目下载到子目录中,构建它并使用静态库。
c_patterns 是我的另一个项目,是一个在不需要库的情况下管理可重用代码的实验。 Makefile 使用git下载项目,然后链接到src目录中的一些 c_patterns 模块,以包含在构建中。
这个项目虽然有用(至少对我来说),但也是一个实验。我的目标之一是提高我的 makefile 编写技巧。我做出的一些构建和安装决策可能不是最佳实践,甚至可能会被更有经验的开发人员所反对。如果您担心th后会对您的系统产生什么影响,我希望以下内容能够帮助您做出决定。
正如预期的那样, make将编译第一个应用程序。与以往不同的是, make可能会执行其他可能需要一些时间的任务:
下载我的 C 模块存储库,并通过链接到src目录来使用其中的几个模块。
如果makefile检测到缺少依赖项,它会识别并立即终止并显示有用的消息,而不是使用configure来检查依赖项。
从古腾堡项目下载并导入公共领域莫比同义词库。这将填充应用程序的单词数据库。
已放弃下载并导入字数统计数据库。这个想法是提供替代的排序顺序,以便更轻松地从较长的列表中查找单词。现在这不起作用。我不确定我是否会回到这个话题,因为我发现阅读字母列表的好处远远超过尝试将更常用的单词放在第一位的可疑好处。原因是,当所考虑的单词不是随机分散在一长串单词中时,跟踪它们会更容易。
我刚刚注意到有一个 Moby 词性列表资源可以帮助组织输出。这很有趣,但根据字母排序对使用输出的帮助程度,我不确定它是否会有帮助。我们拭目以待。
当我开始这个项目时,我有几个目标。
我想要更多使用伯克利数据库的经验。这个密钥存储数据库支撑着许多其他应用程序,包括git和sqlite 。
我想练习使用我的一些 c_patterns 项目模块。在实际项目中使用这些模块可以帮助我了解它们的设计缺陷和缺失的功能。我用
columnize.c生成柱状输出,
提示器.c用于输出底部的最小选项菜单,
get_keypress.c用于非回显按键,主要由提示器.c使用。
我想练习设计一个可以在 Gnu Linux 和 BSD 中运行的构建过程。这包括识别缺失的模块(特别是db ,其中 BSD 包含一个太旧的库),以及重新设计的条件处理。
我不针对 Windows,因为它与 Linux 的差异比 BSD 更大,并且我不认为许多 Windows 用户会愿意使用命令行应用程序。
伯克利数据库( bdb )似乎是一个有趣的数据库产品。它的低级 C 库方法看起来类似于我在 20 世纪 90 年代末使用的 FairCom DB 引擎。
Berkeley 数据库很有吸引力,因为它是 Linux 和 BSD 发行版的一部分,并且占用空间很小。它奖励了对数据的详细规划,也是探索我的一些C语言想法的借口。
这个项目是我的单词项目的重新启动,该项目旨在成为一个命令行同义词库和词典。那个项目是我第一次使用bdb ,所以我的一些工作有点笨拙。我想从头开始重新设计bdb代码。我将从单词项目中复制一些适用于此处的文本解析代码。
使用同义词库和词典等大型数据集,我还想测试 Queue 和 Recno 数据访问方法之间的性能差异。我预计队列会更快,因为可以计算固定长度记录的开头和结尾。通过给定可变长度记录的记录号进行访问将需要查找文件位置。我想测量性能差异,以权衡该优势与可变长度记录的存储效率。
同义词库有两个公共领域来源:
我使用 Moby 同义词库,因为它的组织更简单,因此更容易解析。问题在于同义词数量众多,而且缺乏组织,在搜索合适的同义词时更难扫描。
由于许多单词有数百个同义词,因此很难扫描列表来找到合适的单词。我将尝试对列表进行一些排序以使其更易于使用。使用该工具一段时间后,我得出的结论是按字母顺序排列是最好的。返回到字母列表中的单词要容易得多。我删除了选择其他词序的选项。
最简单的分类是单词使用频率。我打算按照使用频率最高到最低的顺序列出单词。据推测,更流行的词可能是最好的选择,而不太流行的词可能是过时的。
词频有多种来源。我使用的是基于 Google ngrams 的:
自然语言语料库数据:美丽的数据
我还没有真正研究过 Norvig 的源码,所以它可能有很多废话。还有另一个来源可能有更干净的列表,hackerb9/gwordlist。如果 Norvig 是一个问题,我想记住这个备用列表,我可以用它来替换它。
这部分不再尝试。由于需要识别字典的独特符号并将其转换为 unicode 字符,解释源数据变得很复杂。我解决了其中许多问题,但仍有许多问题仍然存在。 Makefile 仍然包含下载此信息的说明,并且存储库保留了一些转换脚本,以备我想返回时使用。
按词性(即名词、动词、形容词等)对同义词进行分组也可能很有用。第一个问题是识别每个单词所代表的词性。第二个问题是在演示中:如果有一个界面让用户在显示单词之前选择词性,那就更好了,但更难编程。
电子公共领域词典
我的第一次尝试是使用 GNU 协作国际英语词典 (GCIDE)。它基于韦氏词典的旧版本(1914 年),并由更现代的编辑添加了一些文字。


