FlagEmbedding
1.3.2


新闻 |安装|快速入门 |社区 |项目 |型号列表 |贡献者 |引文|执照
英语 | 中文
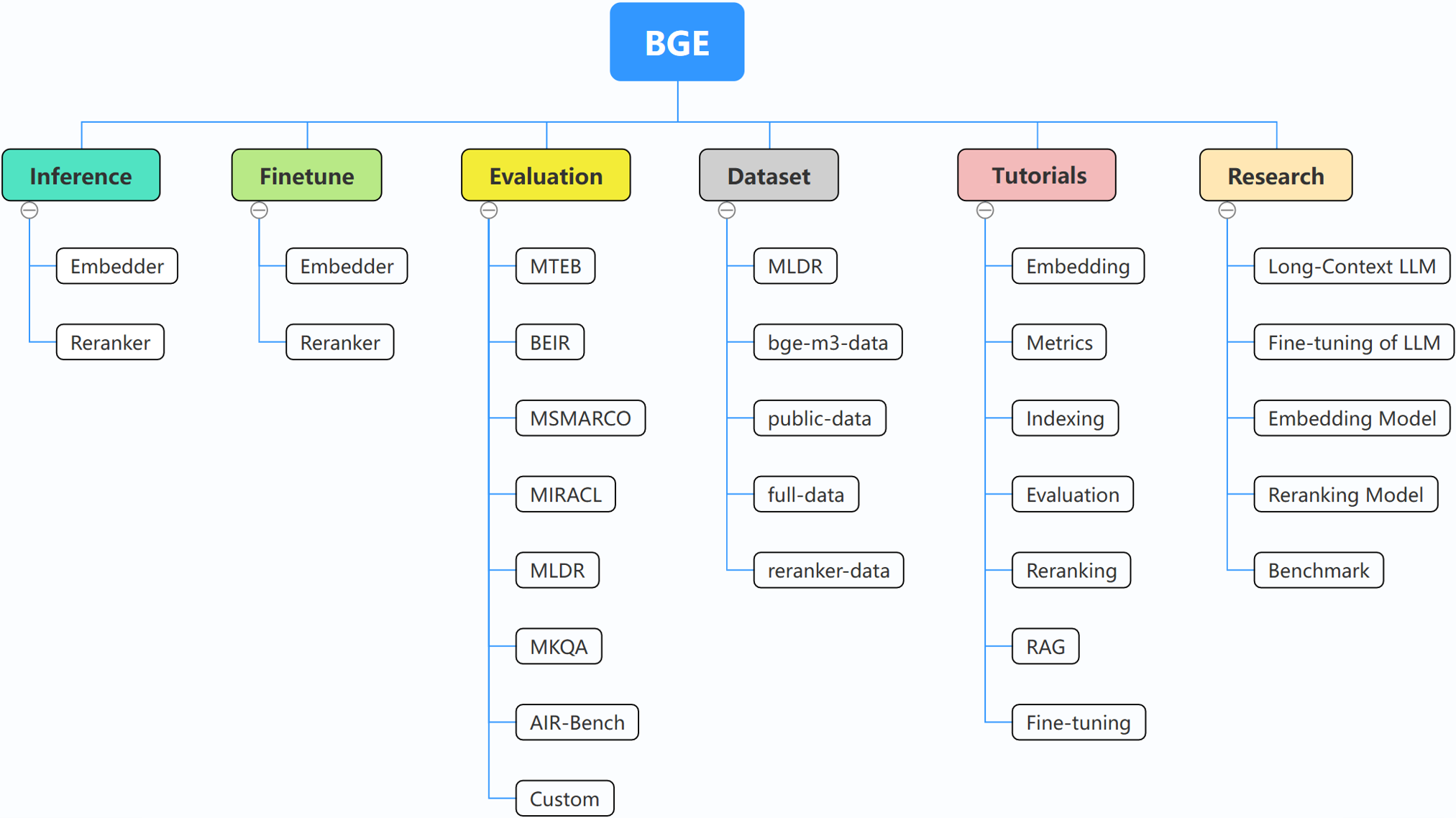
BGE(BAAI General Embedding)专注于检索增强法学硕士,目前包括以下项目:
2024 年 10 月 29 日:?我们为BGE创建了微信群。扫描二维码加入群聊!要获取有关我们的更新和新版本的第一手消息,或者有任何问题或想法,请立即加入我们!

2024年10月22日:我们发布了另一个有趣的模型:OmniGen,这是一个支持各种任务的统一图像生成模型。 OmniGen 可以完成复杂的图像生成任务,无需 ControlNet、IP-Adapter 等额外插件或姿势检测和人脸检测等辅助模型。
2024 年 9 月 10 日:引入MemoRAG ,这是在记忆启发的知识发现之上向 RAG 2.0 迈出的一步(存储库:https://github.com/qhjqhj00/MemoRAG,论文:https://arxiv.org/pdf/ 2409.05591v1)
2024年9月2日:开始维护教程。里面的内容将会积极更新和丰富,敬请期待!
7/26/2024:发布新的嵌入模型 bge-en-icl,这是一种融合了上下文学习功能的嵌入模型,通过提供与任务相关的查询响应示例,可以对语义更丰富的查询进行编码,进一步增强语义嵌入的表示能力。
7/26/2024:发布新的嵌入模型bge-multilingual-gemma2,这是一个基于gemma-2-9b的多语言嵌入模型,支持多种语言和多样化的下游任务,在多语言基准(MIRACL、MTEB-fr)上实现新的SOTA和 MTEB-pl)。
7/26/2024:发布新的轻量级重排序器bge-reranker-v2.5-gemma2-lightweight,基于gemma-2-9b的轻量级重排序器,支持token压缩和分层轻量级操作,在节省资源的同时仍能保证良好的性能大量的资源。
BAAI/bge-reranker-base和BAAI/bge-reranker-large ,它们比嵌入模型更强大。我们建议使用/微调它们来重新排名嵌入模型返回的前 k 个文档。bge-*-v1.5嵌入模型,缓解相似度分布问题,增强无指令检索能力。bge-large-* (BAAI General Embedding的缩写)模型,在MTEB和C-MTEB基准测试中排名第一! ? ?如果您不想微调模型,可以安装不带finetune依赖项的包:
pip install -U FlagEmbedding
如果你想微调模型,可以安装带有finetune依赖项的包:
pip install -U FlagEmbedding[finetune]
克隆存储库并安装
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
对于可编辑模式下的开发:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
首先,加载 BGE 嵌入模型之一:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
然后,向模型输入一些句子并获取它们的嵌入:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
一旦我们获得嵌入,我们就可以通过内积计算相似度:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
更多详细信息,您可以参考 embedder inference、reranker inference、embedderfinetune、rerankerfintune、evaluation。
如果您不熟悉任何相关概念,请查看教程。如果不存在,请告诉我们。
有关 BGE 的更多有趣主题,请查看研究。
我们正在积极维护 BGE 和 FlagEmbedding 的社区。如果您有任何建议或想法,请告诉我们!
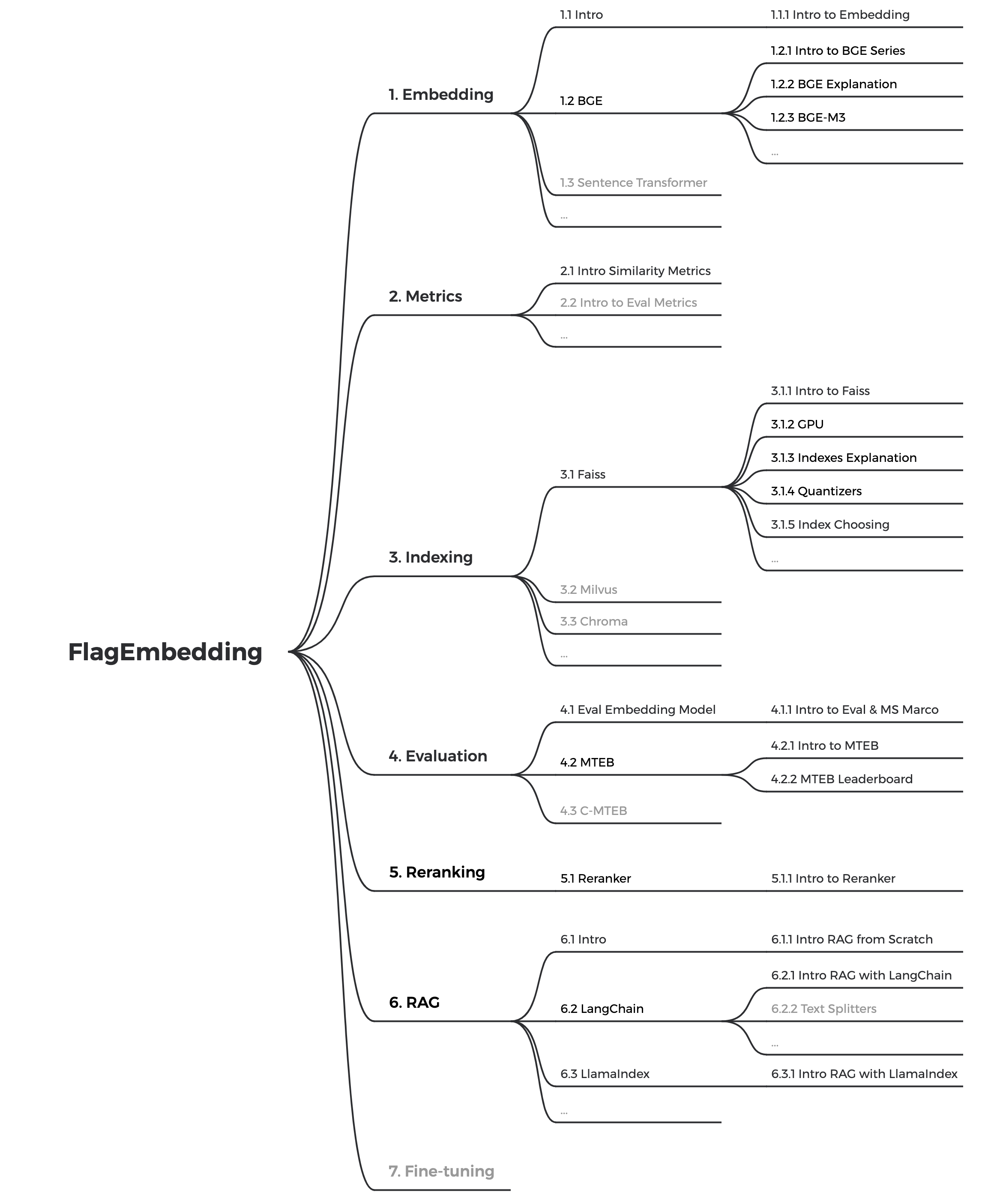
目前我们正在更新教程,我们的目标是为文本检索和 RAG 的初学者创建一个全面而详细的教程。敬请关注!
以下内容将在未来几周内发布:
bge是BAAI general embedding的缩写。
| 模型 | 语言 | 描述 | 检索查询指令 |
|---|---|---|---|
| BAAI/bge-en-icl | 英语 | 基于LLM的嵌入模型,具有上下文学习功能,可以根据几个镜头示例充分发挥模型的潜力 | 根据给定的任务免费提供说明和少量示例。 |
| BAAI/bge-多语言-gemma2 | 多种语言 | 基于法学硕士的多语言嵌入模型,经过多种语言和任务的训练。 | 根据给定的任务提供说明。 |
| BAAI/bge-m3 | 多种语言 | 多功能(密集检索、稀疏检索、多向量(colbert))、多语言和多粒度(8192 个标记) | |
| LM-鸡尾酒 | 英语 | 微调模型(Llama 和 BGE),可用于重现 LM-Cocktail 的结果 | |
| BAAI/llm-包埋机 | 英语 | 统一的嵌入模型,支持法学硕士的不同检索增强需求 | 请参阅自述文件 |
| BAAI/bge-reranker-v2-m3 | 多种语言 | 轻量级的交叉编码器模型,具有强大的多语言能力,易于部署,推理速度快。 | |
| BAAI/bge-reranker-v2-gemma | 多种语言 | 适合多语言环境的交叉编码器模型,在英语水平和多语言能力方面都表现良好。 | |
| BAAI/bge-reranker-v2-minicpm-layerwise | 多种语言 | 适合多语言环境的交叉编码器模型,在中英文水平上表现良好,允许自由选择输出层,有利于加速推理。 | |
| BAAI/bge-reranker-v2.5-gemma2-lightweight | 多种语言 | 适合多语言环境的交叉编码器模型,中英文均表现良好,可以自由选择层数、压缩比和输出压缩层数,有利于加速推理。 | |
| BAAI/bge-reranker-large | 中文和英文 | 更准确但效率较低的交叉编码器模型 | |
| BAAI/bge-reranker-base | 中文和英文 | 更准确但效率较低的交叉编码器模型 | |
| BAAI/bge-large-en-v1.5 | 英语 | 1.5版本,相似度分布更合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | 英语 | 1.5版本,相似度分布更合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | 英语 | 1.5版本,相似度分布更合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | 中国人 | 1.5版本,相似度分布更合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | 中国人 | 1.5版本,相似度分布更合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | 中国人 | 1.5版本,相似度分布更合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | 英语 | 将文本映射到向量的嵌入模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | 英语 | 基本比例模型,但具有与bge-large-en类似的能力 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | 英语 | 模型规模虽小,但性能具有竞争力 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | 中国人 | 将文本映射到向量的嵌入模型 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | 中国人 | 基本比例模型,但具有与bge-large-zh类似的能力 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-小-zh | 中国人 | 模型规模虽小,但性能具有竞争力 | 为这个句子生成表示以用于检索相关文章: |
感谢所有贡献者的努力,并热烈欢迎新成员的加入!
如果您发现此存储库有用,请考虑给予星号和引用
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding 根据 MIT 许可证获得许可。


