地铁管理系统
南科大2024年春季CS307 - Principles of Database System马育新主讲
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
项目的第一部分主要是根据所提供的数据背景,设计一个满足关系数据库原理的数据库模式。设计阶段完成后,我们编写脚本来导入这些大型数据集。为了保证导入数据的准确性,我们需要执行一些查询语句,并在防御日检查查询结果。除此之外,我们还对数据进行了一些实验,以获得一些精彩的见解,如下所示。
[阅读详细要求]
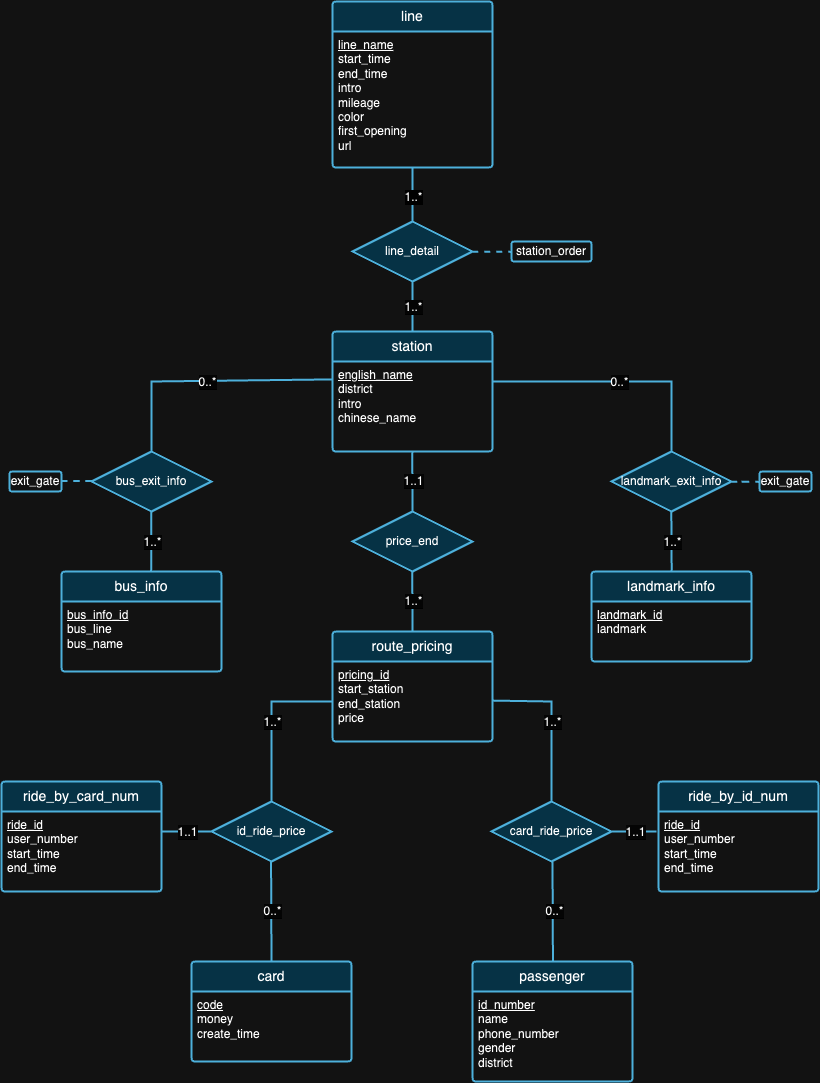
我们相信没有数据库设计是完美的。事实上,我们在上面的ER图中提出的设计是有缺陷的。在查看了数据集和每个数据集的背景之后,我们希望您能够尝试自己发现设计缺陷! :)
注:对于图形解释,
| ID | 操作系统 | 芯片 | 记忆 | 固态硬盘 | 工具 |
|---|---|---|---|---|---|
| 1 | macOS 索诺玛 14.4.1 | 苹果M3 Pro | 18GB | 1TB | IDEA 2024.1(CE)、PyCharm 2023.3.4(CE)、Datagrip 2024.1 |
| 2 | Windows 11 家庭版 23H2 | 第 12 代英特尔(R) 酷睿(TM) i9-12900H | 32GB | 1TB | IDEA 2024.1(CE)、Datagrip 2024.1 |
| 3 | Ubuntu 22.04.4(虚拟机) | 苹果M1 Pro | 16 GB | 512GB | IDEA 2024.1(CE)、Datagrip 2024.1 |
Experiment 1: Different Import Methods方法1(原始脚本):该方法利用java.sql库。首先,我们建立了与 PostgreSQL 服务器的连接。然后我们从 JSON 文件中读取所有数据。接下来,我们迭代每个数据并为每个插入语句创建PreparedStatement 。最后,我们调用executeUpdate()方法来单独执行每个语句。
方法2(优化脚本):该方法同样利用了java.sql库,并且采用与方法1相同的数据读取算法。不同的是现在我们使用了executeBatch()方法。因此,我们迭代整个数据,使用PreparedStatement创建每个插入语句,并将每个PreparedStatement添加到一个批次中以进行批量执行。
方法三(运行.sql文件):我们使用Java程序生成SQL插入语句,并采用与上述相同的数据读取算法将其写入.sql文件。然后我们在 DataGrip 中运行该文件。
由于我们在所有三种方法中使用相同的数据读取算法,因此我们将使用平均运行时间进行后续测试。我们最初收集了三种不同的运行时间——504 毫秒、546 毫秒和 552 毫秒——并计算出平均运行时间为 534 毫秒。
| 测试环境 | 方法 | 平均读取时间(毫秒) | 写入时间(毫秒) | 总时间(毫秒) | 吞吐量(语句/秒) |
|---|---|---|---|---|---|
| 1 | 1 | 第534章 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 第534章 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 第534章 | 13581 | 14115 | 15197.41 |
表 2 说明了不同方法的不同性能指标,其中方法 2 显示了最高的吞吐量,而方法 1 的总时间最慢。这使得方法 2 成为即将进行的实验中的标准测试方法。
Experiment 2: Data Import with Different Data Volumes管理和导入不同数量的数据是确保数据库系统的性能、可扩展性和可靠性的关键方面。
在导入过程之前,我们注意到“乘车”数据的数量明显大于其他数据。基于这个想法,我们决定仅在ride.json上测试不同卷的数据导入。由于数据权重不一致,因此为其他表导入较少的数据量可能会因表之间的连接性而导致严重问题。
最初,我们首先导入除rides_by_id_num和rides_by_card_num表之外的所有其他表的完整数据(100%体积),以确保我们设计的一致性。为了有效管理这一点,我们对ride数据采用了分阶段导入策略,从 20% 的数据子集开始,相当于 20,000 条记录。这个初始阶段使我们能够评估对系统性能的影响,并对导入过程进行必要的调整,而不会影响数据库的稳定性。经过成功的验证和性能调整后,我们继续导入 50% 的数据,最后导入剩余部分以完成 100% 的数据导入。请注意,我们对所有导入都使用方法 2,因为它是最快的。
| 测试环境 | 方法 | 体积 | 读取时间(毫秒) | 写入时间(毫秒) | 总时间(毫秒) | 语句计数 | 吞吐量(语句/秒) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 第521章 | 1338 | 1859年 | 130849 | 97794.47 |
| 1 | 2 | 100% | 第534章 | 2114 | 2648 | 203502 | 96263.95 |
从表3可以看出,随着数据量的增加(从20%到50%再到100%),读取和写入时间都会增加,导致操作的总时间更长。然而,这些数字并没有给出任何有洞察力的意义,因为我们的进口量不同。如果我们看吞吐量的数量,吞吐量(语句/秒)随着数据量的增加而逐渐下降,这表明随着工作负载的增加,系统处理语句的效率降低。
Experiment 3: Data Import on Different Operating Systems在测试不同操作系统导入数据的过程中,我们采用了最快的导入方法,即方法二,导入量为100%。
请注意,通过虚拟机在Linux上运行Java导入脚本时,必须考虑性能和资源分配上的不公平劣势,因为虚拟化会引入开销并影响系统的效率。
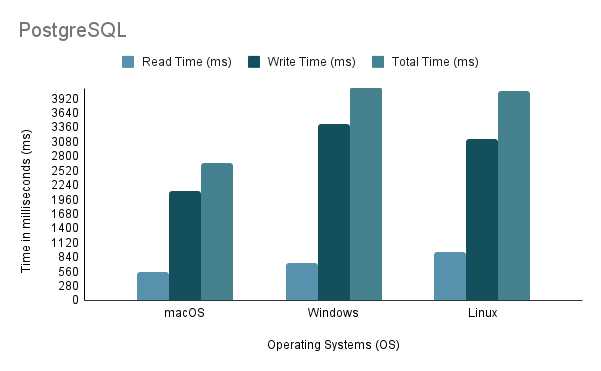
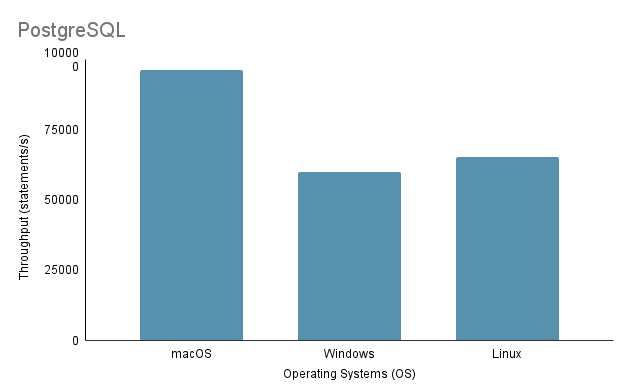
根据上述分析,很明显,环境 1 (macOS) 显示出最佳性能,总时间最短为 2648 毫秒,吞吐量最高为 97,632.92 条语句/秒。相比之下,环境 2 (Windows) 最慢,总时间为 4117 毫秒,吞吐量最低为 60,669.02 条语句/秒。值得注意的是,Linux Ubuntu 虽然作为虚拟机运行,但性能仍然优于裸机 Windows。
Experiment 4: Data Import with Various Programming Languages在这个实验中,我们对 Java 代码使用了上面提到的方法 2,因为它是最快的。同时,对于Python,我们编写了一个导入方法,利用Psycopg2与PostgreSQL数据库服务器进行通信。
| 测试环境 | 编程语言 | 读取时间(毫秒) | 写入时间(毫秒) | 总时间(毫秒) | 吞吐量(语句/秒) |
|---|---|---|---|---|---|
| 1 | 爪哇 | 第534章 | 2114 | 2648 | 96263.95 |
| 1 | Python | 390 | 7237 | 7627 | 28119.66 |
表4的数据显示,Java在速度和吞吐量方面均优于Python,表明其读写操作的效率更高。
Experiment 5: Data Import on Different Databases我们为 PostgreSQL 和 MySQL 开发了三种不同的导入方法,但我们只对方法 2 进行了实验,因为它是开发人员导入数据的选择。 PostgreSQL 和 MySQL 都有相似的数据库实现设计(DDL 方面)和相似的导入代码设计。
| 测试环境 | 方法 | 数据库 | 读取时间(毫秒) | 写入时间(毫秒) | 总时间(毫秒) | 吞吐量(语句/秒) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 第534章 | 2114 | 2648 | 96263.95 |
| 1 | 2 | MySQL | 第534章 | 42315 | 42849 | 4809.22 |
尽管两者都是基于 SQL 的数据库,但 PostgreSQL 在写入时间方面快了大约 16 倍。这可能是由于数据库引擎架构和驱动程序实现的差异造成的( postgresql-42.2.5.jar ,MySQL 为mysql-connector-j-8.3.0.jar )。
该项目的第 2 部分重点是通过构建公开一组应用程序编程接口 (API) 的后端库来提供访问数据库系统的基本功能。请注意,还需要导入一个额外的数据集,因此需要更新的数据库实现(可以在./Project2/DataImport中找到)。
[阅读详细要求]
./Project2/DataImport/src/main/sql/ddl.sql中提供的 DDL 设置 MySQL 数据库./Project2/DataImport/src/main/java/ImportScript.java中提供的脚本导入数据./Project2/ShenzhenMetro )(推荐使用 IntelliJ IDEA IDE)

