chrono_lens
v1.1.1
这是国家统计局数据科学校园博客上发布的交通摄像头分析项目的公共存储库,作为 ONS 冠状病毒更快指标的一部分(例如 - 交通摄像头活动 - 2020 年 9 月 10 日)和基本方法。该项目利用 Google 计算平台 (GCP) 来实现可扩展的解决方案,但底层方法与平台无关;该存储库包含我们面向 GCP 的实现。
下面介绍了为冠状病毒更快指标生成的示例输出。
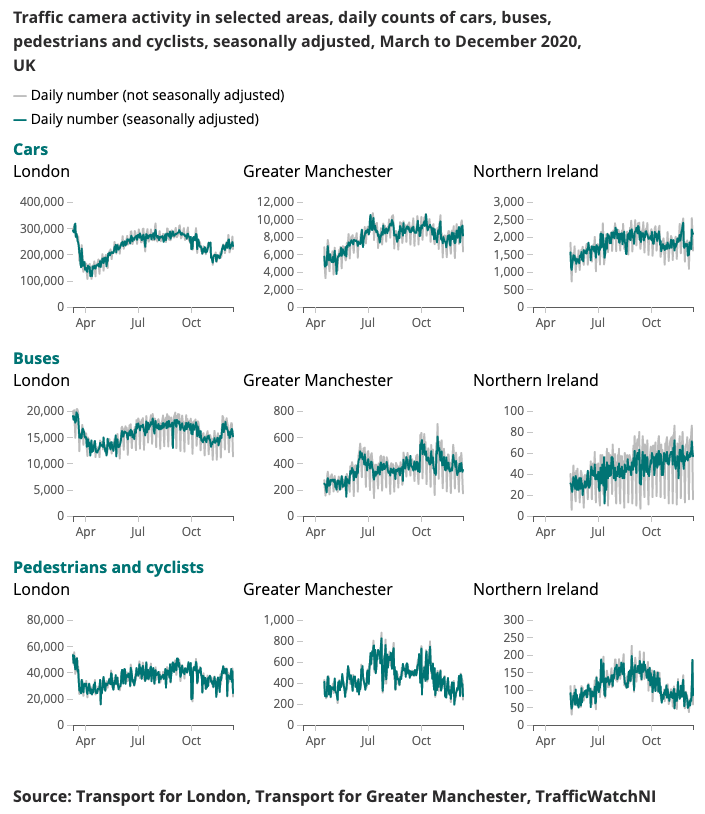
实时了解移动和行为模式的变化一直是政府应对冠状病毒 (COVID-19) 的主要重点。数据科学校园一直在探索替代数据源,这些数据源可能会提供有关如何估计社交距离水平的见解,并随着封锁条件的放松跟踪社会和经济的好转。
交通摄像头是一种广泛公开的数据源,允许交通专业人士和公众通过互联网评估全国不同地区的交通流量。交通摄像头生成的图像是公开的、低分辨率的,并且不允许单独识别人员或车辆。它们不同于用于公共安全和执法的自动车牌识别 (ANPR) 或监控交通速度的闭路电视。
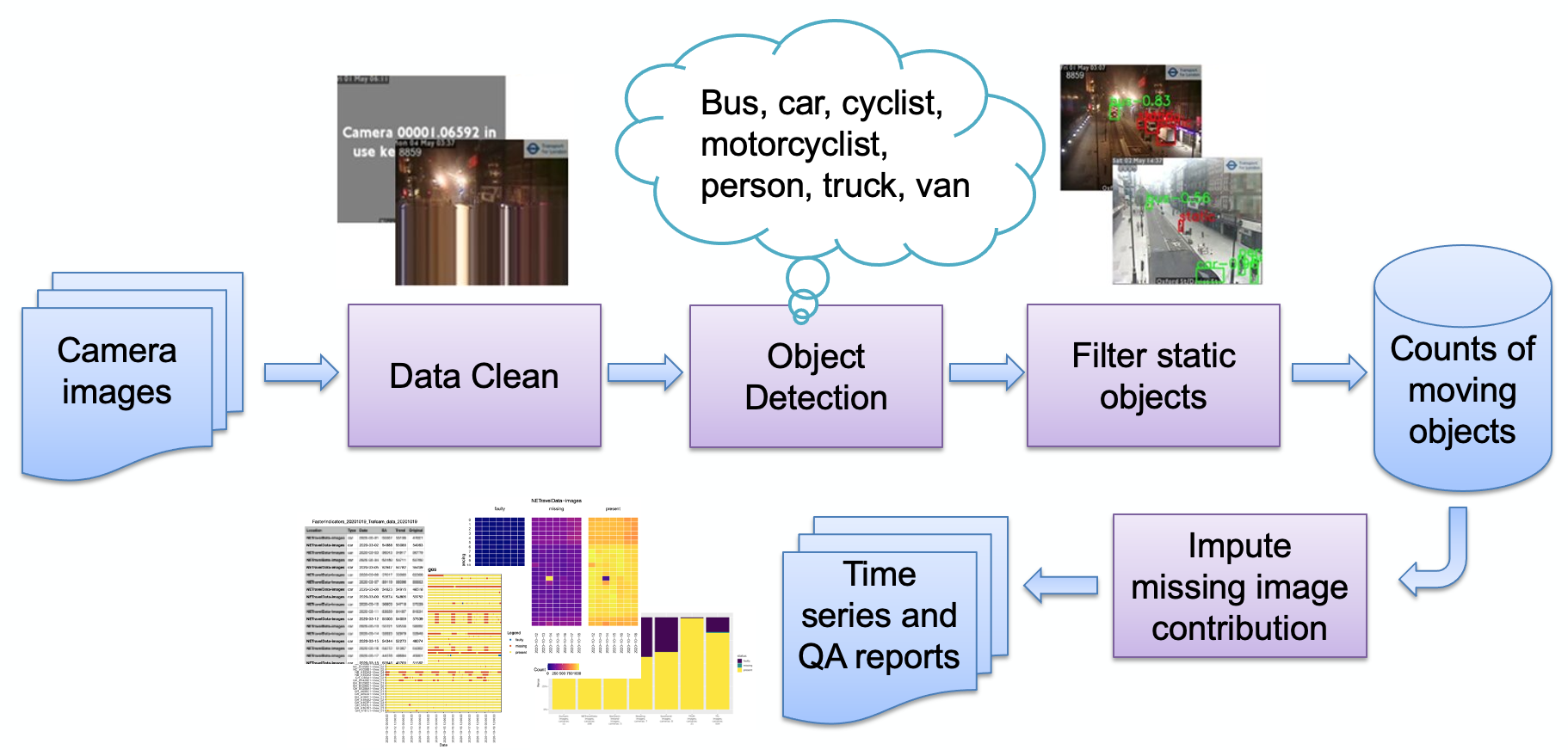
如图所示,管道的主要阶段是:
图像摄取
图像检测错误
物体检测
静态物体检测
存储结果计数
然后可以进一步处理计数(季节性调整、缺失值插补)并根据需要转换为报告。我们将简要回顾一下主要的管道阶段。
用户选择一组相机源(Web 托管的 JPEG 图像),并将其作为 URL 列表提供给用户。提供的示例代码用于从伦敦交通局获取公共图像,以及直接从纽卡斯尔大学城市观测站提取 NE 交通数据的专业代码。
相机可能因各种原因而无法使用(系统故障、本地操作员禁用馈送等),这些可能导致模型生成虚假对象计数(例如,小斑点可能看起来像远处的公共汽车)。此类图像的示例是: 
到目前为止,这些图像都遵循非常合成的图像模式,由平坦的背景颜色和覆盖的文本组成(与自然场景的图像相比)。目前,这些图像的检测方法是降低颜色深度(将相似的颜色对齐在一起),然后查看图像中单一颜色占据的最高部分。一旦超过阈值,我们就确定该图像是合成的并将其标记为有缺陷的。由于编码可能会出现其他错误,例如: 
此处,camrera 馈送已停止,最后一个“实时”行已重复;我们通过检查图像的底行是否与上面的行匹配(在阈值内)来检测这一点。如果是这样,则检查上面的下一行是否匹配,依此类推,直到行不再匹配或我们用完行。如果匹配行的数量高于阈值,则图像不太可能生成有用的数据,因此被标记为有缺陷。
请注意,不同的图像提供商使用不同的方式来显示相机不可用;我们的检测技术依赖于使用的少量颜色 - 即纯合成图像。如果使用更自然的图像,我们的技术可能不起作用。另一种方法是保留失败图像的“库”并寻找相似性,这对于更自然的图像可能效果更好。
对象检测过程使用纽卡斯尔大学城市天文台提供的预先训练的 Faster-RCNN 来识别静态和移动对象。该模型已使用英格兰东北部的 10,000 个交通摄像头图像进行了训练,并由 ONS 数据科学园区进一步验证,以确认该模型可用于英国其他地区的摄像头图像。它检测以下对象类型:汽车、货车、卡车、公共汽车、行人、骑自行车者、摩托车手。
由于我们的目标是检测活动,因此使用时间信息过滤掉静态对象非常重要。图像每隔 10 分钟采样一次,因此传统的视频背景检测方法(例如高斯混合)并不适用。
在对象检测过程中分类的任何行人和车辆都将被设置为静态,并且如果它们也出现在背景中,则将从最终计数中删除。下图显示了静态遮罩的示例结果,其中图像 (a) 中停放的汽车被识别为静态并被移除。另一个好处是静电面罩可以帮助消除误报。例如,在图像(b)中,垃圾箱在对象检测中被误识别为行人,但被过滤为静态背景。

结果简单地存储为表格,模式记录摄像机 ID、日期、时间、每个对象类型(汽车、货车、行人等)的相关计数(如果图像有问题或图像丢失)。
最初,该系统被设计为云原生,以实现可扩展性;然而,这引入了进入障碍 - 您需要拥有云提供商的帐户,知道如何保护基础设施等。考虑到这一点,我们还向后移植了代码以在独立计算机上工作(或“本地主机”),使感兴趣的用户能够在自己的笔记本电脑上简单地运行系统。下面描述这两种实现方式。
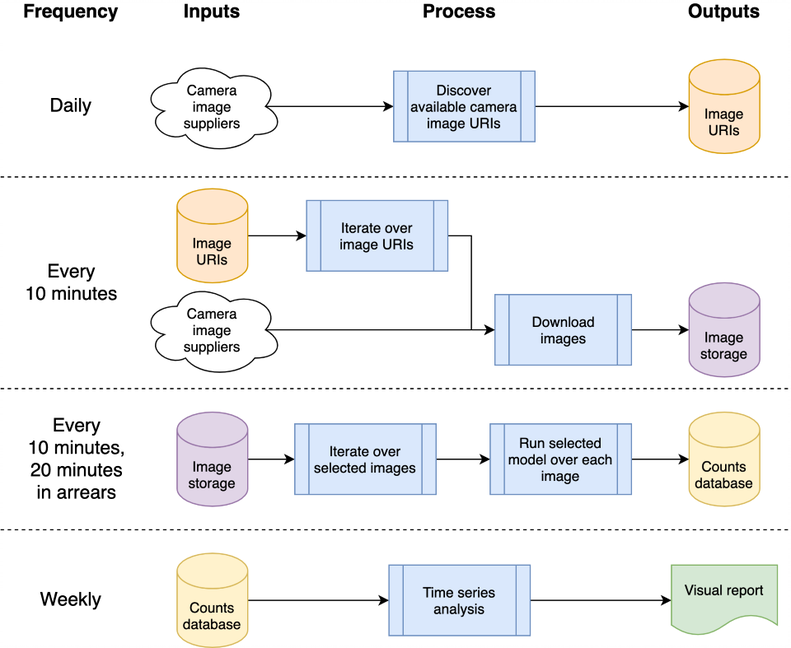
该架构可以映射到单机或者云系统;我们选择使用谷歌计算平台(GCP),但其他平台,如亚马逊网络服务(AWS)或微软的Azure将提供相对等效的服务。
该系统以“云函数”的形式托管,它们是独立的无状态代码,可以重复调用而不会导致损坏——这是提高函数稳健性的一个关键考虑因素。使用 GCP 的调度程序来编排每日和“每 10 分钟”的处理突发,以根据所需的时间表触发 GCP Pub/Sub 主题。 GCP 云函数针对主题注册,并在触发主题时启动。
处理图像以检测车辆和行人会导致对象计数写入数据库,以便以后作为时间序列进行分析。数据库用于数据采集和时间序列分析之间共享数据,减少耦合。我们在 GCP 中使用 BigQuery 作为数据库,因为它在其他 GCP 产品中得到了广泛支持,例如用于数据可视化的 Data Studio;本地主机实现会存储每日 CSV 进行比较,以消除对特定数据库或其他基础设施的任何依赖。
GCP相关源码存放在cloud文件夹中;它会下载图像,对其进行处理以对对象进行计数,将计数存储在数据库中并(每周)生成时间序列分析。所有文档和源代码都存储在cloud文件夹中;请参阅 Cloud README.md,了解架构概述以及如何使用我们的脚本将您自己的实例安装到您的 GCP 项目空间中。该项目可以集成到GitHub中,实现自动部署和自动测试执行,从提交到本地GitHub项目;这也记录在 Cloud README.md 中。云支持代码也存储在chrono_lens.gcloud模块中,使命令行脚本能够支持 GCP,以及cloud文件夹中的云函数代码。
独立的单机(“localhost”)代码包含在chrono_lens.localhost模块中。该过程遵循与 GCP 变体相同的流程,尽管使用单台机器,并且chrono_lens.localhost中的每个 python 文件都映射到 GCP 的云功能。有关更多详细信息,请参阅 README-localhost.md。
鉴于 GCP 和本地主机实现至少需要一些本地安装,我们现在描述安装系统的各个步骤和先决条件。
强烈建议创建虚拟环境,以提供隔离的工作环境。良好工作环境的示例包括 conda、pyenv 和 poerty。
请注意,依赖项已包含在requirements.txt中,因此请通过pip安装:
pip install -r requirements.txt
为了防止意外提交密码,建议使用预提交挂钩,以防止在敏感信息到达存储库之前处理 git 提交。我们使用了 https://github.com/ukgovdatascience/govcookiecutter 中的预提交挂钩
安装requirements.txt将安装预提交工具,现在需要连接到git:
pre-commit install
...然后将从.pre-commit-config.yaml中提取配置。
注意,在添加 RCNN 模型文件/tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb fig_frcnn_rebuscov-3.pb 时, check-added-large-files预提交测试的.pre-commit-config.yaml中的最大 kB 大小暂时增加到 60Mb 。然后该限制将恢复为 5Mb 作为合理的“正常”上限。
建议在继续之前对所有文件进行扫描,以确保没有任何文件被错误地存在:
pre-commit run --all-files
这将报告任何现有问题 - 很有用,因为挂钩仅在编辑的文件上运行。
该项目设计主要通过云基础设施使用,但也有用于本地访问和更新云中时间序列的实用程序脚本。这些脚本位于scripts/gcloud文件夹中,每个脚本现在在单独的以下部分中进行描述。更多信息可以在scripts/gcloud/README.md中找到,并且可选虚拟机对它们的使用在cloud/README.md中进行了描述。
scripts/localhost文件夹中的脚本支持非云使用, README-localhost.md中描述了如何在独立计算机上使用chrono_lens系统的详细信息。有关使用脚本的更多信息可以在scripts/localhost/README.md中找到。
请注意,脚本使用chrono_lens文件夹中的代码。
| 版本 | 日期 | 笔记 |
|---|---|---|
| 1.0.0 | 2021-06-08 | 公共存储库的首次发布 |
| 1.0.1 | 2021-09-21 | 修复了孤立图像、tensorflow 版本凹凸的错误 |
| 1.1.0 | ? | 增加了对单机单机的有限支持 |
这里介绍了未来潜在的工作领域;这些变化可能不会被调查,但目的是让人们意识到我们考虑过的潜在改进。
目前,bash shell脚本用于创建GCP基础设施;改进方法是使用 IaC,例如 Terraform。这简化了(例如)云功能配置的更改,而无需在运行时环境或内存限制更改时手动删除云构建触发器并重新创建它。
当前的设计源于其在模型最终确定之前获取图像的初始用例,因此所有可用图像都会被下载,而不仅仅是那些被分析的图像。为了节省摄取成本,摄取代码应对照分析 JSON 文件进行交叉检查并仅下载这些文件;当任何这些来源不再可用或有新来源可用时,应发出警报。
NETravelData 的图像每晚回填似乎刷新了约 40% 的 NETravelData 图像;如果仅每天需要这些数字,则定期刷新的优势就会减弱,因此可以删除云函数distribute_ne_travel_data 。
http async异步转向 PubSub初始设计在测试新模型时使用手动操作的脚本 - 即batch_process_images.py 。这会报告成功(或失败)以及处理的图像数量。为此,云函数可以很好地工作,因为它会返回结果。然而,更高效的架构是在内部使用 PubSub 队列,并使用distribute_json_sources和processed_scheduled函数将工作添加到由单个工作函数消耗的 PubSub 队列,而不是当前的异步调用层次结构(使用两个额外的函数来横向扩展) )。
纽卡斯尔大学城市观测站提供了我们使用的预训练 Faster-RCNNN(本地副本存储在/tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb fig_frcnn_rebuscov-3.pb 中)。
数据由东北城市交通管理和控制开放数据服务提供,并根据开放政府许可证 3.0 获得许可。图片来自泰恩威尔郡城市交通管理和控制。
东北部数据由纽卡斯尔大学城市观测站进一步处理和托管,我们衷心感谢其支持和建议。
数据由伦敦交通局 (TfL) 提供,并由伦敦交通局开放数据 (TfL Open Data) 提供支持。该数据根据开放政府许可证 2.0 版获得许可。 TfL 数据包含 OS 数据 © Crown 版权和数据库权利 2016 以及 Geomni UK 地图数据 © 和数据库权利 (2019)。
本项目使用了各种第三方库;这些都列在依赖项页面上,我们衷心感谢他们的贡献。


