Candle 是 Rust 的极简 ML 框架,重点关注性能(包括 GPU 支持)和易用性。尝试我们的在线演示:whisper、LLaMA2、T5、yolo、Segment Anything。
确保您已按照安装中的说明正确安装了candle-core 。
让我们看看如何运行简单的矩阵乘法。将以下内容写入您的myapp/src/main.rs文件:
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run应显示形状为Tensor[[2, 4], f32]的张量。
安装带有 Cuda 支持的candle后,只需将device定义在 GPU 上即可:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;有关更高级的示例,请查看以下部分。
这些在线演示完全在您的浏览器中运行:
我们还提供了一些使用最先进模型的基于命令行的示例:
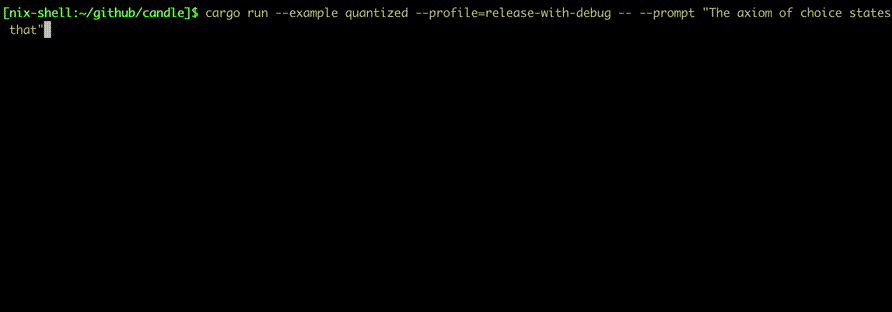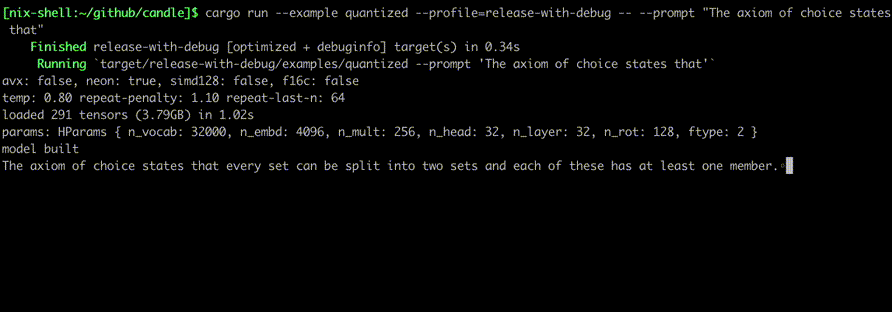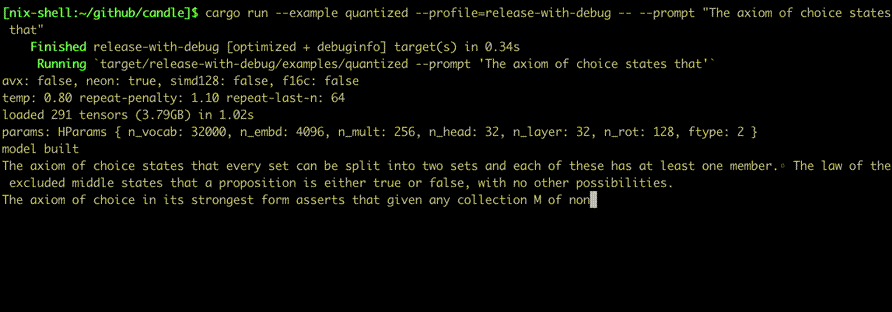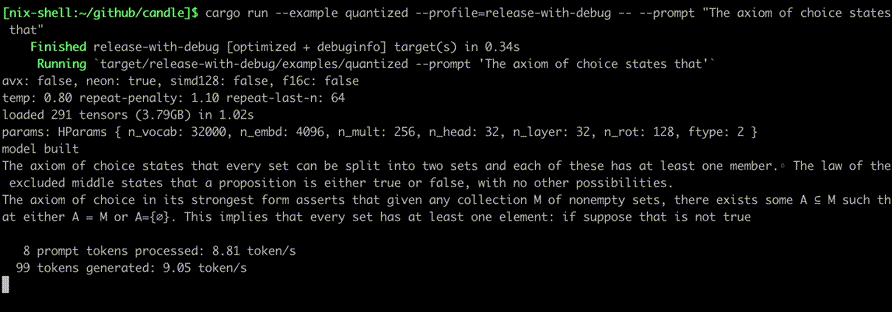





使用以下命令运行它们:
cargo run --example quantized --release
为了使用CUDA,请将--features cuda添加到示例命令行。如果您安装了 cuDNN,请使用--features cudnn获得更多加速。
还有一些针对 Whisper 和 llama2.c 的 wasm 示例。您可以使用trunk构建它们,也可以在线尝试它们:whisper、llama2、T5、Phi-1.5 和 Phi-2、Segment Anything Model。
对于 LLaMA2,运行以下命令来检索权重文件并启动测试服务器:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081然后访问 http://localhost:8081/。
candle-tutorial :非常详细的教程,展示如何将 PyTorch 模型转换为 Candle。candle-lora :针对 Candle 的高效且符合人体工程学的 LoRA 实现。 candle-lora有optimisers :优化器的集合,包括带有动量的 SGD、AdaGrad、AdaDelta、AdaMax、NAdam、RAdam 和 RMSprop。candle-vllm :用于推理和服务本地 LLM 的高效平台,包括 OpenAI 兼容的 API 服务器。candle-ext :Candle 的扩展库,提供 Candle 目前不可用的 PyTorch 功能。candle-coursera-ml :Coursera 机器学习专业课程中的 ML 算法的实现。kalosm :Rust 中的多模式元框架,用于与本地预训练模型交互,支持受控生成、自定义采样器、内存向量数据库、音频转录等。candle-sampling :蜡烛的采样技术。gpt-from-scratch-rs :YouTube 上 Andrej Karpathy 的Let's build GPT教程的移植版,展示了针对玩具问题的 Candle API。candle-einops :Python einops 库的纯 Rust 实现。atoma-infer :一个用于大规模快速推理的 Rust 库,利用 FlashAttention2 进行高效的注意力计算,利用 PagedAttention 进行高效的 KV 缓存内存管理,以及多 GPU 支持。它与 OpenAI api 兼容。如果您对此列表有任何补充,请提交拉取请求。
备忘单:
| 使用 PyTorch | 使用蜡烛 | |
|---|---|---|
| 创建 | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| 创建 | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| 索引 | tensor[:, :4] | tensor.i((.., ..4))? |
| 运营 | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| 运营 | a.matmul(b) | a.matmul(&b)? |
| 算术 | a + b | &a + &b |
| 设备 | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| 数据类型 | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| 保存 | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| 加载中 | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
Tensor结构定义Candle 的核心目标是让无服务器推理成为可能。像 PyTorch 这样的完整机器学习框架非常大,这使得在集群上创建实例的速度很慢。 Candle 允许部署轻量级二进制文件。
其次,Candle 可以让您从生产工作负载中删除 Python 。 Python 开销会严重影响性能,而 GIL 是众所周知的令人头疼的问题。
最后,Rust 很酷!许多 HF 生态系统已经拥有 Rust 箱,例如安全张量和标记器。
dfdx 是一个强大的板条箱,其形状包含在类型中。通过让编译器立即抱怨形状不匹配,可以避免很多令人头疼的问题。然而,我们发现某些功能仍然需要 nightly,并且编写代码对于非 Rust 专家来说可能有点令人畏惧。
我们在运行时利用其他核心 crate 并为其做出贡献,因此希望这两个 crate 能够相互受益。
burn 是一个通用包,可以利用多个后端,因此您可以为您的工作负载选择最佳引擎。
tch-rs 绑定到 Rust 中的 torch 库。非常通用,但它们将整个火炬库引入运行时。 tch-rs的主要贡献者也参与了candle的开发。
如果使用 mkl 或加速功能编译二进制文件/测试时缺少一些符号,例如对于 mkl,您会得到:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
或加速:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
这可能是由于缺少启用 mkl 库所需的链接器标志。您可以尝试在二进制文件的顶部添加 mkl 的以下内容:
extern crate intel_mkl_src ;或加速:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
这可能是因为您无权使用 LLaMA-v2 模型。要解决此问题,您必须在 Huggingface-hub 上注册,接受 LLaMA-v2 模型条件,并设置您的身份验证令牌。有关更多详细信息,请参阅问题#350。
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass 作为 git 子模块提供,因此您可能需要运行以下命令来正确签入它。
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
这是由 Cuda 编译器触发的 gcc-11 中的错误。要解决此问题,请安装不同的受支持的 gcc 版本 - 例如 gcc-10,并在 NVCC_CCBIN 环境变量中指定编译器的路径。
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
确保链接可能位于项目目标外部的所有本机库,例如,要运行 mdbook 测试,您应该运行:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
这可能是由于从/mnt/c加载模型引起的,有关 stackoverflow 的更多详细信息。
您可以设置RUST_BACKTRACE=1以便在生成蜡烛错误时提供回溯。
如果您on an遇到called Result::unwrap() 的错误value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } }在value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } }上。要修复复制并重命名这 3 个文件(确保它们位于路径中)。路径取决于您的 cuda 版本。 c:WindowsSystem32nvcuda.dll - > cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll - > cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


