greta.gam 允许您使用 mgcv 的平滑函数和公式语法来定义在 greta 模型中使用的平滑项。然后,您可以定义自己完成模型的可能性,并通过 MCMC 对其进行拟合。
这是正在进行中的工作!
这是改编自mgcv ?gam帮助文件的简单示例:
在mgcv中:
library( mgcv )
# > Loading required package: nlme
# > This is mgcv 1.9-1. For overview type 'help("mgcv-package")'.
set.seed( 2 )
# simulate some data...
dat <- gamSim( 1 , n = 400 , dist = " normal " , scale = 0.3 )
# > Gu & Wahba 4 term additive model
# fit a model using gam()
b <- gam( y ~ s( x2 ), data = dat )现在在greta中拟合相同的模型:
library( greta.gam )
# > Loading required package: greta
# >
# > Attaching package: 'greta'
# > The following objects are masked from 'package:stats':
# >
# > binomial, cov2cor, poisson
# > The following objects are masked from 'package:base':
# >
# > %*%, apply, backsolve, beta, chol2inv, colMeans, colSums, diag,
# > eigen, forwardsolve, gamma, identity, rowMeans, rowSums, sweep,
# > tapply
set.seed( 2024 - 02 - 09 )
# setup the linear predictor for the smooth
z <- smooths( ~ s( x2 ), data = dat )
# > ℹ Initialising python and checking dependencies, this may take a moment.
# > ✔ Initialising python and checking dependencies ... done!
# set the distribution of the response
distribution( dat $ y ) <- normal( z , 1 )
# make some prediction data
pred_dat <- data.frame ( x2 = seq( 0 , 1 , length.out = 100 ))
# z_pred stores the predictions
z_pred <- evaluate_smooths( z , newdata = pred_dat )
# build model
m <- model( z_pred )
# draw from the posterior
draws <- mcmc( m , n_samples = 200 )
# > running 4 chains simultaneously on up to 8 CPU cores
#> warmup 0/1000 | eta: ?s warmup == 50/1000 | eta: 30s warmup ==== 100/1000 | eta: 17s warmup ====== 150/1000 | eta: 12s warmup ======== 200/1000 | eta: 10s warmup ========== 250/1000 | eta: 8s warmup =========== 300/1000 | eta: 7s warmup ============= 350/1000 | eta: 6s warmup =============== 400/1000 | eta: 5s warmup ================= 450/1000 | eta: 5s warmup =================== 500/1000 | eta: 4s warmup ===================== 550/1000 | eta: 4s warmup ======================= 600/1000 | eta: 3s warmup ========================= 650/1000 | eta: 3s warmup =========================== 700/1000 | eta: 2s warmup ============================ 750/1000 | eta: 2s warmup ============================== 800/1000 | eta: 1s warmup ================================ 850/1000 | eta: 1s warmup ================================== 900/1000 | eta: 1s warmup ==================================== 950/1000 | eta: 0s warmup ====================================== 1000/1000 | eta: 0s
# > sampling 0/200 | eta: ?s sampling ========== 50/200 | eta: 1s sampling =================== 100/200 | eta: 0s sampling ============================ 150/200 | eta: 0s sampling ====================================== 200/200 | eta: 0s
# plot the mgcv fit
plot( b , scheme = 1 , shift = coef( b )[ 1 ])
# add in a line for each posterior sample
apply( draws [[ 1 ]], 1 , lines , x = pred_dat $ x2 , col = " blue " )
# > NULL
# plot the data
points( dat $ x2 , dat $ y , pch = 19 , cex = 0.2 )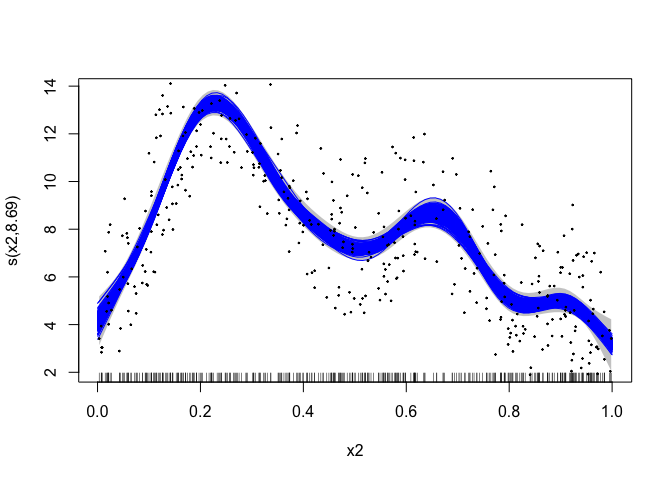
greta.gam使用mgcv中jagam (Wood, 2016) 例程中的一些技巧来让事情正常工作。对于那些对内部运作感兴趣的人来说,以下是一些简短的细节......
GAM 是具有贝叶斯解释的模型(即使使用“频率派”方法进行拟合)。人们可以将平滑惩罚矩阵视为贝叶斯随机效应模型中的先验精度矩阵。设计矩阵的构建与频率论案例完全相同。有关这方面的更多背景信息,请参阅 Miller (2021)。
GAM 的贝叶斯解释有一点困难,因为在其朴素形式中,先验作为惩罚的零空间(在一维情况下,通常是线性项)是不合适的。为了获得正确的先验,我们可以使用 Marra & Wood (2011) 中使用的“技巧”之一——即以某种方式惩罚导致不正确先验的惩罚部分。我们采用jagam提供的选项,并为这些项创建一个额外的惩罚矩阵(来自惩罚矩阵的特征分解;参见 Marra & Wood,2011)。
Marra, G 和 Wood, SN (2011) 广义可加模型的实用变量选择。计算统计和数据分析,55,2372–2387。
米勒 DL (2021)。广义加性建模的贝叶斯观点。 arXiv.
Wood, SN (2016) 只是另一个吉布斯增法建模器:JAGS 和 mgcv 的接口。统计软件杂志75,no。 7


