LARS
v2.0-beta8:

LARS 是一款应用程序,可让您在设备上本地运行 LLM(大型语言模型)、上传您自己的文档并参与对话,其中 LLM 根据您上传的内容做出响应。这种基础有助于提高准确性并减少人工智能产生的不准确或“幻觉”的常见问题。该技术通常称为“检索增强生成”或 RAG。
有许多桌面应用程序可用于本地运行 LLM,而 LARS 的目标是成为最终的以 RAG 为中心的开源 LLM 应用程序。为此,LARS 进一步采用了 RAG 的概念,为每个回复添加详细的引用,为您提供特定的文档名称、页码、文本突出显示以及与您的问题相关的图像,甚至在响应窗口。虽然所有引用并不总是出现在每个回复中,但我们的想法是至少为每个 RAG 回复提供某种引用组合,而且通常发现情况就是如此。
LARS 功能演示视频
Python v3.10.x 或更高版本:https://www.python.org/downloads/
火炬:
如果您计划使用 GPU 运行 LLM,请确保安装适合您的设置的 GPU 驱动程序和 CUDA/ROCm 工具包,然后才继续进行下面的 PyTorch 设置
下载并安装适合您系统的 PyTorch 版本:https://pytorch.org/get-started/locally/
克隆存储库:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokens安装Python依赖项:
通过 PIP 的 Windows:
pip install -r .requirements.txt
Linux 通过 PIP:
pip3 install -r ./requirements.txt
关于 Azure 的注意事项:某些必需的 Azure 库在 MacOS 平台上不可用!因此,MacOS 包含一个单独的要求文件,不包括这些库:
苹果系统:
pip3 install -r ./requirements_mac.txt
返回目录
安装后,使用以下命令运行 LARS:
cd web_app
python app.py # Use 'python3' on Linux/macOS
在浏览器中导航至http://localhost:5000/
LARS 所需的所有应用程序目录现在都将在磁盘上创建
HF-Waitress 服务器将自动启动,并在首次运行时下载 LLM (Microsoft Phi-3-Mini-Instruct-44),这可能需要一段时间,具体取决于您的互联网连接速度
在第一次查询时,将从 HuggingFace Hub 下载嵌入模型 (all-mpnet-base-v2),这应该需要很短的时间
返回目录
在 Windows 上:
从官方网站 - “Visual Studio 工具”下载 Microsoft Visual Studio Build Tools 2022
注意:安装上述组件时,请确保选择以下组件:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
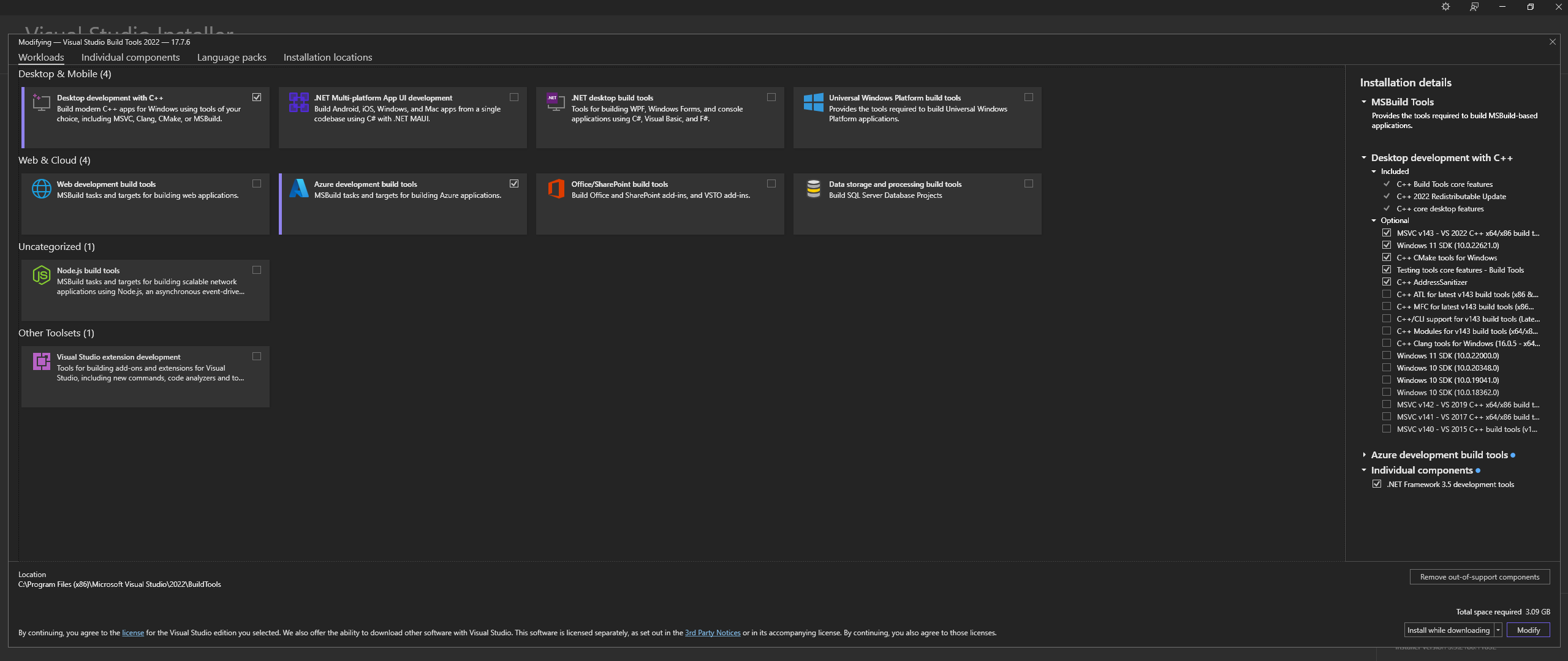
Desktop development with C++工作负载以及MSVC and C++ CMake选项在 Linux(基于 Ubuntu 和 Debian)上,安装以下软件包:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
从官方仓库下载:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
从官方网站在 Windows 上安装 CMAKE
C:Program FilesCMakebin使用 CMAKE 构建 llama.cpp:
注意:为了加快编译速度,请添加 -j 参数以并行运行多个作业。例如, cmake --build build --config Release -j 8将并行运行 8 个作业。
使用 CUDA 构建:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
如果您在尝试运行CMake -B build时遇到问题,请检查下面的详细 CMake 安装故障排除步骤
添加到路径:
path_to_cloned_repollama.cppbuildbinRelease
通过终端验证安装:
llama-server
安装 Nvidia GPU 驱动程序
安装 Nvidia CUDA 工具包 - LARS 使用 v12.2 和 v12.4 构建并测试
通过终端验证安装:
nvcc -V
nvidia-smi
CMAKE-CUDA 修复(非常重要!):
从以下目录复制所有四个文件:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
并将它们粘贴到以下目录:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
这是可选的,但强烈推荐的依赖项 - 如果未完成此设置,则仅支持 PDF
视窗:
从官方网站下载
通过以下方式添加到 PATH:
高级系统设置 -> 环境变量 -> 系统变量 -> 编辑路径变量 -> 添加以下内容(根据您的安装位置进行更改):
C:Program FilesLibreOfficeprogram
或者通过 PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
基于 Ubuntu 和 Debian 的 Linux - 从官方网站下载或通过终端安装:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora 和其他基于 RPM 的发行版 - 从官方网站下载或通过终端安装:
sudo dnf update
sudo dnf install libreoffice
MacOS - 从官方网站下载或通过 Homebrew 安装:
brew install --cask libreoffice
验证安装:
在 Windows 和 MacOS 上:运行 LibreOffice 应用程序
在 Linux 上通过终端:
libreoffice --version
LARS 利用 pdf2image Python 库将文档的每一页转换为 OCR 所需的图像。该库本质上是处理转换过程的 Poppler 实用程序的包装器。
视窗:
从官方仓库下载
通过以下方式添加到 PATH:
高级系统设置 -> 环境变量 -> 系统变量 -> 编辑路径变量 -> 添加以下内容(根据您的安装位置进行更改):
path_to_installationpoppler_versionLibrarybin
或者通过 PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
这是一个可选的依赖项 - LARS 中并未积极使用 Tesseract-OCR,但源代码中存在使用它的方法
视窗:
通过 UB-Mannheim 下载适用于 Windows 的 Tesseract-OCR
通过以下方式添加到 PATH:
高级系统设置 -> 环境变量 -> 系统变量 -> 编辑路径变量 -> 添加以下内容(根据您的安装位置进行更改):
C:Program FilesTesseract-OCR
或者通过 PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
返回目录
LARS 已使用 Python v3.11.x 构建并测试
在 Windows 上安装 Python v3.11.x:
从官网下载v3.11.9
在安装过程中,请确保选中“将 Python 3.11 添加到 PATH”或稍后通过以下方式手动添加:
高级系统设置 -> 环境变量 -> 系统变量 -> 编辑路径变量 -> 添加以下内容(根据您的安装位置进行更改):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
或者通过 PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
在 Linux(基于 Ubuntu 和 Debian)上安装 Python v3.11.x:
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
通过终端验证安装:
python3 --version
如果您在pip install时遇到错误,请尝试以下操作:
删除版本号:
==version.number段,例如:urllib3==2.0.4urllib3创建并使用Python虚拟环境:
建议使用虚拟环境,避免与其他Python项目冲突
视窗:
创建Python虚拟环境(venv):
python -m venv larsenv
激活并随后使用 venv:
.larsenvScriptsactivate
完成后停用 venv:
deactivate
Linux 和 MacOS:
创建Python虚拟环境(venv):
python3 -m venv larsenv
激活并随后使用 venv:
source larsenv/bin/activate
完成后停用 venv:
deactivate
如果问题仍然存在,请考虑在 LARS GitHub 存储库上提出问题以获得支持。
CMake nmake failed错误,如下所示: 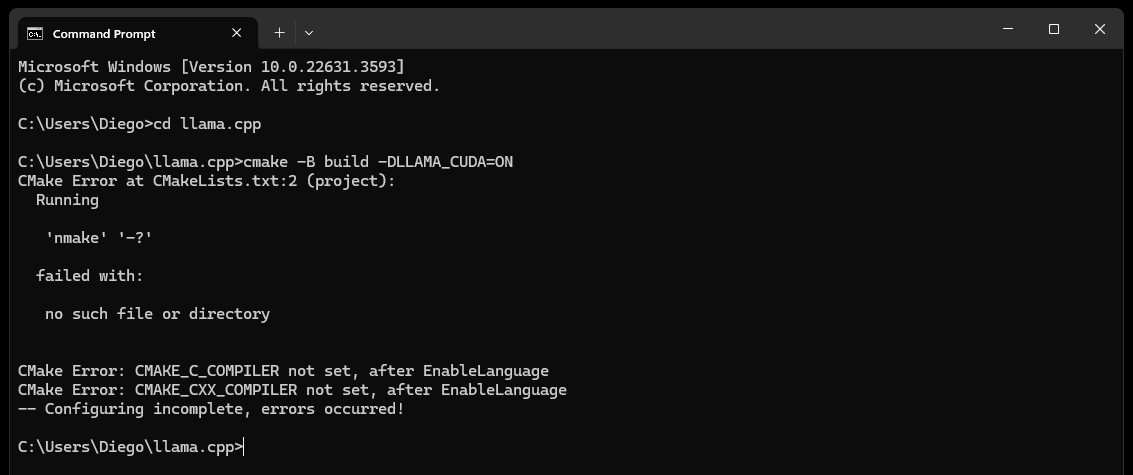
这通常表明 Microsoft Visual Studio 构建工具存在问题,因为 CMake 无法找到 nmake 工具,该工具是 Microsoft Visual Studio 构建工具的一部分。请尝试以下步骤来解决该问题:
确保安装了 Visual Studio 构建工具:
确保安装了 Visual Studio 构建工具,包括 nmake。您可以通过 Visual Studio 安装程序安装这些工具,方法是选择使用Desktop development with C++以及MSVC and C++ CMake选项
检查依赖项部分的步骤 0,特别是其中的屏幕截图
检查环境变量:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
使用开发者命令提示符:
打开“Visual Studio 开发人员命令提示符”,为您设置必要的环境变量
您可以从 Visual Studio 下的“开始”菜单找到此提示
设置 CMake 生成器:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
如果问题仍然存在,请考虑在 LARS GitHub 存储库上提出问题以获得支持。
最终(大约 60 秒后)您将在页面上看到一条指示错误的警报:
Failed to start llama.cpp local-server
这表明首次运行已完成,所有应用程序目录均已创建,但models目录中不存在 LLM,现在可以移动到该目录
将您的 LLM(llama.cpp 支持的任何文件格式,最好是 GGUF)移动到新创建的models目录,默认位于以下位置:
C:/web_app_storage/models/app/storage/models/app/models将 LLM 放置在上面相应的models目录中后,刷新http://localhost:5000/
大约 60 秒后,您将再次收到错误警报,指出Failed to start llama.cpp local-server
这是因为现在需要在 LARS Settings菜单中选择您的 LLM
接受警报并单击右上角的Settings齿轮图标
在LLM Selection卡中,从相应的下拉列表中选择您的 LLM 和相应的提示模板格式
修改高级设置以正确设置GPU选项、 Context-Length以及可选的令牌生成限制( Maximum tokens to predict )。
点击Save ,如果未触发自动刷新,请手动刷新页面
如果所有步骤均已正确执行,则首次设置现已完成,LARS 即可使用
LARS 还会记住您的 LLM 设置以供后续使用
返回目录
支持的文档格式:
如果已安装 LibreOffice 并将其添加到 PATH(如“依赖项”部分的步骤 4 中所述),则支持以下格式:
如果未安装 LibreOffice,则仅支持 PDF
用于文本提取的 OCR 选项:
LARS 提供了三种从文档中提取文本的方法,以适应各种文档类型和质量:
本地文本提取:使用 PyPDF2 从非扫描 PDF 中高效提取文本。当高精度并不重要或需要完全本地处理时,非常适合快速处理。
Azure ComputerVision OCR - 增强文本提取准确性并支持扫描文档。对于处理标准文档布局很有用。提供适合初始试用和小批量使用的免费套餐,上限为每月 5000 笔交易,每分钟 20 笔交易。
Azure AI 文档智能 OCR - 最适合具有复杂结构(例如表格)的文档。 LARS 中的自定义解析器优化了提取过程。
笔记:
在大多数情况下,Azure OCR 选项会产生 API 成本,并且不与 LARS 捆绑在一起。
如上面的链接所示,可以使用 ComputerVision OCR 的有限免费套餐。该服务总体上更便宜,但速度较慢,并且可能不适用于非标准文档布局(A4 等除外)。
选择 OCR 选项时,请考虑文档类型和您的准确性需求。
法学硕士:
目前仅支持本地法学硕士
Settings菜单为高级用户提供了许多选项,可通过LLM Selection卡配置和更改 LLM
如果使用 llama.cpp,请注意:非常重要:为您正在运行的 LLM 选择适当的提示模板格式
目前通过 llama.cpp 支持针对以下提示模板格式进行培训的法学硕士:
通过Advanced Settings调整核心配置设置(触发 LLM 重新加载和页面刷新):
调整设置以随时更改响应行为:
嵌入模型和向量数据库:
LARS中提供了四种嵌入模型:
除了 Azure-OpenAI 嵌入之外,所有其他模型都完全在本地免费运行。首次运行时,这些模型将从 HuggingFace Hub 下载。这是一次性下载,随后它们将出现在本地。
用户可以随时通过Settings菜单中的VectorDB & Embedding Models选项卡在这些嵌入模型之间切换
文档加载表:在Settings菜单中,将为所选嵌入模型显示一个表,其中显示嵌入到关联矢量数据库的文档列表。如果多次加载文档,则该表中将有多个条目,这对于调试任何问题可能很有用。
清除 VectorDB:使用Reset按钮并提供确认以清除选定的矢量数据库。这会在磁盘上为选定的嵌入模型创建一个新的 vectorDB。旧的 vectorDB 仍然保留,并且可以通过手动修改 config.json 文件来恢复。
编辑系统提示符:
系统提示作为整个对话中 LLM 的指示
LARS 为用户提供了通过Settings菜单编辑系统提示的功能,方法是从System Prompt选项卡的下拉列表中选择Custom选项
更改系统提示将开始新的聊天
强制启用/禁用 RAG:
通过Settings菜单,用户可以在需要时强制启用或禁用 RAG(检索增强生成 - 使用文档中的内容来改进 LLM 生成的响应)
这对于评估两种情况下的 LLM 响应通常很有用
强制禁用也会关闭归因功能
默认设置是推荐选项,它使用 NLP 来确定何时应该执行 RAG、何时不应该执行 RAG
该设置可以随时更改
聊天记录:
使用左上角的聊天记录菜单浏览并恢复之前的对话
非常重要:恢复之前的对话时请注意提示模板不匹配!使用右上角的Information图标确保先前对话中使用的 LLM 和当前使用的 LLM 都基于相同的提示模板格式!
用户评价:
用户可以随时对每个响应进行 5 分制评分
评级数据存储在位于应用程序目录中的chat-history.db SQLite3 数据库中:
C:/web_app_storage/app/storage/app评级数据对于评估和完善您的工作流程工具非常有价值
注意事项:
返回目录
如果聊天出现问题,或者生成任何奇怪的响应,只需尝试通过左上角的菜单启动New Chat
或者,只需刷新页面即可开始新的聊天
如果遇到引用或 RAG 性能问题,请尝试按照上述一般用户指南的步骤 4 中的说明重置向量数据库
如果出现任何应用程序问题,并且仅通过开始新的聊天或重新启动 LARS 无法解决,请尝试按照以下步骤删除 config.json 文件:
CTRL+C终止 Python 程序来关闭 LARS 应用程序服务器LARS/web_app的config.json文件(与app.py同一目录)对于任何严重的数据和引用问题,即使按照上述一般用户指南的步骤 4 中所述重置 VectorDB 也无法解决,请执行以下步骤:
CTRL+C终止 Python 程序来关闭 LARS 应用程序服务器C:/web_app_storage/app/storage/app如果问题仍然存在,请考虑在 LARS GitHub 存储库上提出问题以获得支持。
返回目录
LARS 已通过以下两个单独的镜像适应 Docker 容器部署环境:
两者都有不同的要求,前者部署更简单,但由于 CPU 和 DDR 内存成为瓶颈,推理性能要慢得多
虽然没有明确要求,但具有 Docker 容器的经验以及熟悉容器化和虚拟化概念将在本节中非常有帮助!
从两者的常见设置步骤开始:
安装 Docker
您的 CPU 应支持虚拟化,并且应在系统的 BIOS/UEFI 中启用它
下载并安装 Docker Desktop
如果在 Windows 上,您可能需要安装适用于 Linux 的 Windows 子系统(如果尚未安装)。为此,请以管理员身份打开 PowerShell 并运行以下命令:
wsl --install
确保 Docker Desktop 已启动并运行,然后打开命令提示符/终端并执行以下命令以确保 Docker 已正确安装并启动并运行:
docker ps
创建一个 Docker 存储卷,它将在运行时附加到 LARS 容器:
创建与 LARS 容器一起使用的存储卷非常有利,因为它允许您将 LARS 容器升级到更新版本,或在 CPU 和 GPU 容器变体之间切换,同时无缝保留所有设置、聊天历史记录和矢量数据库。
在命令提示符/终端中执行以下命令:
docker volume create lars_storage_volue
该卷稍后将在运行时附加到 LARS 容器,现在继续按照以下步骤构建 LARS 映像。
在命令提示符/终端中,执行以下命令:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
完成后,在浏览器中导航到http://localhost:5000/并按照首次运行步骤和用户指南的其余部分进行操作
故障排除部分也适用于 Container-LARS
要求(除了 Docker 之外):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
对于 Linux,您已完成上述设置,因此请跳过下一步并直接进入下面的构建和运行步骤
如果在 Windows 上,并且这是您第一次在 Docker 上运行 Nvidia GPU 容器,请系好安全带,因为这将是一次相当愉快的旅程(最喜欢的饮料或强烈推荐的三种饮料!)
冒着极端冗余的风险,在继续之前确保存在以下依赖项:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
如果不确定,请参阅上面的 Nvidia CUDA 依赖项部分和 Docker 设置部分
如果以上内容都存在并已设置,您就可以继续
打开 PC 上的 Microsoft Store 应用程序,然后下载并安装 Ubuntu 22.04.3 LTS(必须与 dockerfile 中第 2 行的版本匹配)
是的,您没看错:从 Microsoft store 应用程序下载并安装 Ubuntu,请参阅下面的屏幕截图:
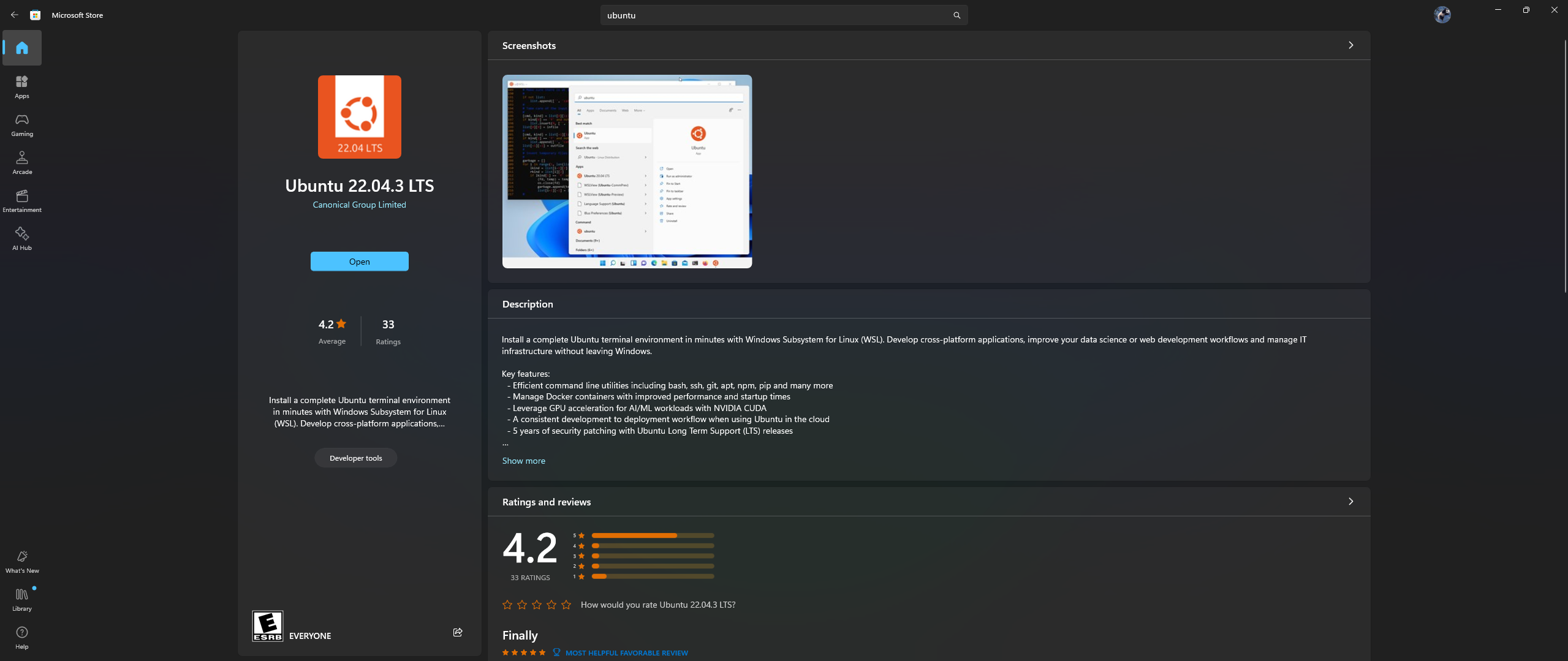
现在是时候在 Ubuntu 中安装 Nvidia 容器工具包了,请按照以下步骤操作:
上述安装完成后,通过在开始菜单中搜索Ubuntu在 Windows 中启动 Ubuntu shell
在打开的 Ubuntu 命令行中,执行以下步骤:
配置生产存储库:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
从存储库更新包列表并安装 Nvidia Container Toolkit 包:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
使用 nvidia-ctk 命令配置容器运行时,该命令会修改 /etc/docker/daemon.json 文件,以便 Docker 可以使用 Nvidia 容器运行时:
sudo nvidia-ctk runtime configure --runtime=docker
重新启动 Docker 守护进程:
sudo systemctl restart docker
现在您的 Ubuntu 设置已完成,是时候完成 WSL 和 Docker 集成了:
打开一个新的 PowerShell 窗口并将此 Ubuntu 安装设置为 WSL 默认安装:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
导航到Docker Desktop -> Settings -> Resources -> WSL Integration -> 检查默认和 Ubuntu 22.04 集成。请参考下面的截图:
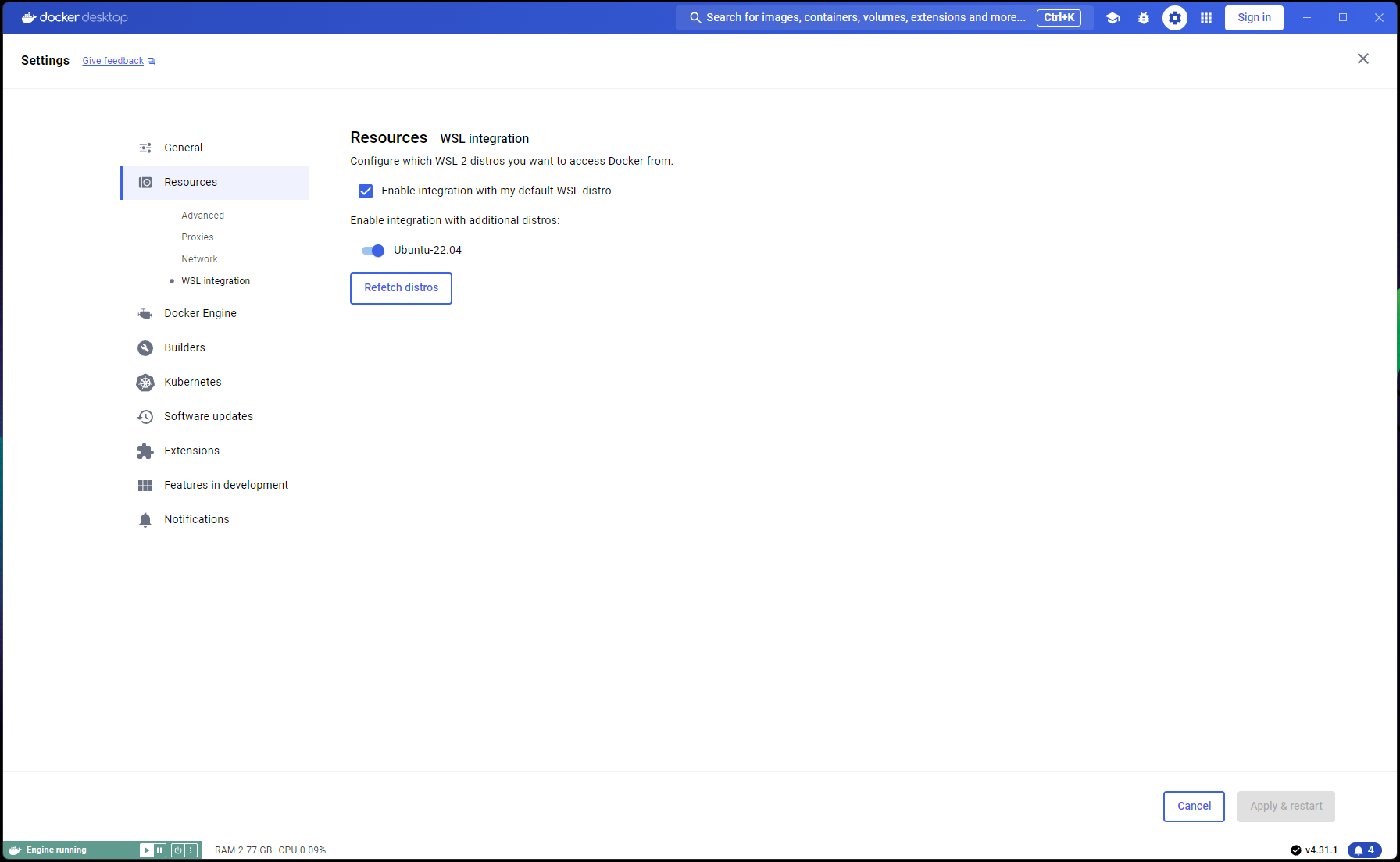
现在,如果一切都已正确完成,您就可以构建并运行容器了!
在命令提示符/终端中,执行以下命令:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
完成后,在浏览器中导航到http://localhost:5000/并按照首次运行步骤和用户指南的其余部分进行操作
故障排除部分也适用于 Container-LARS
如果您遇到与网络相关的错误,特别是与构建容器时不可用的包存储库有关的错误,则这是您最终的网络问题,通常与防火墙问题有关
在 Windows 上,导航到Control PanelSystem and SecurityWindows Defender FirewallAllowed apps ,或在开始菜单中搜索Firewall并前往Allow an app through the firewall并确保允许“Docker Desktop Backend”通过
第一次运行 LARS 时,将下载句子转换器嵌入模型
在容器化环境中,此下载有时可能会出现问题,并在您提出查询时导致错误
如果发生这种情况,只需前往 LARS 设置菜单: Settings->VectorDB & Embedding Models并将嵌入模型更改为 BGE-Base 或 BGE-Large,这将强制重新加载和下载
完成后,再次提问,响应应该正常生成
您可以切换回句子转换器嵌入模型,问题应该得到解决
如上面的故障排除部分所述,首次运行 LARS 时会下载嵌入模型
最好在关闭容器之前保存容器的状态,这样每次启动容器时都不需要重复此下载步骤
为此,请打开另一个命令提示符/终端并在关闭正在运行的 LARS 容器之前提交更改:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
这将创建一个更新的图像,您可以在后续运行中使用:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
注意:完成上述操作后,如果您使用docker images检查图像使用的空间,您会发现使用了大量空间。但是,不要从字面上理解这里的尺寸!每个图像显示的大小包括其所有层的总大小,但其中许多层在图像之间共享,特别是如果这些图像基于相同的基础图像或者一个图像是另一个图像的提交版本。要查看 Docker 映像实际使用了多少磁盘空间,请使用:
docker system df
返回目录
| 类别 | 任务 | 地位 |
|---|---|---|
| 错误修复: | 零字节文本文件创建风险 - 有时,如果输入文档的 OCR/文本提取失败,可能会留下 0B .txt 文件,这会导致进一步重试尝试相信该文件已被加载 | ?未来的任务 |
| 实用特点: | 以易用性为中心: | |
| Azure CV-OCR 免费层 UI 切换 | ✅ 于 2024 年 6 月 8 日完成 | |
| 删除聊天记录 | ?未来的任务 | |
| 重命名聊天记录 | ?未来的任务 | |
| PowerShell 安装脚本 | ?未来的任务 | |
| Linux安装脚本 | ?未来的任务 | |
| Ollama LLM 推理后端作为 llama.cpp 的替代品 | ?未来的任务 | |
| 集成其他云提供商(GCP、AWS、OCI 等)的 OCR 服务 | ?未来的任务 | |
| UI 切换以在上传文档时忽略先前的文本摘录 | ?未来的任务 | |
| 文件上传的模态弹出窗口:从设置中镜像文本提取选项、提交时全局覆盖、切换到持久设置 | ?未来的任务 | |
| 以性能为中心: | ||
| Nvidia TensorRT-LLM AWQ 支持 | ?未来的任务 | |
| 研究任务: | 研究 Nvidia TensorRT-LLM:需要构建特定于目标 GPU 的 AWQ-LLM TRT 引擎,NvTensorRT-LLM 是它自己的生态系统,仅适用于 Python v3.10。 | ✅ 于 2024 年 6 月 13 日完成 |
| 具有 Vision 法学硕士的本地 OCR:MS-TrOCR(已完成)、Kosmos-2.5(高优先级)、Llava、Florence-2 | ? 2024 年 7 月 5 日更新进行中 | |
| RAG 改进:重新排序、RAPTOR、T-RAG | ?未来的任务 | |
| 研究 GraphDB 集成:使用法学硕士从文档中提取实体关系数据并填充、更新和维护 GraphDB | ?未来的任务 |
返回目录
我希望 LARS 对您的工作有价值,并邀请您支持其持续发展!如果您欣赏该工具并愿意为其未来的增强做出贡献,请考虑捐赠。您的支持帮助我继续改进 LARS 并添加新功能。
如何捐赠 要进行捐赠,请使用以下 PayPal 链接:
通过 PayPal 捐赠
我们非常感谢您的贡献,并将用于资助进一步的开发工作。
返回目录


