nim anywhere
1.0.0

如果您是内部用户,请加入 #cdd-nim-anywhere slack 频道;如果您是外部用户,请提出问题并提出任何问题和反馈。
企业使用人工智能的主要好处之一是他们能够处理内部数据并从中学习。检索增强生成(RAG)是实现这一目标的最佳方法之一。 NVIDIA 开发了一套名为 NIM 微服务的微服务,以帮助我们的合作伙伴和客户轻松构建有效的 RAG 管道。
NIM Anywhere 包含开始为 RAG 集成 NIM 所需的所有工具。它本身可以扩展到全规模的实验室和生产环境。这对于构建 RAG 架构并根据需要轻松添加 NIM 来说是个好消息。如果您不熟悉 RAG,它会在推理过程中动态检索相关外部信息,而无需修改模型本身。想象一下,您是一家公司的技术主管,该公司的本地数据库包含机密的最新信息。您不希望 OpenAI 访问您的数据,但您需要模型理解数据才能准确回答问题。解决方案是将您的语言模型连接到数据库并向其提供信息。
要详细了解为什么 RAG 是提高生成式 AI 模型准确性和可靠性的出色解决方案,请阅读此博客。
立即按照快速入门说明开始使用 NIM Anywhere,并使用 NIM 构建您的第一个 RAG 应用程序!
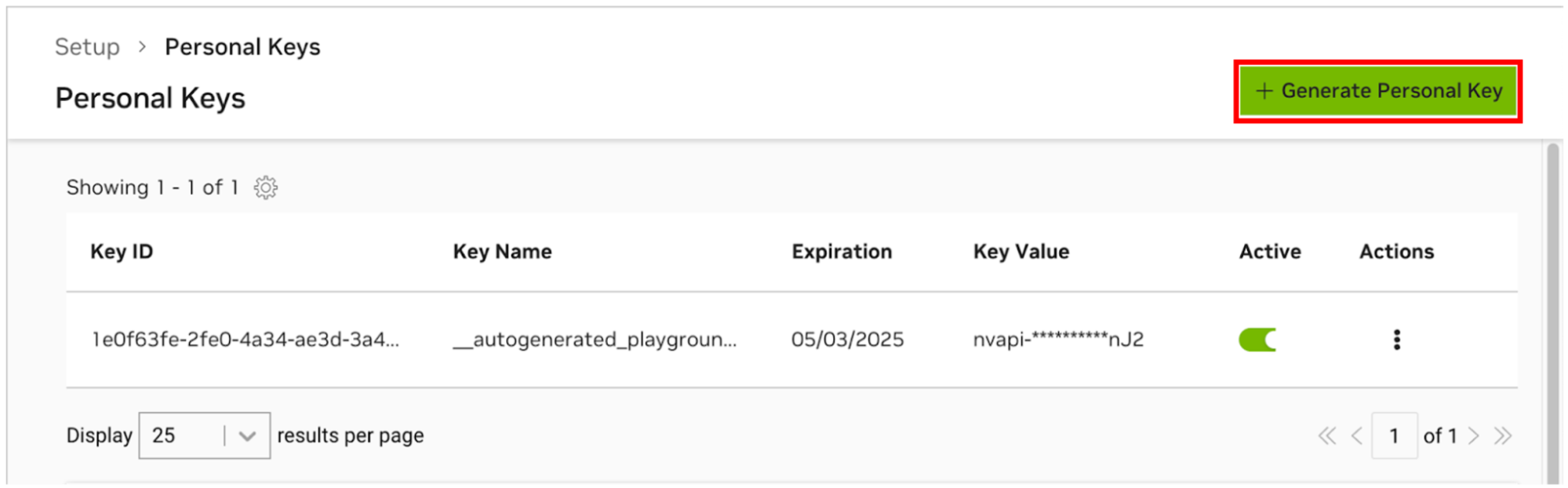
要允许 AI Workbench 访问 NVIDIA 的云资源,您需要为其提供个人密钥。这些键以nvapi-开头。
转至 NGC 个人密钥管理器。如果出现提示,请注册一个新帐户并登录。
提示您可以通过以下方式找到此工具:登录 ngc.nvidia.com,展开右上角的个人资料菜单,选择“设置” ,然后选择“生成个人密钥” 。
选择生成个人密钥。
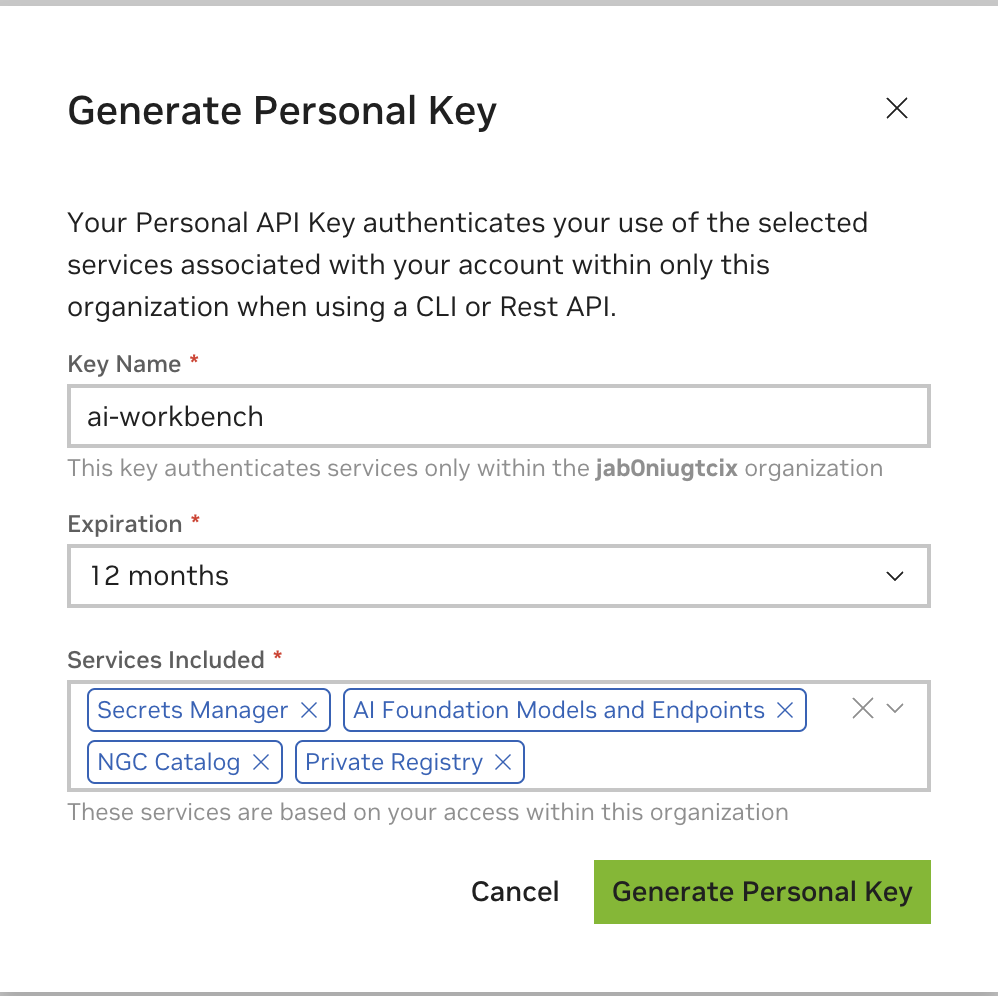
输入任意值作为密钥名称,有效期为 12 个月即可,然后选择所有服务。完成后按“生成个人密钥” 。
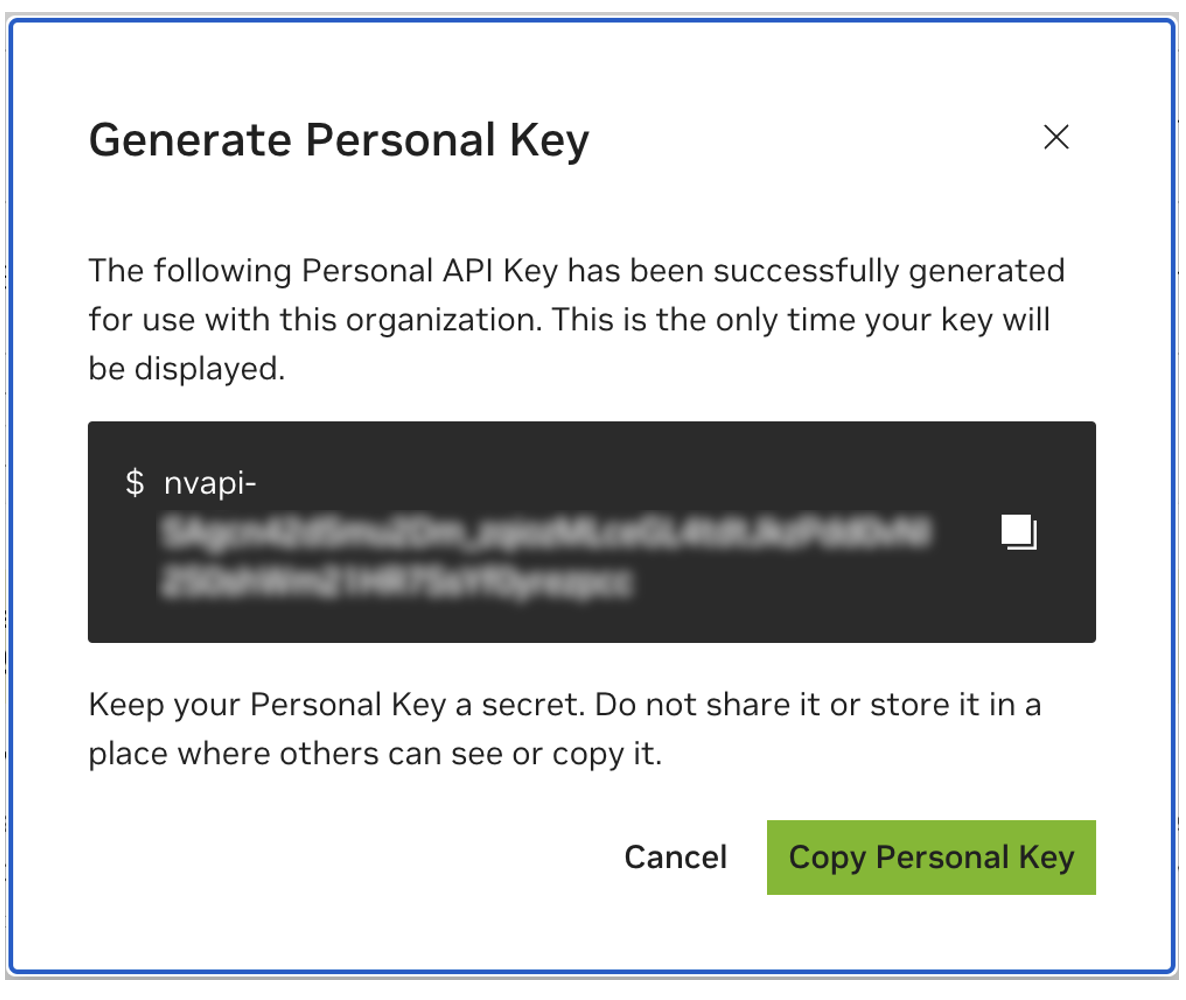
保存您的个人密钥供以后使用。 Workbench 将需要它,并且以后无法检索它。如果密钥丢失,则必须创建一把新密钥。像保护密码一样保护此密钥。
该项目旨在与 NVIDIA AI Workbench 一起使用。虽然这不是必需的,但在没有 AI Workbench 的情况下运行此演示将需要手动工作,因为预配置的自动化和集成可能不可用。
本快速入门指南假设使用远程实验室计算机进行开发,而本地计算机是用于远程访问开发计算机的瘦客户端。这使得计算资源能够保持集中位置,并且使开发人员更加便携。请注意,远程实验室计算机必须运行 Ubuntu,但本地客户端可以运行 Windows、MacOS 或 Ubuntu。要仅在本地安装此项目,只需跳过远程安装即可。
流程图LR
当地的
子图实验室环境
远程实验室机器
结尾
本地 <-.ssh.-> 远程实验室机器
如果本地客户端也用于开发,则需要Ubuntu。使用远程实验室计算机时,可以是 Windows、MacOS 或 Ubuntu。
有关完整说明,请参阅 NVIDIA AI Workbench 用户指南。
安装必备软件
下载 NVIDIA AI Workbench 安装程序并执行它。授权 Windows 允许安装程序进行更改。
按照安装向导中的说明进行操作。如果您需要安装 WSL2,请授权 Windows 进行更改并在请求时重新启动本地计算机。当系统重新启动时,NVIDIA AI Workbench 安装程序应自动恢复。
选择 Docker 作为您的容器运行时。
使用“通过 GitHub.com 登录”选项登录您的 GitHub 帐户。
如果需要,请输入您的 git 作者信息。
有关完整说明,请参阅 NVIDIA AI Workbench 用户指南。
安装必备软件
下载 NVIDIA AI Workbench 磁盘映像( .dmg文件)并打开它。
将 AI Workbench 拖到应用程序文件夹中,然后从应用程序启动器运行NVIDIA AI Workbench 。 
选择 Docker 作为您的容器运行时。
使用“通过 GitHub.com 登录”选项登录您的 GitHub 帐户。
如果需要,请输入您的 git 作者信息。
有关完整说明,请参阅 NVIDIA AI Workbench 用户指南。以将成为 Workbench 用户的用户身份运行此安装。不要以root运行这些步骤。
安装必备软件
下载 NVIDIA AI Workbench 安装程序,使其可执行,然后运行它。您可以使用以下命令使该文件可执行:
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench 将为您安装 NVIDIA 驱动程序(如果需要)。安装驱动程序后,您需要重新启动本地计算机,然后双击桌面上的 NVIDIA AI Workbench 图标重新启动 AI Workbench 安装。
选择 Docker 作为您的容器运行时。
使用“通过 GitHub.com 登录”选项登录您的 GitHub 帐户。
如果需要,请输入您的 git 作者信息。
远程计算机仅支持 Ubuntu。
有关完整说明,请参阅 NVIDIA AI Workbench 用户指南。以将使用 Workbench 的用户身份运行此安装。不要以root运行这些步骤。
确保从本地计算机到远程计算机启用基于 SSH 密钥的身份验证。如果当前未启用此功能,则以下命令将在大多数情况下启用此功能。更改REMOTE_USER和REMOTE-MACHINE以反映您的远程地址。
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINE通过 SSH 连接到远程主机。然后,使用以下命令下载并执行 NVIDIA AI Workbench 安装程序。
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench 将为您安装 NVIDIA 驱动程序(如果需要)。安装驱动程序后,您需要重新启动远程计算机,然后通过重新运行上一步中的命令来重新启动 AI Workbench 安装。
选择 Docker 作为您的容器运行时。
使用“通过 GitHub.com 登录”选项登录您的 GitHub 帐户。
如果需要,请输入您的 git 作者信息。
远程安装完成后,可以将远程位置添加到本地 AI Workbench 实例。打开 AI Workbench 应用程序,单击“添加远程位置” ,然后输入所需信息。完成后,单击“添加位置” 。
REMOTE-MACHINE相同。REMOTE_USER相同。/home/USER/.ssh/id_rsa 。有两种方法可以下载该项目以供本地使用:克隆和分叉。
克隆此存储库是推荐的开始方式。这不允许进行本地修改,但启动速度最快。这也允许以最简单的方式获取更新。
建议分叉此存储库进行开发,因为可以保存更改。然而,为了获取更新,分叉维护者必须定期从上游存储库中提取。要使用分叉进行操作,请按照 GitHub 的说明进行操作,然后在本节的其余部分中引用您的个人分叉的 URL。
打开本地 NVIDIA AI Workbench 窗口。从显示的位置列表中,选择您刚刚设置的远程位置,或者如果您要在本地工作,则选择本地位置。
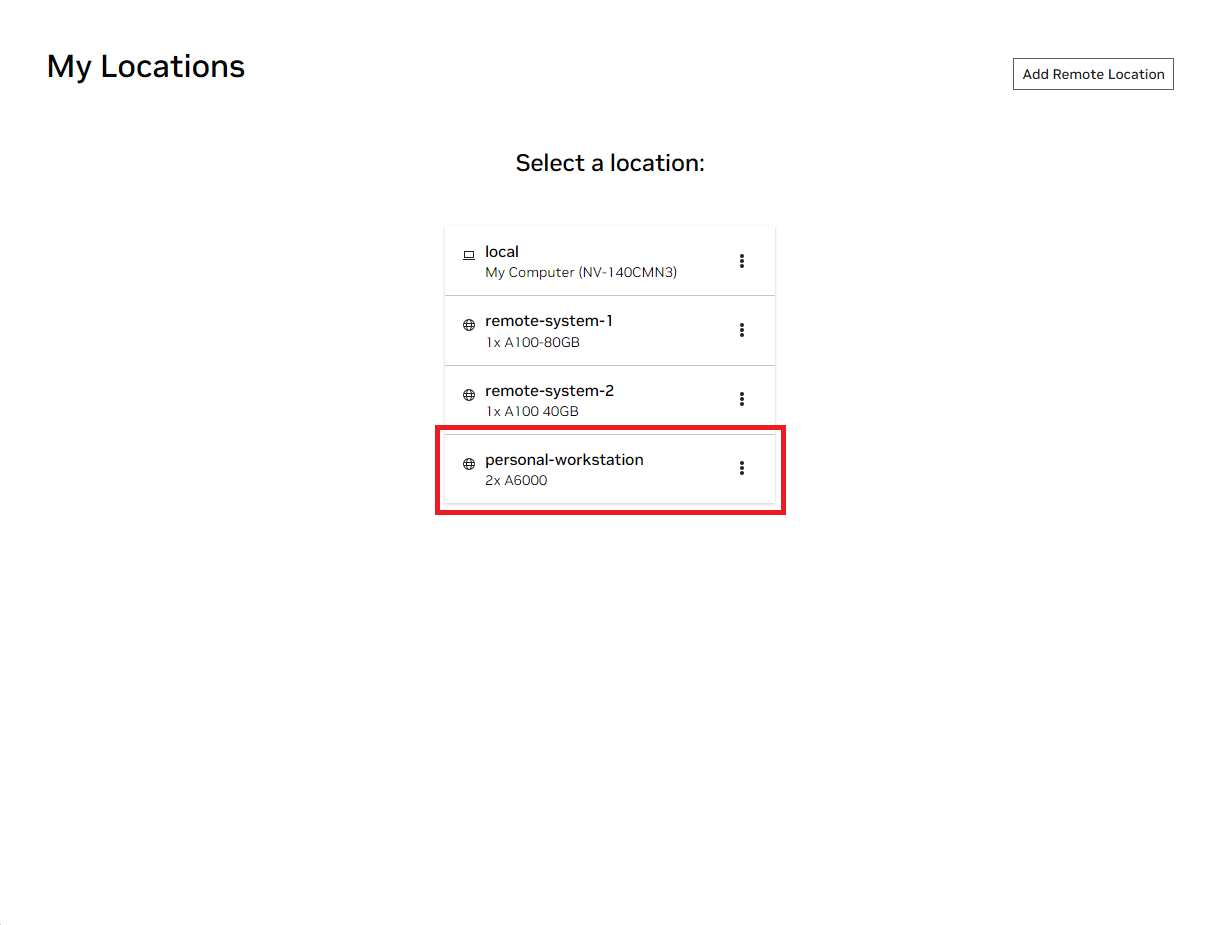
进入该位置后,选择“克隆项目” 。
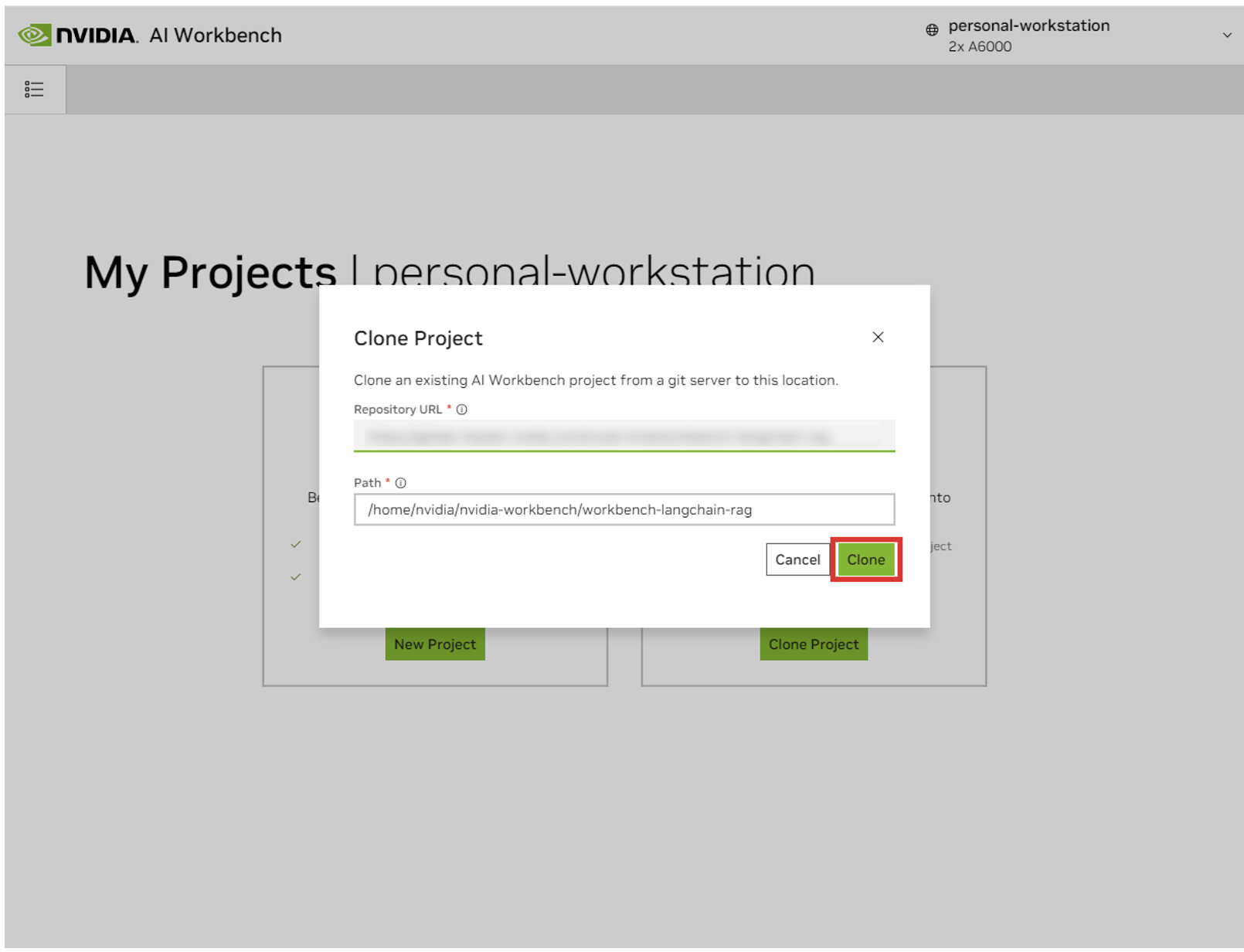
在“克隆项目”弹出窗口中,将存储库 URL 设置为https://github.com/NVIDIA/nim-anywhere.git 。您可以将路径保留为默认值/home/REMOTE_USER/nvidia-workbench/nim-anywhere.git 。单击克隆。`
您将被重定向到新项目的页面。 Workbench 将自动引导开发环境。您可以通过展开窗口底部的输出来查看实时进度。
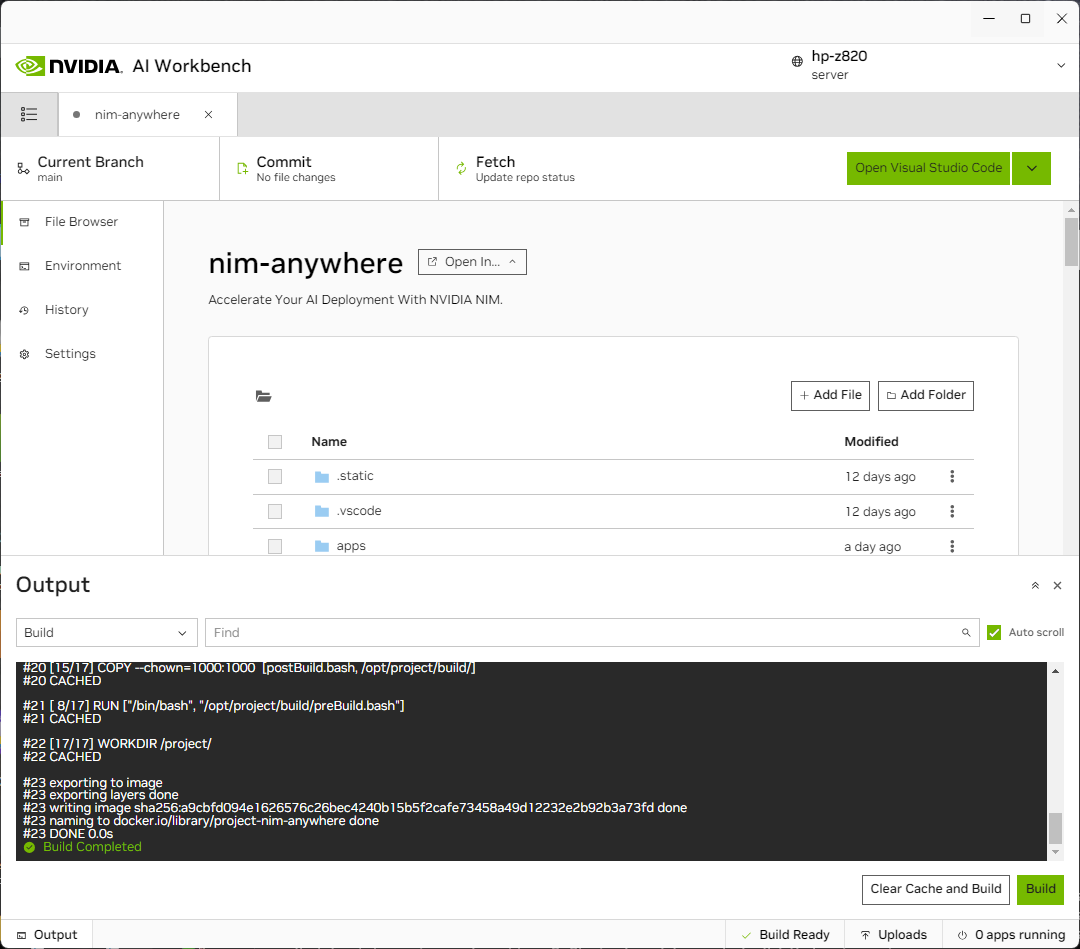
该项目必须配置为使用本地计算机资源。
首次运行之前,必须提供项目特定配置。项目配置是使用左侧面板中的“环境”选项卡完成的。
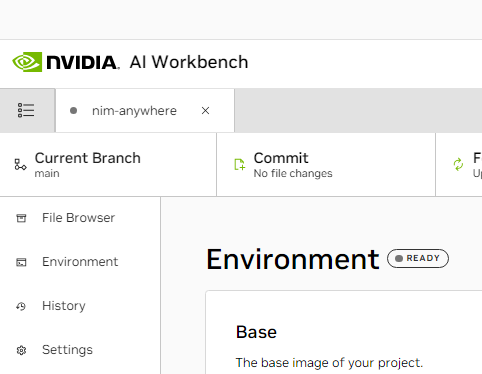
向下滚动到变量部分并找到NGC_HOME条目。它应该设置为类似~/.cache/nvidia-nims 。这里的值由工作台使用。此相同位置也出现在将此目录安装到容器中的Mounts部分中。
向下滚动到Secrets部分并找到NGC_API_KEY条目。按“配置”并提供之前生成的 NGC 个人密钥。
向下滚动到“坐骑”部分。这里,有两个安装座需要配置。
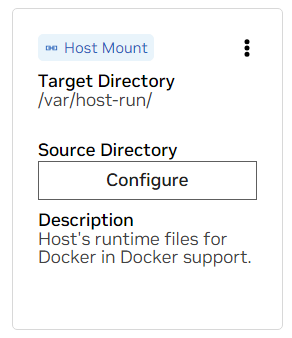
一个。找到 /var/host-run 的挂载点。这用于允许开发环境以称为 Docker out of Docker 的模式访问主机的 Docker 守护进程。按“配置”并提供目录/var/run 。
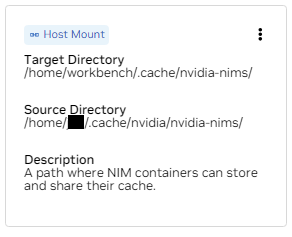
b.找到 /home/workbench/.cache/nvidia-nims 的安装。此挂载用作 NIM 的运行时缓存,它们可以在其中缓存模型文件。与主机共享此缓存可减少磁盘使用量和网络带宽。
如果您还没有 nim 缓存,或者您不确定,请使用以下命令在/home/USER/.cache/nvidia-nims中创建一个。
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nims更改这些设置后将进行重建。
一旦构建完成并显示“构建就绪”消息,所有应用程序都将可供您使用。
即使是最基本的 LLM 链也依赖于一些额外的微服务。在内存替代方案的开发过程中可以忽略这些,但随后需要更改代码才能投入生产。值得庆幸的是,Workbench 为开发环境管理这些额外的微服务。
提示:对于每个应用程序,可以通过单击左下角的“输出”链接,选择下拉菜单,然后选择感兴趣的应用程序,在 UI 中监视调试输出。
可以通过导航到环境>应用程序来控制此工作区中捆绑的所有应用程序。
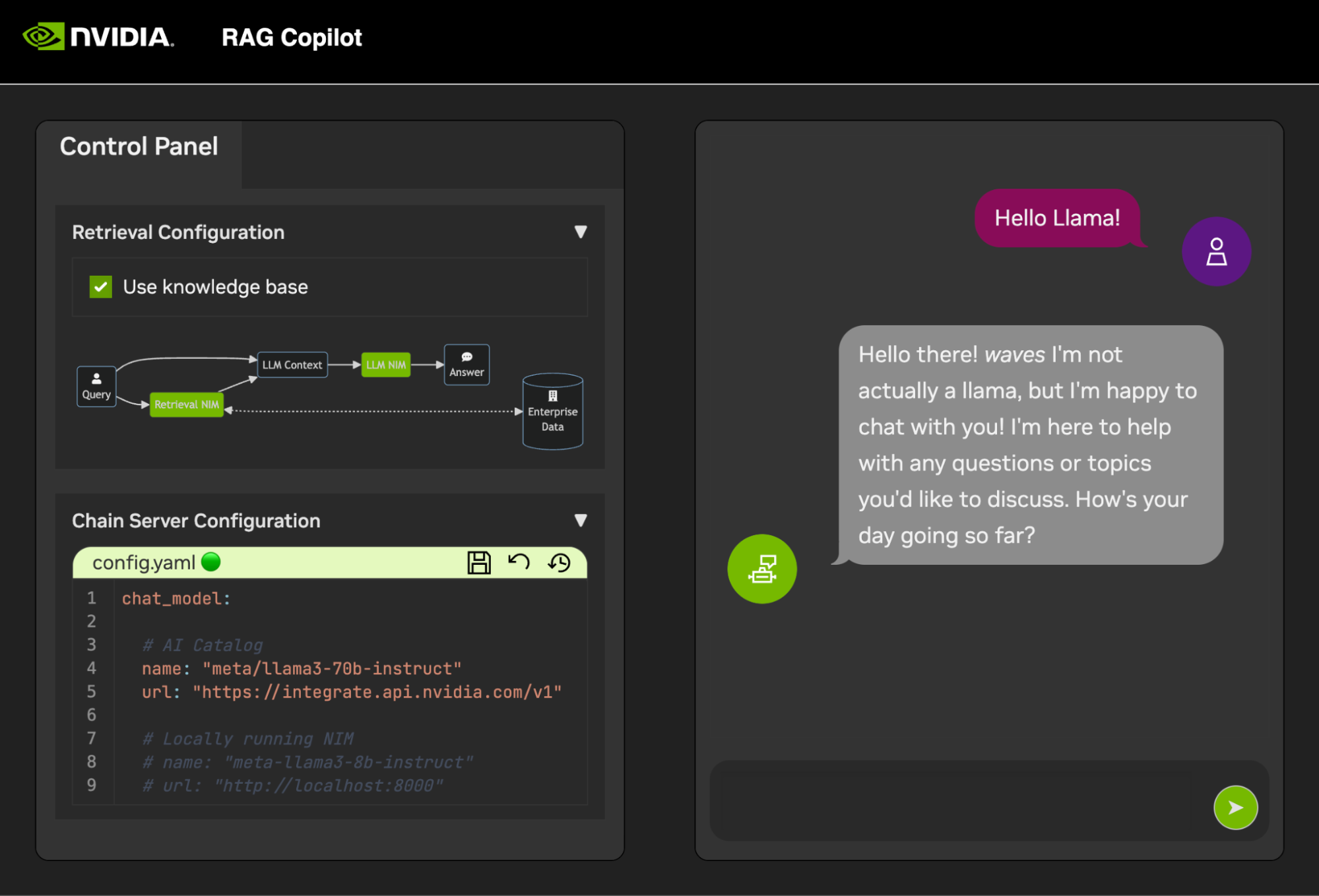
首先,打开Milvus Vector DB和Redis 。 Milvus 用作非结构化知识库,Redis 用来存储对话历史。
一旦这些服务启动, Chain Server就可以安全启动。其中包含用于执行推理链的自定义 LangChain 代码。默认情况下,它将使用本地 Milvus 和 Redis,但使用ai.nvidia.com进行 LLM 和 Embedding 模型推理。
[可选]:接下来,启动LLM NIM 。第一次启动LLM NIM时,需要一些时间来下载镜像和优化模型。
一个。在长时间启动期间,为了确认 LLM NIM 正在启动,可以使用 UI 左下角的“输出”窗格查看日志来观察进度。
b.如果日志指示身份验证错误,则意味着提供的NGC_API_KEY无权访问 NIM。请验证它是否正确生成,并且是在拥有 NVIDIA AI Enterprise 支持或试用的 NGC 组织中生成的。
c.如果日志似乎卡在..........: Pull complete 。 ..........: Verifying complete ,或..........: Download complete ;这是 Docker 的所有正常输出,表明容器映像的各个层已下载。
d.这里的任何其他故障都需要解决。
一旦Chain Server启动,聊天界面就可以启动。启动界面将自动在浏览器窗口中打开它。
为了开始开发演示,我们提供了一个示例数据集以及一个 Jupyter Notebook,展示了如何将数据引入矢量数据库。
要将 PDF 文档导入矢量数据库,请使用 AI Workbench 中的应用程序启动器打开 Jupyter。
使用code/upload-pdfs.ipynb处的 Jupyter Notebook 获取默认数据集。如果使用默认数据集,则无需进行任何更改。
如果使用自定义数据集,请将其上传到 Jupyter 中的data/目录,并根据需要修改提供的笔记本。
该项目包含一些演示服务的应用程序以及与外部服务的集成。这些都是由 NVIDIA AI Workbench 精心策划的。
演示服务都在code文件夹中。代码文件夹的根级别有一些用于技术深入研究的交互式笔记本。 Chain Server 是一个将 NIM 与 LangChain 结合使用的示例应用程序。 (请注意,此处的 Chain Server 为您提供了使用或不使用 RAG 进行试验的选项)。 Chat Frontend 文件夹包含一个用于运行链服务器的交互式 UI 服务器。最后,评估目录中提供了示例笔记本来演示检索评分和验证。
思维导图
根((AI工作台))
演示服务
链服务器<br />LangChain + NIM
前端<br />交互式演示 UI
评估<br />验证结果
笔记本<br />高级用法
集成
Redis</br>对话历史记录
Milvus</br>矢量数据库
LLM NIM优化的LLM
Chain Server 可以使用配置文件或环境变量进行配置。
默认情况下,应用程序将在以下所有位置搜索配置文件。如果找到多个配置文件,则列表中较低文件中的值将优先。
可以通过名为APP_CONFIG的环境变量指定附加配置文件路径。该文件中的值将优先于所有默认文件位置。
export APP_CONFIG=/etc/my_config.yaml还可以使用环境变量来设置配置。变量名称的格式为: APP_FIELD__SUB_FIELD指定为环境变量的值将优先于文件中的所有值。
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
聊天前端也有一些配置选项。它们可以按照与链服务器相同的方式设置。
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
欢迎对此项目的所有反馈和贡献。当对此项目进行更改时,无论是为了个人使用还是为了贡献,建议在该项目上进行分叉。一旦在分叉上完成更改,就应该打开合并请求。
该项目已配置了 Linters,这些 Linters 已进行了调整,以帮助代码保持一致,同时又不会过于繁重。我们使用以下 Linters:
嵌入式 VSCode 环境配置为实时运行 linting 和检查。
要手动运行 CI 管道完成的 linting,请执行/project/code/tools/lint.sh 。可以通过名称指定它们来运行单独的测试: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] 。在修复模式下运行 lint 工具将通过运行 Black、更新 README 并清除所有 Jupyter Notebook 上的单元格输出来自动纠正它可以纠正的问题。
前端的设计旨在最大限度地减少所需的 HTML 和 Javascript 开发。提供了一个带有品牌和样式的应用程序外壳,它是使用普通 HTML、Javascript 和 CSS 创建的。它被设计为易于定制,但永远不应该是必需的。前端的交互组件都是在 Gradio 中创建的,并使用 iframe 安装在应用程序 shell 中。
应用程序外壳顶部是一个列出可用视图的菜单。每个视图可能有自己的布局,由一页或几页组成。
页面包含演示的交互式组件。页面的代码位于code/frontend/pages目录中。要创建新页面:
__init__.py文件,使用 Gradio 定义 UI。渐变块布局应在名为page变量中定义。chat页面的示例。code/frontend/pages/__init__.py文件,导入新页面,并将新页面添加到__all__列表中。注意:创建新页面不会将其添加到前端。必须将其添加到视图中才能显示在前端上。
视图由一页或几页组成,并且应彼此独立运行。视图全部在code/frontend/server.py模块中定义。所有声明的视图将自动添加到前端的菜单栏并在 UI 中可用。
要定义新视图,请修改名为views的列表。这是View对象的列表。对象的顺序将定义它们在前端菜单中的顺序。第一个定义的视图将是默认视图。
视图对象描述视图名称和布局。它们可以声明如下:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
)所有页面声明View.left或View.right都是可选的。如果未声明它们,则 Web 布局中关联的 iframe 将被隐藏。其他 iframe 将扩展以填补空白。下图显示了各种布局。
区块贝塔
第 1 栏
菜单[“菜单栏”]
堵塞
第 2 栏
左 右
结尾
区块贝塔
第 1 栏
菜单[“菜单栏”]
堵塞
第 1 栏
左:1
结尾
前端包含一些可以针对不同用例进行定制的品牌资产。
前端在页面左上角包含一个徽标。要修改徽标,需要所需徽标的 SVG。然后可以通过修改code/frontend/_assets/index.html文件轻松修改应用程序外壳以使用新的 SVG。有一个 ID 为logo的div 。该框包含一个 SVG。将此更新为所需的 SVG 定义。
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > App Shell 的样式在code/frontend/_static/css/style.css中定义。可以安全地修改此文件中的颜色。
各个页面的样式在code/frontend/pages/*/*.css中定义。这些文件可能还需要修改自定义配色方案。
Gradio 主题在文件code/frontend/_assets/theme.json中定义。该文件中的颜色可以安全地修改为所需的品牌。此文件中的其他样式也可能会更改,但可能会导致前端发生重大更改。 Gradio 文档包含有关 Gradio 主题的更多信息。
注意:这是大多数开发人员永远不需要的高级主题。
有时,可能需要在视图中包含多个相互通信的页面。为此,使用了 Javascript 的postMessage消息传递框架。发布到应用程序 shell 的任何可信消息都将转发到每个 iframe,其中页面可以根据需要处理该消息。 control页面使用此功能来修改chat页面的配置。
以下内容将向应用程序 shell ( window.top ) 发布一条消息。该消息将包含一个字典,其键为use_kb且值为 true。使用 Gradio,该 Javascript 可以由任何 Gradio 事件执行。
window . top . postMessage ( { "use_kb" : true } , '*' ) ;该消息将自动由应用程序外壳发送到所有页面。以下示例代码将在另一个页面上使用该消息。当收到message事件时,此代码将异步运行。如果消息可信, elem_id为use_kb的 Gradio 组件将更新为消息中指定的值。这样,Gradio 组件的值就可以跨页面复制。
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; 自述文件会自动呈现;直接编辑将被覆盖。为了修改自述文件,您需要分别编辑每个部分的文件。所有这些文件将被合并并自动生成自述文件。您可以在docs文件夹中找到所有相关文件。
文档以 Github Flavored Markdown 编写,然后由 Pandoc 呈现为最终 Markdown 文件。此过程的详细信息在 Makefile 中定义。生成的文件的顺序在docs/_TOC.md中定义。可以在 Workbench 文件浏览器窗口中预览文档。
头文件是用于编译文档的第一个文件。该文件可以在docs/_HEADER.md找到。该文件的内容将在没有任何操作的情况下逐字写入自述文件中,然后再进行其他操作。
摘要文件包含描述该项目的快速描述和图形。该文件的内容将添加到自述文件中,紧接在标题之后、目录之前。该文件由 Pandoc 处理以在写入 README 之前嵌入图像。
该文档最重要的文件是docs/_TOC.md中的目录文件。该文件定义了应连接以生成最终自述文件手册的文件列表。文件必须在此列表中才能包含在内。
将所有静态内容(包括图像)保存到_static文件夹。这将有助于组织。
拥有能够自行更新和编写的文档可能会有所帮助。要创建动态文档,只需创建一个将 Markdown 格式文档写入 stdout 的可执行文件即可。在构建期间,如果目录文件中的条目是可执行的,则该条目将被执行,并且其标准输出将在其位置使用。
当推送与文档相关的提交时,GitHub Action 将呈现文档。对自述文件的任何更改都将自动提交。
开发环境的大部分配置都是通过环境变量进行的。要对环境变量进行永久更改,请修改variables.env或使用Workbench UI。
该项目使用/usr/bin/python3中的一个 Python 环境,并使用pip管理依赖项。由于所有开发都是在容器内完成的,因此对 Python 环境的任何更改都将是短暂的。要永久安装 Python 包,请将其添加到requirements.txt文件或使用Workbench UI。
开发环境基于Ubuntu 22.04。主用户具有无密码 sudo 访问权限,但对系统的所有更改都将是短暂的。要对已安装的软件包进行永久更改,请将它们添加到 [ apt.txt ] 文件中。对操作系统进行其他更改,例如操作文件、添加环境变量等;使用postBuild.bash和preBuild.bash文件。
通常最好每月更新依赖项,以确保不会因滥用依赖项而暴露 CVE。以下过程可用于修补该项目。建议在补丁后运行回归测试,以确保更新中没有任何问题。
/project/code/tools/bump.sh脚本自动更新 Python 依赖项和 NIM 应用程序。/project/code/tools/audit.sh 。该脚本将打印出所有处于警告状态的 Python 包和所有处于错误状态的包的报告。任何处于错误状态的内容都必须得到解决,因为它将具有活动的 CVE 和已知漏洞。

