cambrian
1.0.0
有趣的事实:动物在寒武纪时期就出现了视觉!这就是我们项目名称寒武纪的灵感来源。
eval/子文件夹。dataengine/子文件夹。目前,我们支持使用 TorchXLA 对 TPU 进行训练
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " 这是我们的寒武纪检查点以及如何使用权重的说明。我们的模型在 8B、13B 和 34B 参数级别的各个维度上都表现出色。与 GPT-4V、Gemini-Pro 和 Grok-1.4V 等闭源专有模型相比,它们在多个基准测试中表现出具有竞争力的性能。
| 模型 | # 可见。托克。 | MMB | SQA-I | 数学维斯塔M | 图表质量保证 | 综合MVP |
|---|---|---|---|---|---|---|
| GPT-4V | 恩克 | 75.8 | - | 49.9 | 78.5 | 50.0 |
| Gemini-1.0 专业版 | 恩克 | 73.6 | - | 45.2 | - | - |
| Gemini-1.5 Pro | 恩克 | - | - | 52.1 | 81.3 | - |
| 格罗克-1.5 | 恩克 | - | - | 52.8 | 76.1 | - |
| MM-1-8B | 144 | 72.3 | 72.6 | 35.9 | - | - |
| MM-1-30B | 144 | 75.1 | 81.0 | 39.4 | - | - |
| 基础法学硕士:Phi-3-3.8B | ||||||
| 寒武纪1-8B | 第576章 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| 基础法学硕士:LLaMA3-8B-指导 | ||||||
| 迷你双子座-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| 寒武纪1-8B | 第576章 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| 基础法学硕士:Vicuna1.5-13B | ||||||
| 迷你双子座-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| 寒武纪1-13B | 第576章 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| 基础法学硕士:Hermes2-Yi-34B | ||||||
| 迷你双子座-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| 寒武纪-1-34B | 第576章 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
如需完整表格,请参阅我们的 Cambrian-1 论文。
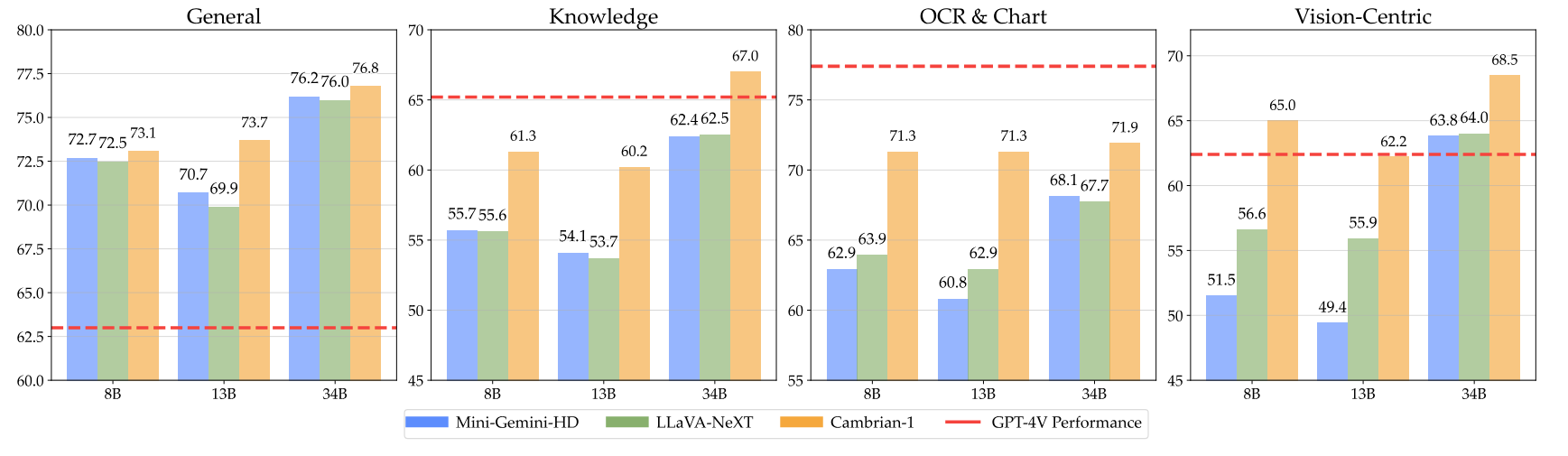
我们的模型在使用较少的固定数量的视觉标记的同时提供了极具竞争力的性能。
要使用模型权重,请从 Hugging Face 下载它们:
我们在inference.py中提供了示例模型加载和生成脚本。

在这项工作中,我们收集了一个非常大的指令调优数据池 Cambrian-10M,供我们和未来研究训练 MLLM 的数据。在我们的初步研究中,我们将数据过滤为一组高质量的 7M 精选数据点,我们将其称为 Cambrian-7M。这两个数据集都可以在以下 Hugging Face 数据集中找到:Cambrian-10M。
我们从各种来源收集了各种视觉指令调整数据,包括 VQA、视觉对话和具体视觉交互。为了保证高质量、可靠、大规模的知识数据,我们设计了互联网数据引擎。
此外,我们观察到 VQA 数据往往会生成非常短的输出,从而导致训练数据发生分布变化。为了解决这个问题,我们利用 GPT-4v 和 GPT-4o 来创建扩展响应和更具创意的数据。
为了解决科学相关数据的不足,我们设计了一个互联网数据引擎来收集可靠的科学相关VQA数据。该引擎可用于收集任何主题的数据。使用该引擎,我们额外收集了 161k 个与科学相关的视觉指令调整数据点,使该领域的总数据增加了 400%!如果你想使用这部分数据,请使用这个jsonl。
我们使用 GPT-4v 创建了额外的 77k 数据点。该数据要么使用 GPT-4v 将原始的仅答案 VQA 重写为具有更详细响应的更长答案,要么根据给定图像生成视觉指令调整数据。如果你想使用这部分数据,请使用这个jsonl。
我们使用 GPT-4o 创建了额外的 60k 创意数据点。这些数据鼓励模型生成很长的响应,并且通常包含高度创造性的问题,例如写一首诗、创作一首歌曲等等。如果你想使用这部分数据,请使用这个jsonl。
我们通过以下方式对数据管理进行了初步研究:
根据经验,我们发现设置
| 类别 | 数据比率 |
|---|---|
| 语言 | 21.00% |
| 一般的 | 34.52% |
| 光学字符识别 | 27.22% |
| 计数 | 8.71% |
| 数学 | 7.20% |
| 代码 | 0.87% |
| 科学 | 0.88% |
与之前的 LLaVA-665K 模型相比,扩展和改进的数据管理显着提高了模型性能,如下表所示:
| 模型 | 平均的 | 常识 | 光学字符识别 | 图表 | 以视觉为中心 |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| 寒武纪10M | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| 寒武纪7M | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
虽然使用 Cambrian-7M 进行训练可提供具有竞争力的基准结果,但我们观察到该模型往往会输出较短的响应,并且表现得像问答机。这种行为,我们称之为“应答机”现象,可能会限制模型在更复杂的交互中的有用性。
我们发现添加了一个系统提示,例如“使用单个单词或短语回答问题”。可以帮助缓解这个问题。这种方法鼓励模型仅在上下文适当时才提供如此简洁的答案。欲了解更多详细信息,请参阅我们的论文。
我们还策划了一个带有系统提示的数据集Cambrian-7M,其中包括增强模型创造力和聊天能力的系统提示。
以下是Cambrian-1的最新训练配置。
在 Cambrian-1 论文中,我们进行了广泛的研究来证明两阶段训练的必要性。 Cambrian-1 训练分为两个阶段:
Cambrian-1 在 TPU-V4-512 上进行训练,但也可以在从 TPU-V4-64 开始的 TPU 上进行训练。 GPU训练代码即将发布。对于较少 GPU 上的 GPU 训练,请减少per_device_train_batch_size并相应地增加gradient_accumulation_steps ,确保全局批量大小保持不变: per_device_train_batch_size gradient_accumulation_steps x num_gpus 。
下面提供了预训练和微调中使用的两个超参数。
| 基础法学硕士 | 全局批量大小 | 学习率 | SVA学习率 | 纪元 | 最大长度 |
|---|---|---|---|---|---|
| 拉玛-3 8B | 第512章 | 1e-3 | 1e-4 | 1 | 2048 |
| 骆驼毛-1.5 13B | 第512章 | 1e-3 | 1e-4 | 1 | 2048 |
| 爱马仕Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| 基础法学硕士 | 全局批量大小 | 学习率 | 纪元 | 最大长度 |
|---|---|---|---|---|
| 拉玛-3 8B | 第512章 | 4e-5 | 1 | 2048 |
| 骆驼毛-1.5 13B | 第512章 | 4e-5 | 1 | 2048 |
| 爱马仕Yi-34B | 1024 | 2e-5 | 1 | 2048 |
对于指令微调,我们进行了实验来确定模型训练的最佳学习率。根据我们的发现,我们建议使用以下公式根据您的设备的可用性调整您的学习率:
optimal lr = base_lr * sqrt(bs / base_bs)
要获得基础 LLM 并训练 8B、13B 和 34B 模型:
我们使用 LLaVA、ShareGPT4V、Mini-Gemini 和 ALLaVA 对齐数据的组合来预训练我们的视觉连接器 (SVA)。在 Cambrian-1 中,我们进行了广泛的研究来证明使用额外对齐数据的必要性和好处。
首先,请访问我们的拥抱面部对齐数据页面了解更多详细信息。您可以从以下链接下载对齐数据:
我们在以下位置提供示例培训脚本:
如果您希望使用其他数据源或自定义数据进行训练,我们支持常用的 LLaVA 数据格式。为了处理非常大的文件,我们使用 JSONL 格式而不是 JSON 格式来延迟数据加载,以优化内存使用。
与训练 SVA 类似,请访问我们的 Cambrian-10M 数据以获取有关指令调优数据的更多详细信息。
我们在以下位置提供示例培训脚本:
--mm_projector_type :要使用我们的 SVA 模块,请将此值设置为sva 。要使用 LLaVA 样式 2 层 MLP 投影仪,请将此值设置为mlp2x_gelu 。--vision_tower_aux_list :要使用的视觉模型列表(例如'["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' )。--vision_tower_aux_token_len_list :每个愿景塔的愿景令牌数量列表;每个数字应该是一个平方数(例如'[576, 576, 576, 9216]' )。每个视觉塔的特征图将被插值以满足这个要求。--image_token_len :将提供给LLM的视觉令牌的最终数量;该数字应该是平方数(例如576 )。请注意,如果mm_projector_type为 mlp,则vision_tower_aux_token_len_list中的每个数字必须与image_token_len相同。以下参数仅对 SVA 投影机有意义--num_query_group :SVA 模块的G值。--query_num_list :SVA 中每组查询的查询编号列表(例如'[576]' )。列表的长度应等于num_query_group 。--connector_depth :SVA 模块的D值。--vision_hidden_size :SVA 模块的隐藏大小。--connector_only :如果为true,SVA模块只会出现在LLM之前,否则会在LLM内部多次插入。以下三个参数仅在设置为False时才有意义。--num_of_vision_sampler_layers :LLM 中插入的 SVA 模块总数。--start_of_vision_sampler_layers :LLM 层索引,之后开始插入 SVA。--stride_of_vision_sampler_layers :LLM 内 SVA 模块插入的步幅。 我们已在eval/子文件夹中发布了评估代码。请参阅那里的自述文件以了解更多详细信息。
以下说明将指导您使用 Cambrian 启动本地 Gradio 演示。我们提供了一个简单的 Web 界面供您与模型交互。您还可以使用 CLI 进行推理。这个设置很大程度上受到 LLaVA 的启发。
请按照以下步骤启动本地 Gradio 演示。本地服务代码图如下1 。
%%{init: {"主题": "基础"}}%%
流程图BT
%% 声明节点
样式 gws 填充:#f9f,描边:#333,描边宽度:2px
样式 c 填充:#bbf,描边:#333,描边宽度:2px
样式 mw8b 填充:#aff,描边:#333,描边宽度:2px
样式 mw13b 填充:#aff,描边:#333,描边宽度:2px
%% 样式 sglw13b 填充:#ffa,描边:#333,描边宽度:2px
%% 样式 lsglw13b 填充:#ffa,描边:#333,描边宽度:2px
gws["Gradio(UI 服务器)"]
c["控制器(API 服务器):<br/>端口:10000"]
mw8b["劳模:<br/><b>Cambrian-1-8B</b><br/>端口:40000"]
mw13b["劳模:<br/><b>Cambrian-1-13B</b><br/>端口:40001"]
%% sglw13b["SGLang 后端:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["SGLang 工作线程:<br/><b>Cambrian-1-34B<b><br/>端口:40002"]
子图“演示架构”
方向BT
c <--> GWS
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
结尾
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload您刚刚启动了 Gradio Web 界面。现在,您可以打开 Web 界面,并将 URL 打印在屏幕上。您可能会注意到模型列表中没有模型。别担心,我们还没有推出任何劳模。当您启动模型工作人员时,它将自动更新。
即将推出。
这是在 GPU 上执行推理的实际工作程序。每个工作人员负责--model-path中指定的单个模型。
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8b等到进程完成加载模型,您会看到“Uvicorn running on ...”。现在,刷新您的 Gradio Web UI,您将在模型列表中看到刚刚启动的模型。
您可以根据需要启动任意数量的工作程序,并在同一 Gradio 界面中比较不同模型检查点。请保持--controller相同,并将--port和--worker修改为每个worker的不同端口号。
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2>如果您使用的是带有 M1 或 M2 芯片的 Apple 设备,则可以使用--device标志指定 mps 设备: --device mps 。
如果您的 GPU 的 VRAM 小于 24GB(例如 RTX 3090、RTX 4090 等),您可以尝试使用多个 GPU 运行它。如果您有多个 GPU,我们最新的代码库将自动尝试使用多个 GPU。您可以通过CUDA_VISIBLE_DEVICES指定要使用的 GPU。下面是使用前两个 GPU 运行的示例。
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8b待办事项
如果您发现 Cambrian 对您的研究和应用有用,请使用此 BibTeX 进行引用:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
使用和许可声明:该项目使用某些数据集和检查点,这些数据集和检查点受各自原始许可的约束。用户必须遵守这些原始许可证的所有条款和条件,包括但不限于数据集的 OpenAI 使用条款以及使用数据集训练的检查点的基本语言模型的特定许可证(例如 Llama-3 的 Llama 社区许可证,和骆驼毛-1.5)。除了原始许可证中规定的限制外,该项目没有施加任何额外的限制。此外,提醒用户确保他们对数据集和检查点的使用符合所有适用的法律和法规。
复制自 LLaVA 的图表。 ↩


