Facebook Messenger Bot
1.0.0
我训练的 FB Messenger 聊天机器人可以像我一样说话。相关的博客文章。
对于这个项目,我想根据我过去来自各个社交媒体网站的对话日志训练一个序列到序列模型。您可以在博客文章中详细了解此方法背后的动机、ML 模型的详细信息以及每个 Python 脚本的用途,但我想使用此自述文件来解释如何训练自己的聊天机器人像您一样说话。
为了运行这些脚本,您将需要以下库。
以交互方式或在终端中输入以下内容,从 GitHub 下载并解压整个存储库。
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.git导航到计算机上存储库的顶级目录
cd Facebook-Messenger-Bot我们的第一项工作是从各种社交媒体网站下载您的所有对话数据。对我来说,我使用 Facebook、Google Hangouts 和 LinkedIn。如果您有其他网站可以从中获取数据,那也没有问题。您只需在 createDataset.py 中创建一个新方法。
Facebook 数据:从此处下载您的数据。下载后,您应该有一个相当大的文件,名为messages.htm 。这将是一个相当大的文件(对我来说超过 190 MB)。我们需要解析这个大文件,并提取所有对话。为此,我们将使用 Dillon Dixon 善意开源的这个工具。您将继续通过运行来安装该工具
pip install fbchat-archive-parser然后运行:
fbcap ./messages.htm > fbMessages.txt这将为您提供一个相当统一的文本文件中的所有 Facebook 对话。谢谢狄龙!继续,然后将该文件存储在您的 Facebook-Messenger-Bot 文件夹中。
LinkedIn 数据:从此处下载您的数据。下载后,您应该会看到一个inbox.csv文件。我们不需要在这里执行任何其他步骤,我们只需将其复制到我们的文件夹中即可。
Google Hangouts 数据:在此处下载您的数据表。下载后,您将获得一个我们需要解析的 JSON 文件。为此,我们将使用通过这篇精彩博客文章找到的解析器。我们希望将数据保存到文本文件中,然后将该文件夹复制到我们的文件夹中。
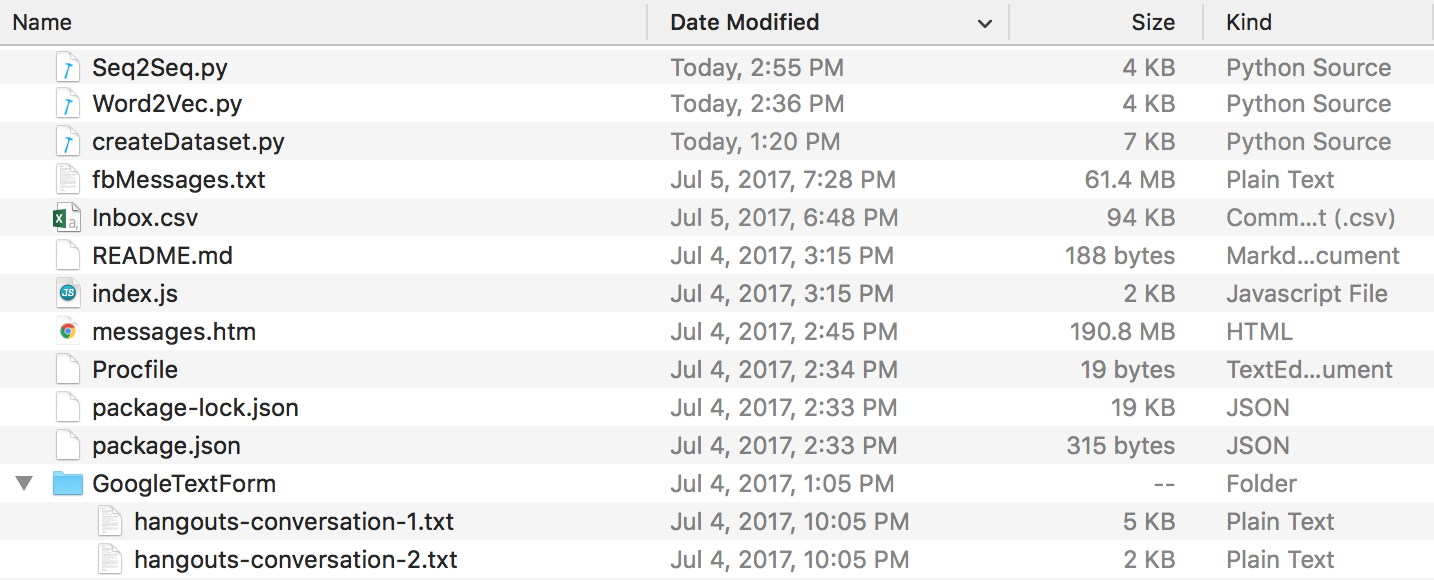
最后,您应该有一个如下所示的目录结构。如果文件夹和文件名不同,请确保重命名。
Discord 数据:您可以使用 Tyrrrz 制作的这款很棒的 DiscordChatExporter 提取您的 Discord 聊天日志。按照其文档以.txt格式提取所需的单一聊天日志(这很重要)。然后,您可以将它们全部放入存储库目录中名为DiscordChatLogs的文件夹中。
WhatsApp 数据:确保您有手机,如果还没有,请将其设置为美国日期格式(稍后当您将日志文件解析为 .csv 时,这一点很重要)。您不能使用 WhatsApp 网络来实现此目的。打开要发送的聊天,点击菜单按钮,点击“更多”,然后点击“通过电子邮件发送聊天”。将电子邮件发送给您自己并将其下载到您的计算机。这将为您提供一个 .txt 文件,为了解析它,我们将其转换为 .csv。为此,请转到此链接并输入日志文件中的所有文本。单击“导出”,下载 csv 文件,然后将其存储在名称为“whatsapp_chats.csv”的 Facebook-Messenger-Bot 文件夹中。
注意:上面链接中提供的解析器似乎已被删除。如果您仍有格式正确的.csv文件,您仍可以使用该文件。否则,将您的 Whatsapp 聊天日志下载为.txt文件,并将它们全部放入存储库目录中名为WhatsAppChatLogs的文件夹中。当且仅当它找不到名为whatsapp_chats.csv的.csv文件时, createDataset.py才会使用这些文件。
如果您使用.txt聊天日志,请注意预期格式是-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(或者)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
现在我们所有的对话日志都是干净的格式,我们可以继续创建我们的数据集。在我们的目录中,运行:
python createDataset.py然后,系统会提示您输入您的姓名(以便脚本知道要查找的人)以及您拥有哪些社交媒体网站的数据。该脚本将创建一个名为conversationDictionary.npy的文件,它是一个Numpy对象,其中包含(FRIENDS_MESSAGE,YOUR RESPONSE)形式的对。还将创建一个名为conversationData.txt的文件。这只是一个大文本文件,将字典数据统一为形式。
现在我们有了这 2 个文件,我们可以开始通过 Word2Vec 模型创建词向量。这一步与其他步骤略有不同。我们稍后看到的 Tensorflow 函数(在 seq2seq.py 中)实际上也处理嵌入部分。因此,您可以决定训练自己的向量,也可以让 seq2seq 函数联合执行,这就是我最终所做的。如果您想通过 Word2Vec 创建自己的词向量,请在提示符下输入 y(运行以下命令后)。如果你不这样做,那也没关系,回复n,这个函数只会创建wordList.txt。
python Word2Vec.py如果完整运行 word2vec.py,这将创建 4 个不同的文件。 Word2VecXTrain.npy和Word2VecYTrain.npy是 Word2Vec 将使用的训练矩阵。我们将它们保存在文件夹中,以防我们需要使用不同的超参数再次训练 Word2Vec 模型。我们还保存wordList.txt ,它只包含我们语料库中的所有唯一单词。最后保存的文件是embeddingMatrix.npy ,它是一个 Numpy 矩阵,包含所有生成的单词向量。
现在,我们可以使用创建和训练我们的 Seq2Seq 模型。
python Seq2Seq.py这将创建 3 个或更多不同的文件。 Seq2SeqXTrain.npy和Seq2SeqYTrain.npy是 Seq2Seq 将使用的训练矩阵。同样,我们保存这些以防万一我们想要更改我们的模型架构,并且我们不想重新计算我们的训练集。最后一个文件将是 .ckpt 文件,其中保存了我们保存的 Seq2Seq 模型。模型将在训练循环的不同时间段保存。一旦我们创建了聊天机器人,就会使用和部署这些。
现在我们已经保存了模型,现在让我们创建 Facebook 聊天机器人。为此,我建议遵循本教程。您无需阅读“自定义机器人所说的内容”部分下方的任何内容。我们的 Seq2Seq 模型将处理该部分。重要信息 - 本教程将告诉您在 Node 项目所在的位置创建一个新文件夹。请记住,此文件夹将与我们的文件夹不同。您可以将此文件夹视为我们的数据预处理和模型训练所在的位置,而另一个文件夹严格保留给 Express 应用程序(编辑:我相信您可以按照我们文件夹内的教程步骤操作,只需创建 Node 项目,如果需要的话,Procfile 和 index.js 文件都在此处)。教程本身应该足够了,但这里是步骤的摘要。
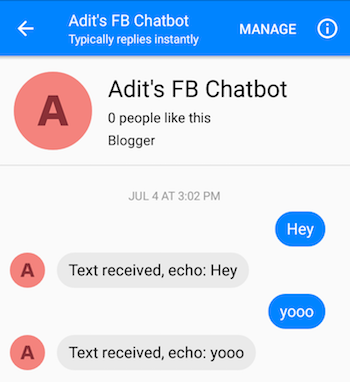
正确执行步骤后,您应该能够向聊天机器人发送消息并获得回复。
啊,你快完成了!现在,我们必须创建一个 Flask 服务器,可以在其中部署保存的 Seq2Seq 模型。我这里有该服务器的代码。我们来谈谈总体结构。 Flask 服务器通常有一个主 .py 文件,您可以在其中定义所有端点。在我们的例子中,这将是 app.py。这将是我们在模型中加载的位置。您应该创建一个名为“models”的文件夹,并在其中填充 4 个文件(一个检查点文件、一个数据文件、一个索引文件和一个元文件)。这些是保存 Tensorflow 模型时创建的文件。

在此 app.py 文件中,我们想要创建一条路线(在我的例子中为 /prediction),其中路线的输入将被输入到我们保存的模型中,解码器输出是返回的字符串。如果仍然有点令人困惑,请继续仔细查看 app.py。现在您已经有了 app.py 和模型(以及其他帮助文件,如果需要的话),您可以部署服务器了。我们将再次使用 Heroku。有很多关于将 Flask 服务器部署到 Heroku 的不同教程,但我特别喜欢这个(不需要 Foreman 和 Logging 部分)。
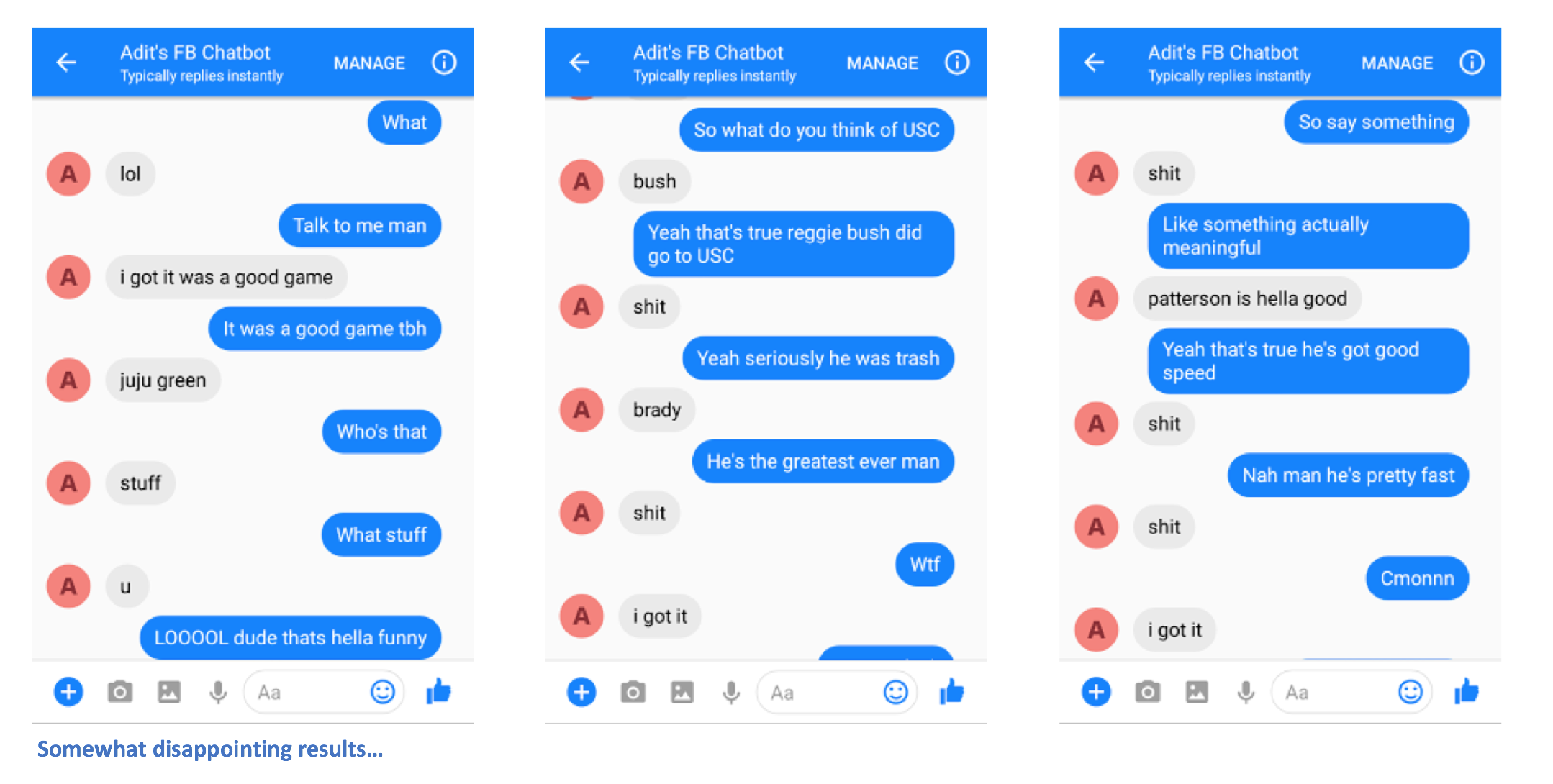
就这样吧。您应该能够向聊天机器人发送消息,并看到一些有趣的响应(希望)在某种程度上与您自己相似。
如果您有任何问题或有任何改进本自述文件的建议,请告诉我。如果您认为某个步骤不清楚,请告诉我,我会尽力编辑自述文件并进行澄清。


